
Two years ago, “AI” meant typing a prompt and getting text back. Today the same model might sit inside a loop that queries your database, spawn four parallel researchers, hand off to a billing specialist, and produce a cited report before you finish your coffee. That progression is not one upgrade. It is four distinct architectural choices, each with its own loop shape, failure modes, and line item on the invoice.
This article maps that evolution step by step: single-shot LLM, single-agent loop, agent stack, and multi-agent swarm. For each stage we identify what the topology looks like, where it breaks, and when you should move to the next level. At the end we survey the swarms and frameworks actually worth watching in 2026, with an honest account of what each one is and what it is not.
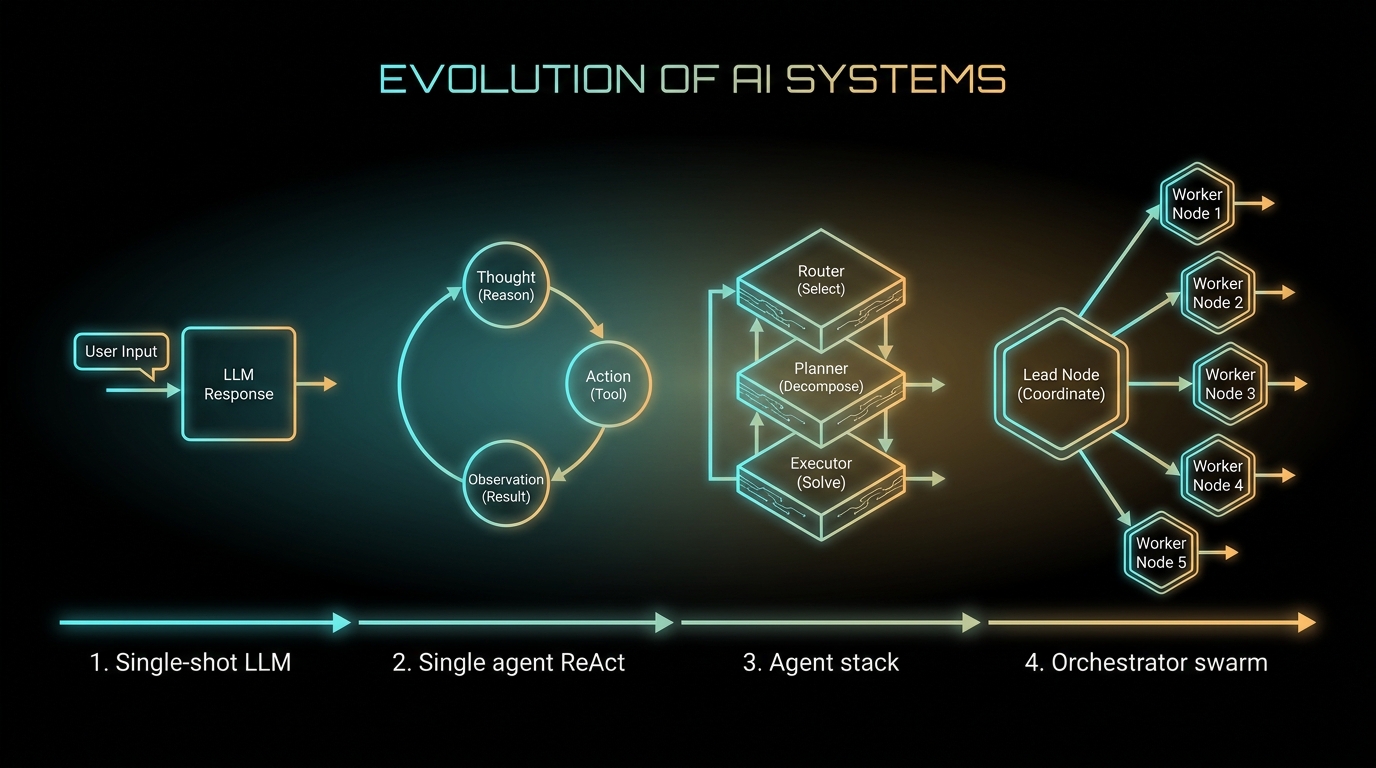
Stage 1: Single-Shot LLM (No Loop)
The baseline. You send a conversation; the model returns one completion. There are no tools, no state beyond the context window, and no mechanism to recover from a wrong first answer. It is also, for many use cases, exactly right.
