Your RAG benchmark says the system is excellent. The benchmark may also be the least trustworthy component in the stack. A green scoreboard can prove that known failures stayed fixed. It cannot, by itself, prove that the next unfamiliar question will be answered correctly, that the cited passage supports the sentence beside it, or that the retrieved rule was valid for the date in question. This is the measurement gap: retrieval-augmented generation has become easier to build than to evaluate honestly.
This article is a field guide to closing that gap. It treats a benchmark as an instrument, not a verdict, and works through the layers a serious evaluation programme must measure: corpus integrity, planning, retrieval, evidence assembly, generation, citations, abstention, operational reliability, security, and production drift. It also separates established research findings from practical engineering defaults, because a recommendation is not transformed into a scientific fact by putting it in a dashboard.

1. A perfect regression score is not perfect accuracy
A fixture becomes exposed when its question, expected answer, or failure analysis influences the system being tested. Perhaps an engineer adds a prompt rule after reading the failure. Perhaps a knowledge entry is written to pin the missing fact. Perhaps a routing skill is changed so the planner chooses a particular tool. The fixture remains useful, but its meaning changes.
An exposed fixture can still demonstrate that a known defect has not returned. That is important. Regression testing is how software retains hard-won behaviour. What the fixture no longer provides is independent evidence of generalisation. A system repeatedly repaired against the same fifty questions may eventually answer all fifty. That says little about question fifty-one unless the suite was designed to represent the population and protected from the development process.
Microsoft Research’s 2026 SeedRG work describes a related problem at the model level: many RAG benchmark questions can be answered from parametric memory without retrieval, and static benchmarks become less discriminating as they age and enter training data. Application development creates a second form of exposure: even if the foundation model never saw a fixture, the application’s prompts, skills, rules, retriever and judge may have been shaped by it.
“This means that improvements on SWE-bench Verified no longer reflect meaningful improvements in models’ real-world software development abilities. Instead, they increasingly reflect how much the model was exposed to the benchmark at training time.” – OpenAI, Why SWE-bench Verified no longer measures frontier coding capabilities
OpenAI’s example concerns model-training contamination in a coding benchmark. It does not prove that every private RAG fixture is contaminated. It does demonstrate the governing principle: once an evaluation item influences the thing being evaluated, the score needs a narrower interpretation.
Three kinds of exposure that should not be confused
- Model-training contamination: benchmark questions or solutions appear in model pretraining or fine-tuning data.
- Application-development exposure: developers tune prompts, skills, retrieval, tools or knowledge after inspecting fixture outcomes.
- Evaluator exposure: expected patterns, rubrics, thresholds or judge prompts are changed after observing model answers.
These mechanisms have different controls. Fresh questions reduce application exposure. Contamination-resistant generation can reduce model-memory leakage. A locked, calibrated judge helps contain evaluator drift. Calling all three simply “overfitting” hides where the corrective action belongs.