Single-shot is well-suited to summarisation, drafting, classification, code explanation, and any task where one well-constructed pass is sufficient. What it cannot do is ground itself in live data, verify its own output, or adapt when the first guess is wrong. Ask “What is our refund policy as of today?” and the model either hallucinates or recites whatever made it into its training cut-off.
Kahneman’s framing from Thinking, Fast and Slow is apt here: this is System 1 at scale – fast, fluent, and confident even when incorrect. Agents exist because a substantial class of real tasks requires System 2 behaviour: deliberate steps, external verification, and the discipline to revise intermediate conclusions before committing to a final answer.
Stage 2: The Single-Agent Loop (ReAct and Its Descendants)
Stage 2 wraps the LLM in a cycle. The model reasons about what to do next (think), issues a tool call (act), reads the result (observe), and then repeats until a termination condition – the goal gate – says the task is done. Yao et al. formalised this as the ReAct pattern in 2022. Every major agent framework since then is a variation on that loop.
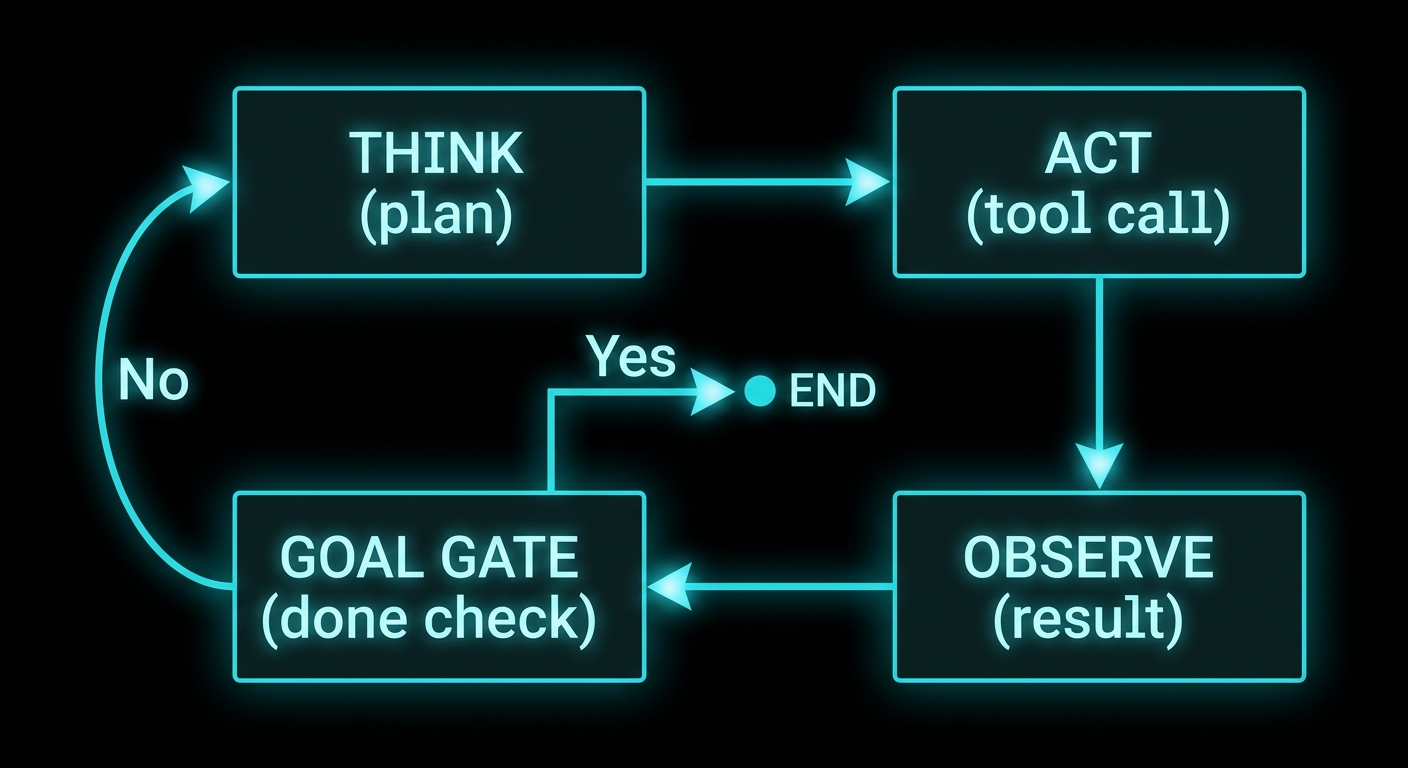
The implementation fork – whether the loop runs in your code or inside the inference provider’s runtime – is covered in depth in The Agent Tool Loop: Your Code or the Inference Runtime?. The topology is the same either way: one agent, one loop, tools below. For a full walkthrough of think-act-observe with worked examples, see The ReAct Pattern. For the foundational question of what separates an agent from a simple chatbot, start with What Is an AI Agent?
Case 1: Infinite tool loop
Without a hard max_steps cap and a goal gate that checks for non-empty final content, the model will keep requesting tools indefinitely on open-ended research tasks. It does not get tired; it just keeps going.
// Missing goal gate
while (true) {
const res = await llm.chat({ messages, tools });
if (!res.tool_calls?.length) break; // model might never stop requesting tools
for (const call of res.tool_calls) {
messages.push(await runTool(call));
}
}
// Result: burns budget until timeout or rate-limit. User sees a spinner.
Fix: cap steps, require empty tool_calls and non-empty content together, or add a cheap judge that evaluates whether the original question has been answered.
Case 2: Serial tools when parallel execution would suffice
A single agent exploring five independent sub-questions runs them sequentially. Wall-clock time scales linearly with sub-question count. Meanwhile, the context window fills with intermediate tool outputs that crowd out the final answer. This is the natural pressure that eventually pushes systems toward stage 4: when a task decomposes cleanly into parallelisable pieces, a single-thread loop is structurally the wrong shape.
Stage 3: The Agent Stack (Routing, Planning, Memory)
Production agents rarely expose a raw ReAct loop directly to users. Between the user’s input and the loop, engineers add layers: a router that selects which skill or prompt to apply, a planner that decomposes the request into an ordered task list, an executor that runs the loop, a memory layer that persists state across sessions, and an MCP or function-tool layer underneath. The loop still exists, but it sits inside a structured stack.