What exposed fixtures are good for
- Detecting the return of known failures
- Testing deterministic output and citation contracts
- Verifying that timeouts and errors remain visible
- Comparing latency, tool usage and cost across versions
- Reproducing incidents during debugging
What exposed fixtures cannot establish alone
- Unseen-question accuracy
- Coverage of the production distribution
- Domain-wide legal, medical or financial correctness
- Independence between apparently different questions
- A defensible percentage such as “95% accurate”
The useful correction is not to discard the suite. Label it honestly: exposed development and regression fixtures.
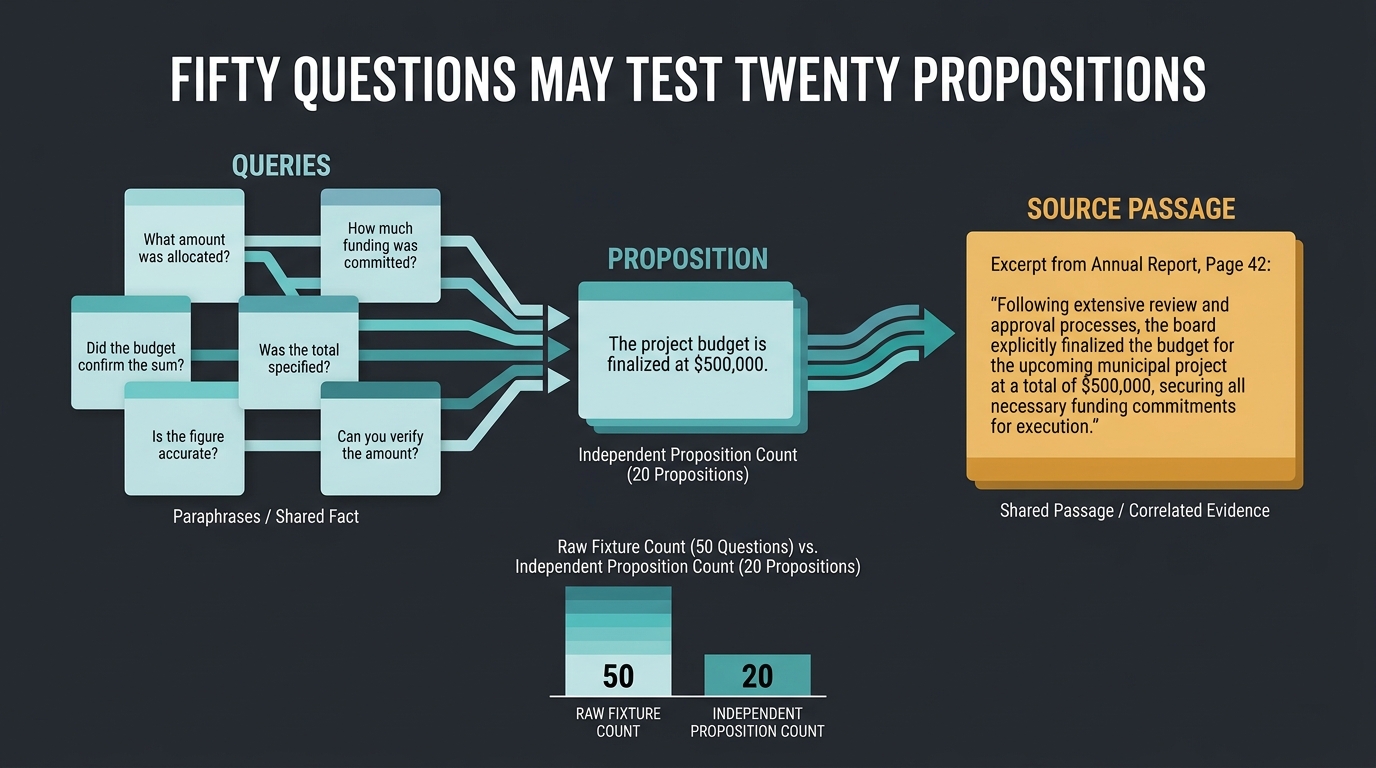
2. Fifty questions may test twenty propositions
Question count is not capability count. Two paraphrases of the same factual proposition are correlated observations. Five prompts that all depend on the same source paragraph are not five independent demonstrations that the system understands the wider instrument. If one fix inserts that proposition into a knowledge store, all five may turn green together.
A trustworthy split groups questions before partitioning them. Useful grouping keys include:
- Underlying proposition or numeric fact
- Source passage and document family
- Instrument and legal unit
- Question-template family
- Historical failure incident
- Entity, customer or time period
All variants from the same group should stay in the same partition. Otherwise a paraphrase lands in validation whilst its twin remains in development, and the supposed holdout quietly measures recognition.
Case 1: the duplicate confidence trick
A suite contains six questions about one threshold: direct lookup, paraphrase, scenario, yes-or-no variant, comparison and citation request. The system is repaired by adding one explicit knowledge entry. Six tests pass. The dashboard records six wins, but the underlying gain is one proposition successfully pinned. This is valuable regression coverage and weak breadth evidence.
The corrected report says both things: six fixtures passed and one proposition family was exercised. The first describes operational coverage; the second describes epistemic breadth.
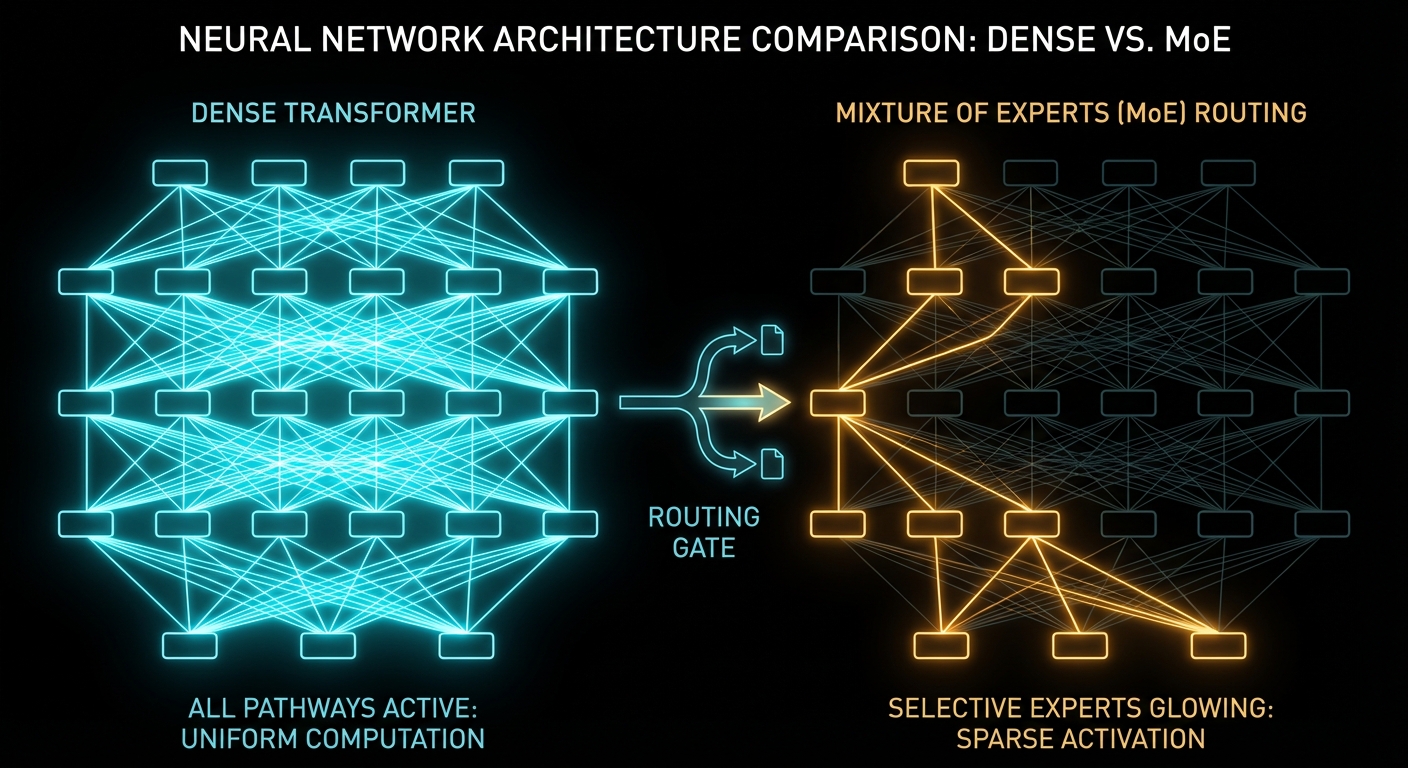
3. Retrieval is only one layer of RAG quality
The original RAGAS paper made a foundational point: RAG evaluation contains several dimensions, including retrieval of focused context, faithful use of that context, and generation quality. Recent diagnostic work such as RAGVUE expands that decomposition into retrieval quality, answer relevance and completeness, strict claim-level faithfulness, and judge calibration.
“Evaluating RAG architectures is, however, challenging because there are several dimensions to consider: the ability of the retrieval system to identify relevant and focused context passages, the ability of the LLM to exploit such passages in a faithful way, or the quality of the generation itself.” – Es et al., RAGAS
A single end-to-end score cannot tell you which layer failed. A fluent answer can conceal bad retrieval. Excellent retrieval can be ignored during synthesis. Correct content can carry the wrong citation. A correct answer can still be incomplete because it omitted the exception that controls the outcome.
A nine-layer measurement map

Layer 1: corpus and ingestion integrity