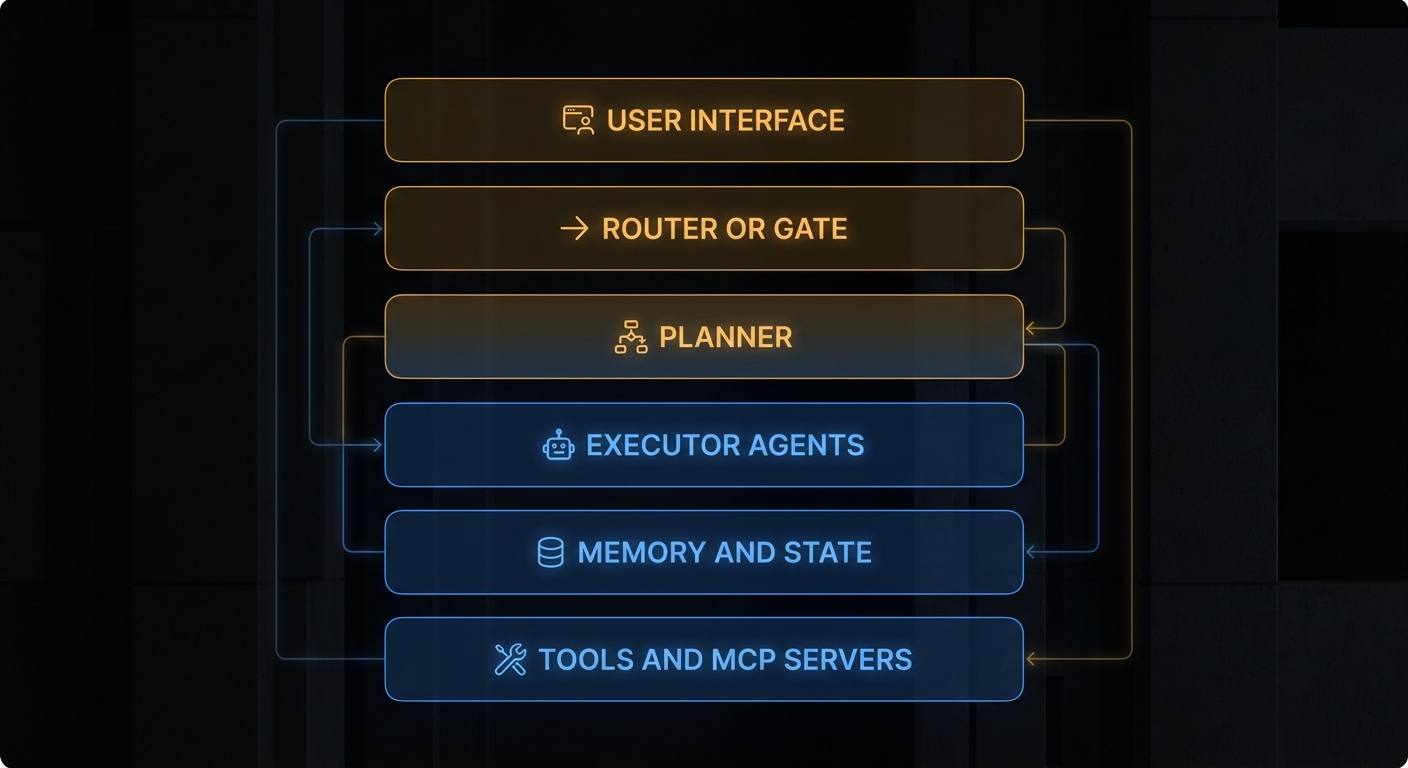
LangGraph, CrewAI, and the OpenAI Agents SDK all provide variations on this structure. The planner might be the same model running under a different system prompt that constrains its output to a JSON task list. The router might be a rules engine, a fast embedding classifier, or simply a switch on an explicit task_type field that the caller already knows.
The critical risk of the stack pattern is that each boundary is also a failure surface. Brooks’s law from The Mythical Man-Month applies here in miniature: every added layer adds an interface contract, and every interface contract can be violated. If the planner generates ambiguous steps, the executor hallucinates progress rather than admitting uncertainty. If the memory layer writes a stale fact, every downstream loop inherits it as ground truth. The stack is only as reliable as its weakest handoff.
Stage 4: Multi-Agent Swarms and Orchestrator-Worker Layouts
Stage 4 splits cognition across multiple LLM instances, each with its own context window and often its own specialised tools. The dominant production pattern in 2025-2026 is orchestrator-worker: a lead agent decomposes the task, spawns workers in parallel, collects compressed summaries, synthesises them, and decides whether another round of research is warranted.
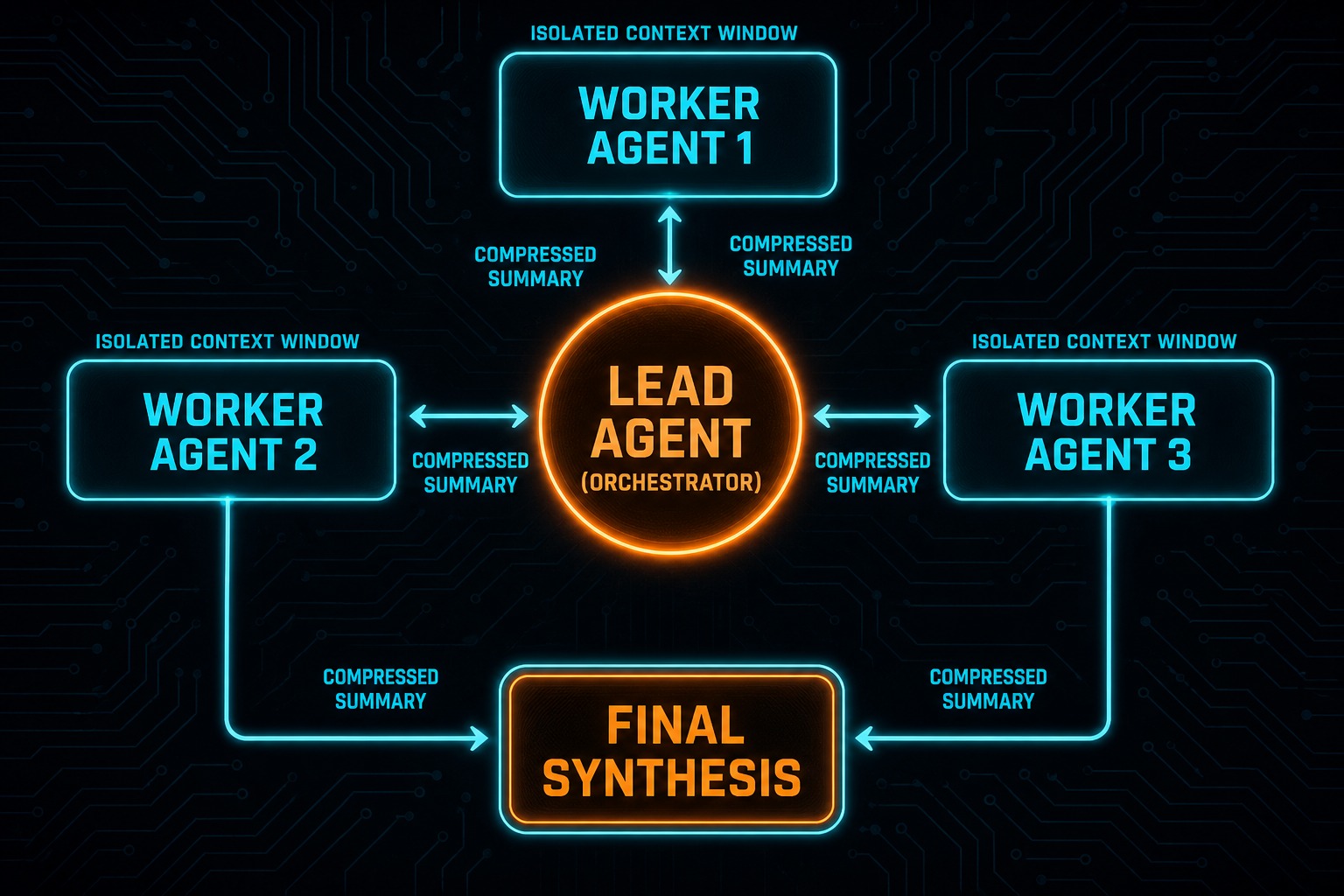
“Our Research system uses a multi-agent architecture with an orchestrator-worker pattern, where a lead agent coordinates the process while delegating to specialized subagents that operate in parallel.” — Anthropic Engineering, How we built our multi-agent research system
Anthropic’s Claude Research feature is the most detailed public implementation to learn from. The lead agent plans, saves its plan to memory before context exceeds 200K tokens, spawns scoped subagents in parallel, and iterates until coverage is sufficient. A separate CitationAgent post-processes the output. On Anthropic’s internal benchmarks, the multi-agent version outperformed a single Claude Opus agent by 90.2% on breadth-first research tasks – tasks that require pursuing many independent directions at once.
The cost is not free. Anthropic reports that multi-agent research uses roughly 15x the tokens of a standard chat interaction, versus approximately 4x for a single agentic loop. You are purchasing parallel context windows and specialised prompts. The gain is real; so is the invoice.
Handoff swarms: peer topology
Not every swarm is hierarchical. OpenAI’s original Swarm framework – now superseded by the production Agents SDK – popularised a flat alternative: handoffs, where peer agents pass control to whichever specialist is most appropriate for the current sub-task. Think of it as a triage nurse routing you to billing, radiology, or the pharmacist, depending on what you need next, rather than a manager who assigns all tasks from the top.
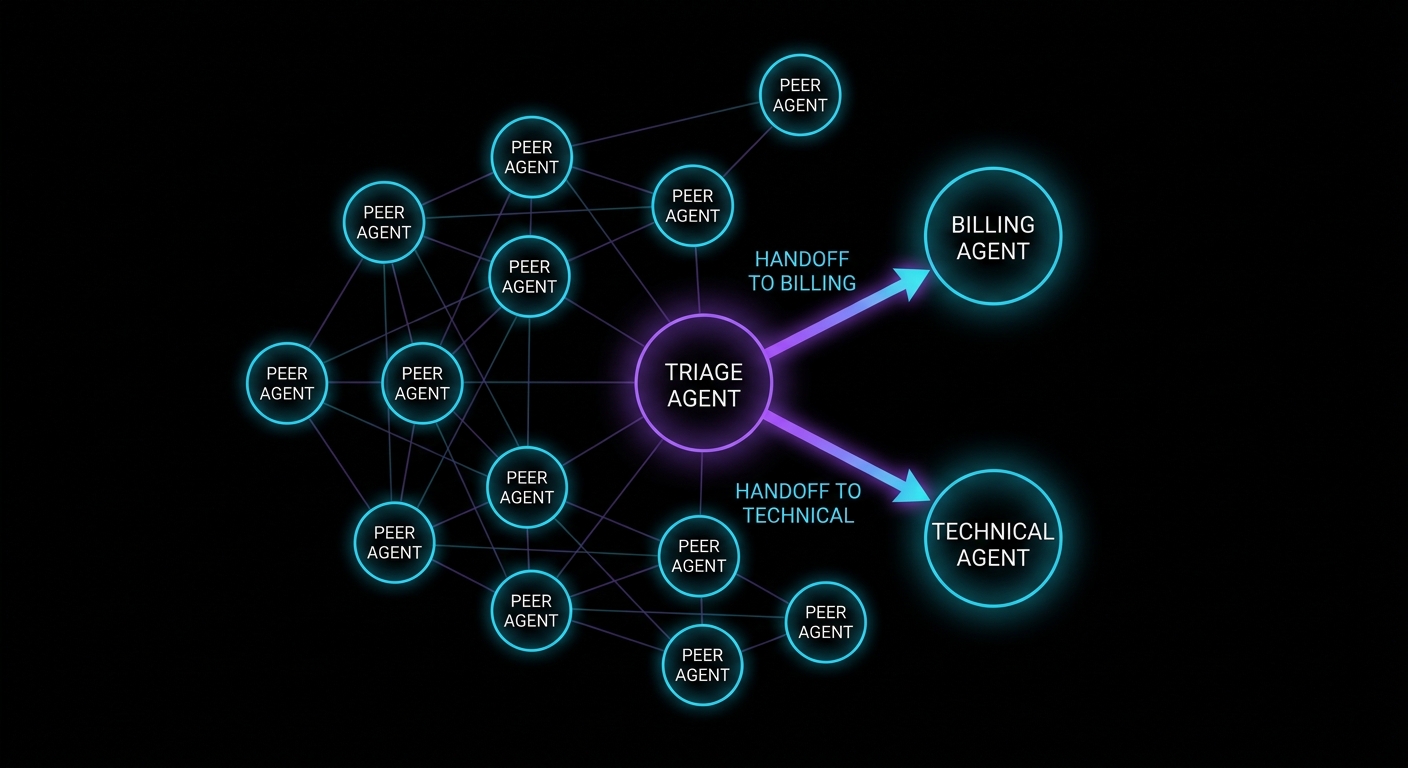
“The OpenAI Agents SDK enables you to build agentic AI apps in a lightweight, easy-to-use package with very few abstractions. It’s a production-ready upgrade of our previous experimentation for agents, Swarm.” — OpenAI Agents SDK documentation