Measure source authority, corpus completeness, document versions, extraction accuracy, chunk boundaries, metadata completeness, duplication, stale material, access-control labels and parity between relational and vector stores. A retriever cannot recover a page that was never ingested, a table that OCR corrupted, or a current rule stored under the wrong date.
Layer 2: query understanding and planning
Measure intent classification, entity parsing, reference extraction, temporal interpretation, corpus selection, tool choice, skill selection and plan completeness. If a planner sends a statute query to a generic semantic search route, better reranking cannot repair the initial scope error.
Layer 3: retrieval
Use metrics such as Recall@k, Precision@k, mean reciprocal rank, nDCG for graded relevance, first relevant rank, authoritative-source recall, exact-reference recall, duplicate-result rate and temporal-filter accuracy. No one metric is sufficient. High MRR says the first relevant item appears early; it does not say the remaining context is complete or non-redundant.
Layer 4: evidence assembly
Measure whether all answer facets have support, whether exceptions were retrieved, whether contradictory sources were detected, whether authority and temporal rules were applied, and whether the evidence survived context packing. This is the bridge between retrieval and generation, and it is often missing from evaluation dashboards.
Layer 5: generation
Measure correctness, completeness, relevance, faithfulness, qualification, unsupported inference, omission of decisive exceptions and readability for the target audience. Correctness and faithfulness are different: an answer can be factually correct from model memory yet unsupported by the evidence supplied to synthesis.
Layer 6: citations and provenance
Measure citation existence, source validity, claim-to-source entailment, citation completeness, source authority, temporal validity, passage alignment and whether the cited evidence was actually present in the synthesis context.
Layer 7: abstention and uncertainty
Measure correct abstention, unnecessary abstention, unsupported certainty, escalation quality and calibration. A system that refuses every difficult question may be safe but useless. A system that answers every question may be useful until the first invisible high-impact error.
Layer 8: operations
Track p50, p95 and p99 latency; timeout and error rates; tool-call counts; tokens; monetary cost; cold starts; concurrency degradation; retry amplification; and dependency failures. Average latency can look healthy whilst one class of query regularly takes several minutes.
Layer 9: production distribution
Measure coverage of real user intents, shifts between fixtures and live queries, human correction rates, expert disagreement, and performance by route, document class and difficulty. A pristine holdout that does not resemble production is scientifically clean and operationally unhelpful.
4. The citation can be correct and the answer can still be wrong
A citation token is not a grounding proof. Checking that a document identifier appears somewhere in an answer does not establish that the document supports the claim beside it. It also does not establish that the cited version was operative, that the passage came from an authoritative source, or that synthesis ever received it.
RAGAS decomposes answers into statements and asks whether each can be inferred from context. VeriCite goes further by verifying supporting evidence before final answer refinement, using natural-language inference to test whether retrieved passages entail answer statements. RAGVUE similarly credits claim-level evidence rather than relying on one scalar impression.
Case 2: the right citation family, wrong proposition
An answer cites the correct statute but the wrong article. A regex verifier sees the chapter identifier and passes it. A claim-level verifier asks a harder question: does the cited passage entail the nearby sentence? If not, the citation is present but invalid.
Case 3: the current passage for a historical question
A user asks what rule applied several years ago. Retrieval returns today’s provision because it is newer, cleaner and semantically close. The answer is perfectly grounded in the retrieved text and legally wrong for the requested date.
A 2026 study of time-sensitive statutory question answering tested 312 expert-validated German legal questions and examined both post-cutoff staleness and recency bias. Its retrieval variants extracted an as-of date and filtered the corpus to versions valid in that period. The authors found that the correct timeframe mattered more than whether retrieval used embeddings or a table-of-contents route, and concluded that temporal validity must be treated as a hard constraint.
That lesson generalises beyond law. Product policies, medical guidance, tax thresholds, contracts, software documentation and organisational procedures all change. Semantic similarity answers “what text looks relevant?” Temporal applicability answers “which relevant text governed then?”
The minimum provenance record
- Evidence identifier supplied to synthesis
- Document and legal-unit identity
- Version, effective period and temporal status
- Authority tier
- Relevant source passage
- Atomic claim in the final answer
- Entailment judgment and rationale
- Temporal-consistency judgment
If these fields are missing, report grounding as unavailable. An empty unsupported-claims array can mean “nothing was unsupported” or “nothing was checked.” Those states must never share the same green badge.

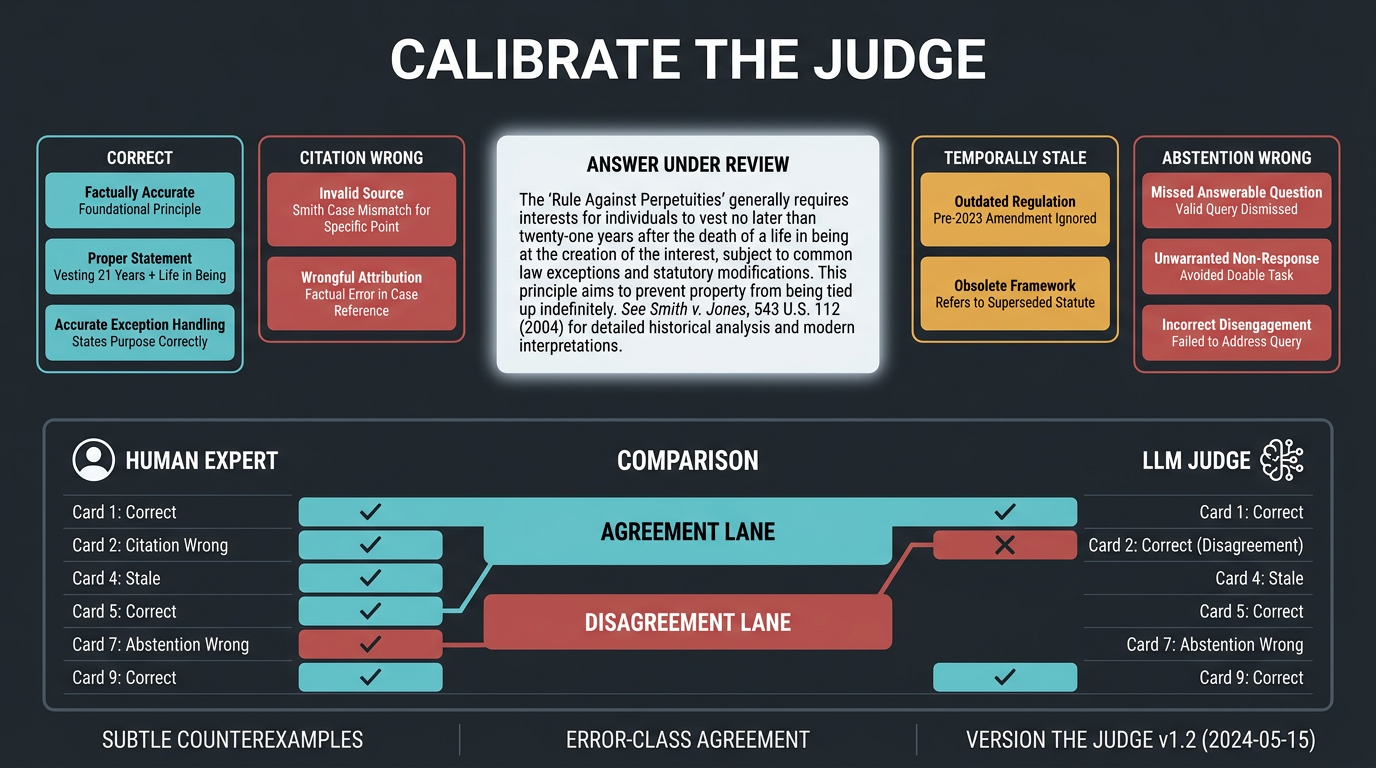
5. Calibrate the judge before trusting the judged
An LLM judge is another model in the system, not an oracle hovering above it. Judges can prefer polished prose, reward verbosity, share misconceptions with the answering model, and change behaviour after a model or prompt update. One scalar score conceals disagreement among correctness, completeness, faithfulness and style.