The SDK’s design is deliberately minimal: agents with instructions and tools, handoffs for delegation, guardrails for validation, and a built-in runner loop. You orchestrate in Python rather than learning a graph DSL. For teams evaluating managed loops with built-in tracing, this is OpenAI’s answer to the local-versus-managed question.
Topology Comparison: Which Layout for Which Job?
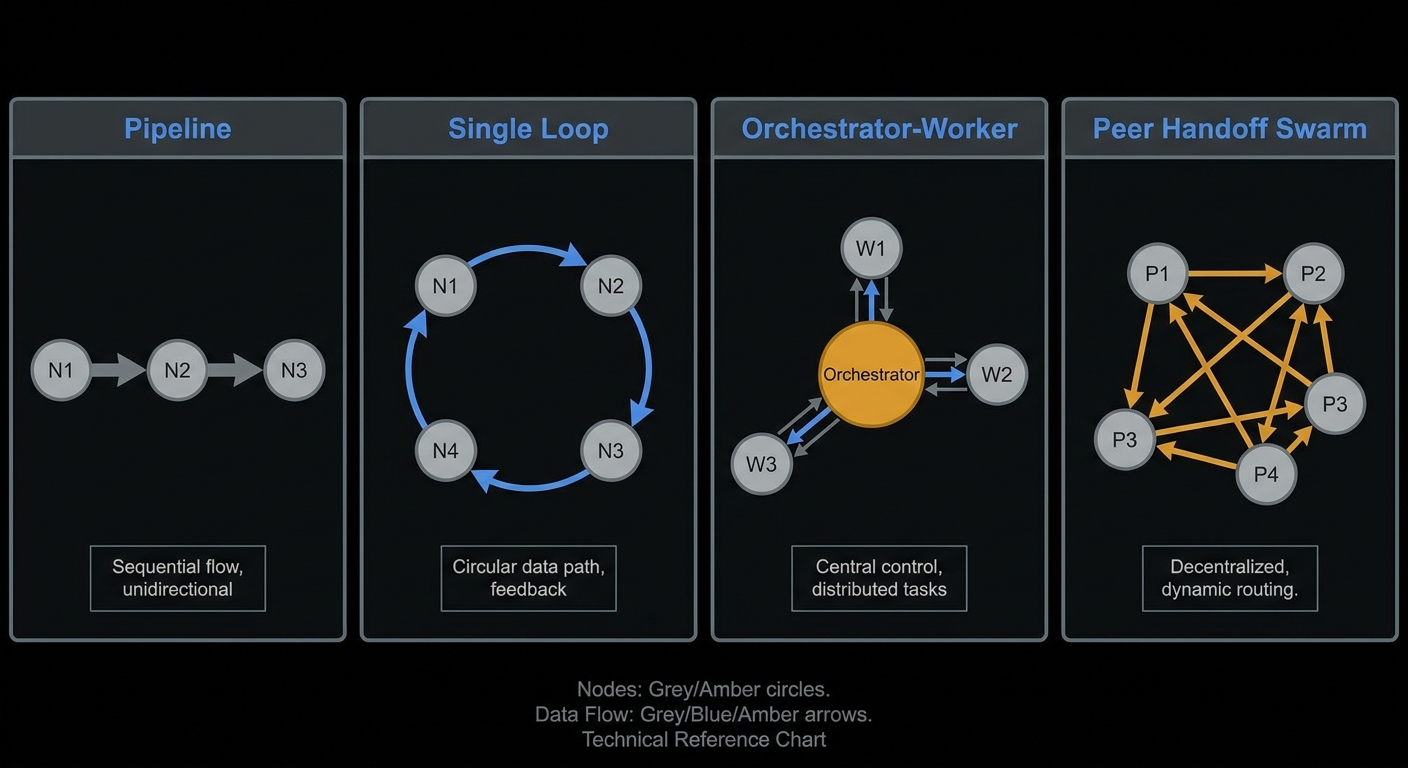
| Layout | Best for | Weak when |
|---|---|---|
| Pipeline | Fixed ETL flows (extract, summarise, format) | The path depends on what intermediate steps discover |
| Single loop | 1-5 tool calls, one user, one domain | Many parallel sub-tasks, or context window fills |
| Orchestrator-worker | Research, due diligence, multi-source synthesis | Tight shared mutable state, real-time coding |
| Handoff swarm | Support triage, multi-department workflows | You need a single unified plan visible to all agents |
Google’s A2A (Agent-to-Agent) protocol adds a wire format for agents discovering and calling each other across separate services. Pair it with MCP for tool access and you get the distributed topology described in our A2A + MCP course lesson. The loop logic still lives inside each agent; A2A and MCP standardise the plumbing between them.
Swarms to Keep an Eye On (2026)
The field moves fast. The list below covers the systems and frameworks actually worth tracking, with an honest note on what each one is – and what it is not.
Claude Research (Anthropic product, orchestrator-worker)