RAGVUE makes judge calibration an explicit dimension. The temporal statutory QA study also validated its LLM judge against a legal expert, reporting stronger agreement on outcome correctness than on legal-basis correctness. That asymmetry matters: verifying a conclusion can be easier than verifying the precise provision that supports it.
Build a verifier unit-test suite
For each representative question, write controlled answer variants:
- Fully correct and properly cited
- Correct answer with an irrelevant citation
- Correct citation token attached to the wrong claim
- Topically relevant but temporally stale
- Mostly correct but missing a decisive exception
- Unsupported but plausible
- Correct abstention
- Unnecessary abstention
- Overconfident answer where evidence is insufficient
- Correct content derived from information never supplied to synthesis
Then measure judge-human agreement by error class. Keep deterministic checks for identifiers, required fields, source existence and citation spans. Use expert review for consequential promotion decisions. The goal is not to eliminate LLM judges; it is to know what each judge can and cannot distinguish.
6. Small evals produce large confidence theatre
Specialised RAG benchmarks are often small because expert questions and labels are expensive. Small does not mean useless. It means uncertainty must be treated honestly.
“In these small-data settings, we demonstrate that CLT-based methods perform very poorly, usually dramatically underestimating uncertainty (i.e. producing error bars that are too small).” – Bowyer, Aitchison and Ivanova, ICML 2025
Miller’s statistical treatment of language-model evaluation starts from a similarly useful premise: evaluations are experiments. It recommends question-level paired comparisons when comparing systems and power analysis to determine whether a benchmark can detect an improvement of interest.
This changes the question from “did the score rise?” to “how large is the estimated change, how uncertain is it, and was the eval capable of detecting the minimum improvement we care about?”
A practical pilot protocol, not a universal law
For a small, expensive RAG evaluation, a useful starting protocol is:
- Write the hypothesis, primary endpoint and safety endpoints before running.
- Define the minimum improvement worth shipping and the largest acceptable regression.
- Limit the candidate search budget before viewing results.
- Use paired control and treatment runs on the same questions.
- Randomise or interleave run order to reduce cache and provider-order effects.
- Use low concurrency for causal comparison, then separately test production concurrency.
- Report effect sizes and uncertainty, not only pass/fail.
- Open protected validation only after choosing the candidate.
- Run the complete exposed regression suite as a separate safety gate.
- Promote, reject or collect more data according to a rule written in advance.
Three repetitions may be a reasonable pilot, but it is not a statistical commandment. Required repetitions depend on variance, acceptable uncertainty, cost and the effect size of interest.
Do not let any-success hide unreliable behaviour
For stochastic systems, distinguish:
- Per-attempt success rate: how often the ordinary first answer succeeds
- Any-success-in-k: whether repeated sampling can eventually produce a success
- All-success-in-k: whether the behaviour remains stable across repeated attempts
Any-success-in-k is useful when users can sample several candidates and select one. It is misleading when a user receives only the first answer. High-stakes evaluation should centre the probability that the ordinary first answer is materially correct, supported and appropriately qualified.

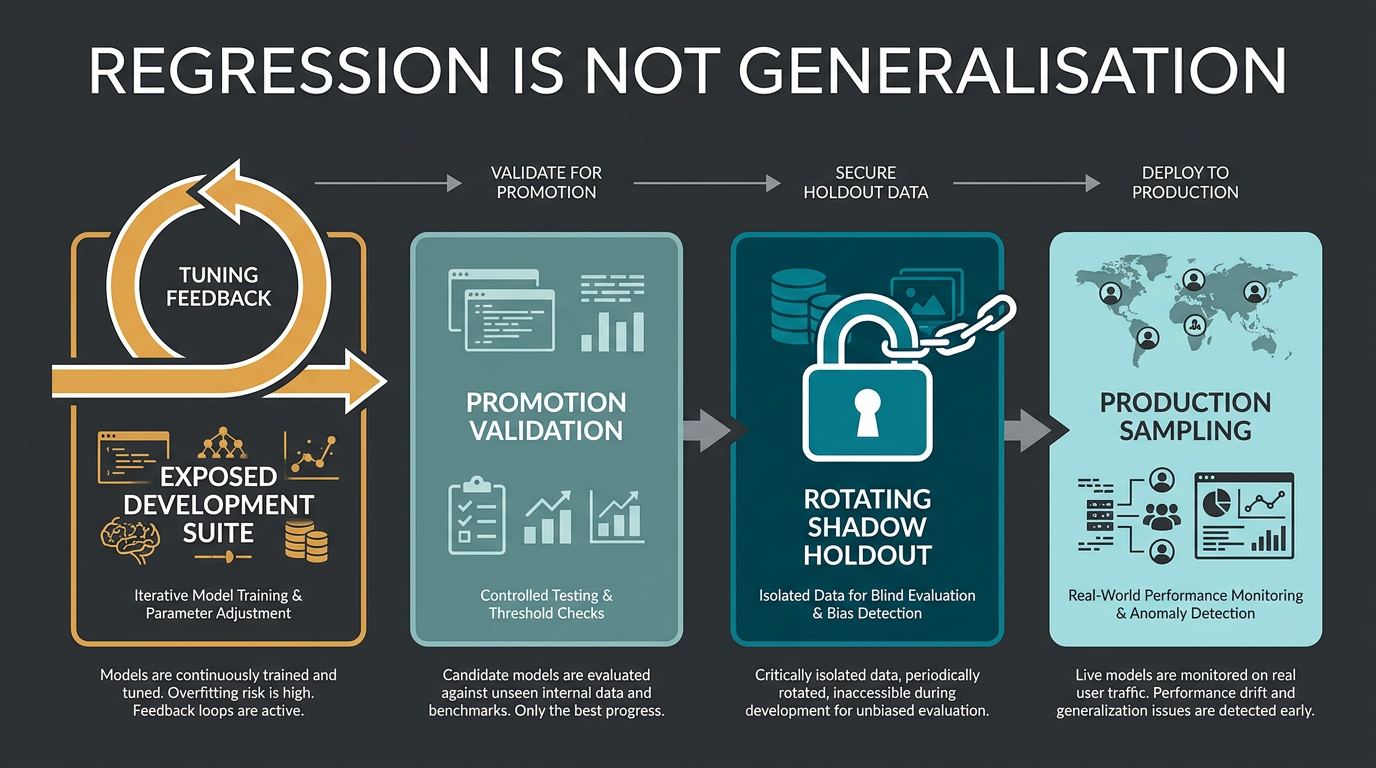
7. A holdout stops being a holdout when you learn from it
The classical holdout idea is simple: evaluate on data that did not influence model selection. Its discipline is difficult in an iterative AI project because every failure invites a repair.
“Ideally, the test set should be kept in a “vault,” and be brought out only at the end of the data analysis. Suppose instead that we use the test-set repeatedly, choosing the model with smallest test-set error. Then the test set error of the final chosen model will underestimate the true test error, sometimes substantially.” – The Emerging Science of Machine Learning Benchmarks, The Holdout Method