Production multi-agent research running inside Claude.ai and the API. Lead agent, parallel subagents with scoped objectives, and a CitationAgent post-processing pass. The engineering post is the best public blueprint for orchestrator-worker at scale: explicit scaling rules embedded in prompts (“simple fact-finding: 1 agent, 3-10 tool calls; complex research: up to 10 subagents”), parallel tool calling, and memory for long-running plan state. This is not a framework you embed in your codebase – it is a reference architecture to learn from and adapt.
OpenAI Agents SDK (successor to Swarm)
Production Python and JavaScript SDK with a built-in runner loop, handoffs, guardrails, MCP integration, session persistence, and tracing. The original Swarm repository stays on GitHub as an educational resource, but OpenAI explicitly positions the Agents SDK as the production upgrade path. Use it when you want managed loop behaviour without writing and maintaining your own runner.
LangGraph (LangChain)
Graph-based orchestration where nodes are steps or agents and edges are conditional transitions. Strong when you need explicit state machines, human-in-the-loop interrupt points, and checkpoint-resume for long-running flows. More structural ceremony than handoff-style delegation, but better observability for complex multi-step pipelines. Our MCP + LangGraph lesson walks through a concrete Node.js integration.
CrewAI
Role-based agent teams (“researcher”, “writer”, “critic”) with a configurable process layer: sequential, hierarchical, or consensual. Popular for demos and internal automation pipelines where roles map cleanly onto recognisable job functions. Watch for duplicated work when role boundaries are loosely defined – two agents with overlapping mandates will pursue the same sources independently.