A continuous-delivery team cannot commission a completely new expert set after every minor change. The workable compromise is a governed hierarchy.
Development set
Historically exposed questions used for diagnosis, prompt development and candidate generation. Run frequently. Treat as regressions, not unbiased accuracy.
Promotion validation set
Fresh questions not used to write the candidate. Use to decide whether a candidate deserves release review. Once inspected and learned from, mark them exposed for future campaigns.
Rotating shadow holdout
Owned separately, opened at baseline or release checkpoints, and replenished with expert-reviewed cases. Never provide its questions, answers or failure traces to candidate generation.
Complete regression scoreboard
Every admitted fixture appears as pass, fail, error, not_run or stale. The denominator is declared before execution and cannot shrink because a worker timed out.
Case 4: one hundred per cent of the rows that survived
A fifty-case run writes forty-seven successful rows. Three jobs time out and disappear during resume. The report says forty-seven passed, which sounds perfect. The correct report says forty-seven passed, two timed out and one was not run. Completion accounting is part of correctness.
8. Freeze the right layer or your experiment proves nothing
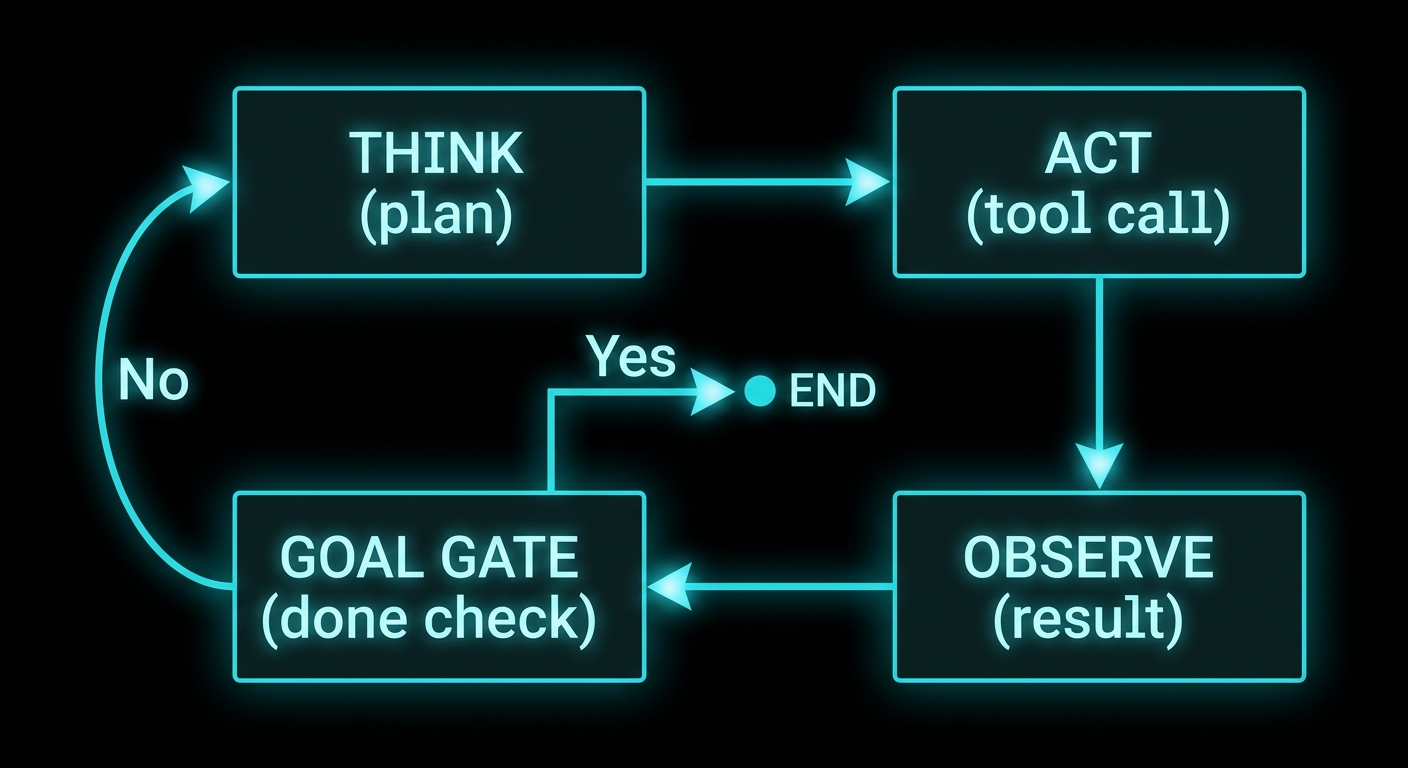
A RAG answer can change because the planner selected another route, tools returned different evidence, retrieval ordering shifted, context packing changed, synthesis sampled different tokens, or the judge changed its mind. End-to-end evaluation is necessary, but it is poor at causal diagnosis.
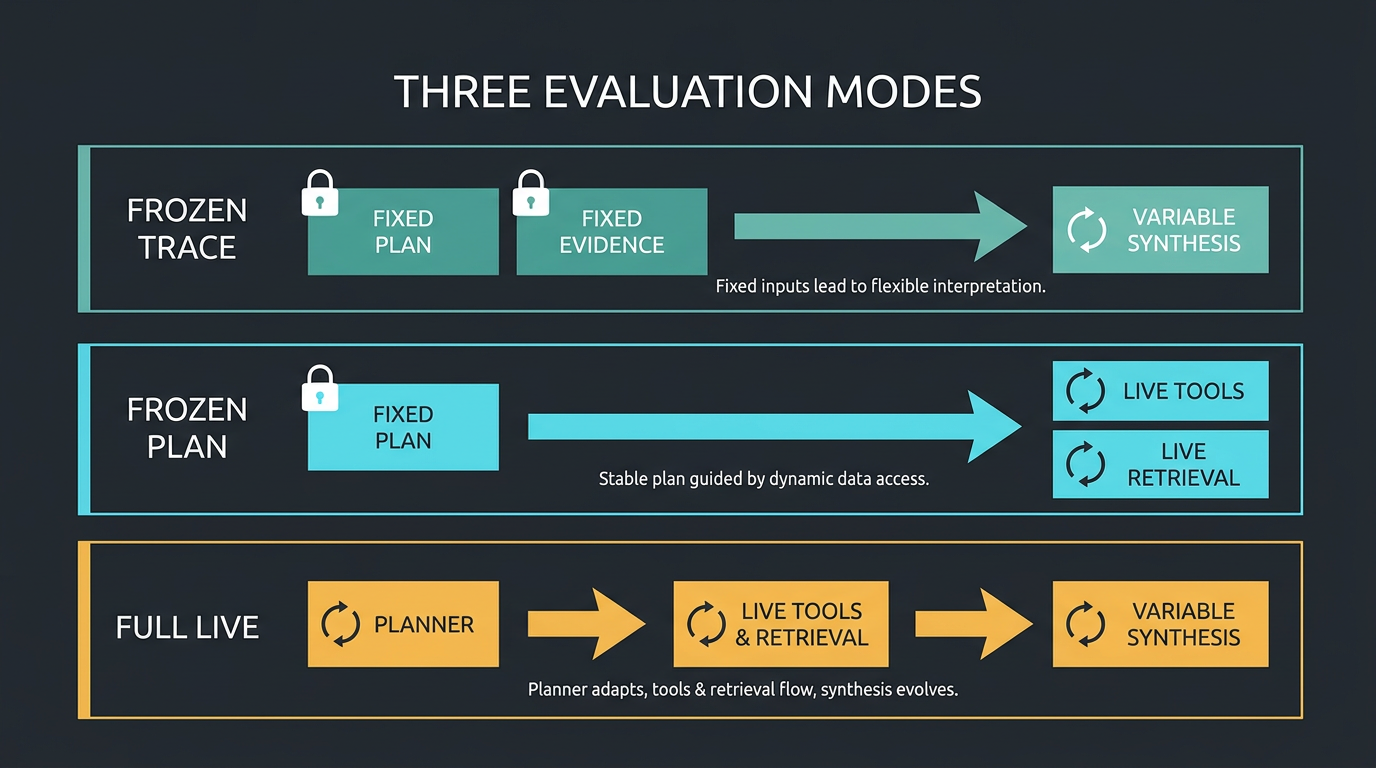
Mode A: frozen-trace replay
Fix the plan and exact evidence payload. Vary prompt wording, skill wording, synthesis instructions or formatting. This asks: given identical evidence, did the downstream change improve the answer?