Microsoft AutoGen
Conversation-centric multi-agent with flexible speaker selection. Strong for iterative refinement patterns such as a coder-reviewer pair. Less opinionated about topology than LangGraph, which means you assemble the conversation pattern yourself rather than following prescribed structures. Good for teams that want flexibility; requires more discipline to keep flows predictable.
Anthropic long-running coding harnesses
Separate from Research: a planner-generator-evaluator trio designed for coding tasks that run over many turns, with externalised plan files and checkpoint-based state. The same orchestrator-worker family, but optimised for mutable repositories rather than read-mostly web research. Most useful as a structural reference when building autonomous coding agents.
Manus and closed commercial products
Products like Manus package multi-agent planning, execution, and verification as a bundled experience. Treat them as black-box reference points for benchmarking UX expectations and latency – not for architectural inspiration, since the internal structure is not public.
For the failure modes that emerge specifically when you have more than one agent – hallucination cascades, trust boundary violations, process-level conflicts – read Multi-Agent Systems: Coordination, Trust, and Failure Modes and Lesson 40: Multi-Agent Failure Modes.
Failure Cases Unique to Swarms
Case 3: Subagent sprawl
Early Anthropic prototypes spawned up to 50 subagents for simple queries. Each spawn is a full context window and tool budget. Without explicit scaling rules embedded in the orchestrator prompt, the model interprets “be thorough” as “spawn as many agents as possible.”
// Dangerous: no budget constraint in orchestrator prompt
lead.spawnSubagents(userQuery);
// Model spawns 20 agents for a question that needs one.
// Better: encode scaling rules directly in the system prompt:
// "Simple fact-finding: 1 subagent, 3-10 tool calls.
// Direct comparison: 2-4 subagents, 10-15 tool calls each.
// Complex multi-source research: up to 10 subagents."
Case 4: Telephone-game synthesis
Workers return long prose summaries; the lead agent paraphrases each one and loses precision. By the time three subagent summaries reach the synthesiser, the final answer is the paraphrase of a paraphrase. Anthropic’s mitigation is artifact storage: subagents write structured output to an external store and pass lightweight references back to the lead, which reads the structured data directly rather than receiving a prose retelling.
Case 5: Duplicate search coverage
Without scoped, specific task descriptions, two workers run identical web searches. The delegation prompt must give each subagent a clear objective, an output format, explicit tool guidance, and a task boundary. “Research the semiconductor shortage” is too vague; “List the five largest automotive chip suppliers in Asia who reported supply changes in 2025. Return a JSON array with name and source URL” is a workable scope.
When a Single Agent Is Actually the Right Answer
Multi-agent is not a maturity badge. It is a tool for a specific problem: parallelism across independent sub-tasks that would overflow a single context window. Anthropic note that coding tasks often have fewer truly parallelisable steps than research, and that shared mutable state – a codebase under active revision – fits poorly across independent workers today.
Stay at stage 2 when:
- The task completes reliably in fewer than eight tool calls.
- All steps share one context and one user-facing voice.
- Latency matters more than exhaustive coverage (interactive support chat, not due diligence).
- Your evaluation shows the swarm wins by less than the cost multiplier justifies. 15x token cost is hard to rationalise for a marginal quality gain.
Move to stage 4 when:
- Sub-tasks are independent and genuinely parallelisable – for example, finding board members for 500 companies, or scanning legislation across multiple jurisdictions simultaneously.
- A single context window would overflow if one agent handled everything serially.
- The economic or informational value of the answer clearly exceeds the token cost – legal research, financial due diligence, security investigations.
What to Check Right Now
- Map your current stage honestly. Single-shot, one loop, a stack, or a swarm? Most teams overestimate where they are.
- Measure tokens per successful task. Run single-agent and multi-agent on the same evaluation set before committing to swarm topology.
- Instrument every loop. Local or managed, you need traces: LLM latency, tool latency, spawn count, and the reason the goal gate fired. Without these, swarm debugging is guesswork.
- Embed scaling rules in orchestrator prompts. Explicit subagent budgets are the most direct protection against sprawl.
- Pick one SDK, one protocol. Agents SDK or LangGraph for orchestration; MCP for tools; A2A only if your agents genuinely live in separate services.
The evolution from LLM to swarm is not a ladder you must climb. It is a collection of shapes, each correct for a different problem: one loop for focused tool use, a stack for routing and memory, a swarm for compressing vast parallel search spaces. Choose the smallest shape that passes your evaluations, and upgrade only when the constraints of a single serial context window become the proven bottleneck.
nJoy 😉