Mode B: frozen-plan, live discovery
Fix the planner output but allow tools and retrieval to run. This measures retrieval, evidence merge, reranking and fallback behaviour without planner variability.
Mode C: full live
Let planner, tools, retrieval and synthesis operate normally. This measures production behaviour. Report it separately because it answers a different question from the two diagnostic modes.
The one-variable illusion
Changing one file is not necessarily changing one variable. Editing a skill can alter planner selection, tool sequence, retrieved evidence and synthesis. Every experiment should state:
- The direct treatment
- Expected downstream mediators
- Allowed mediator changes
- Forbidden collateral changes
- The evaluation mode being used
Case 5: fixing retrieval that never ran
A team changes fallback retrieval and sees no gain in a frozen-plan test. Later it discovers that the full-live planner rarely selected that route. The retrieval intervention may be sound, but the production bottleneck is route selection. Layered evaluation prevents the team from repairing the wrong component.
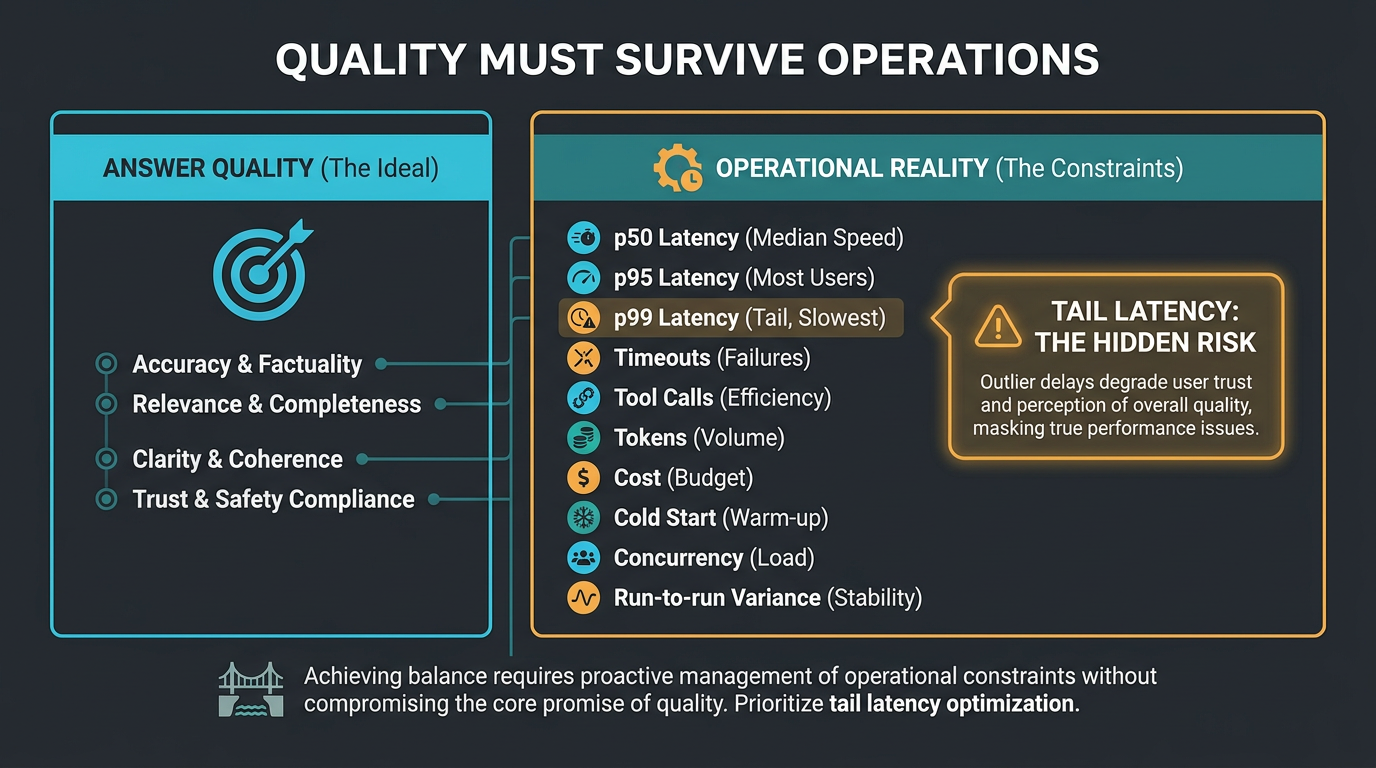
9. Quality without latency, cost and reliability is a laboratory result
A treatment can improve answer quality and still be unshippable. Adding broad retrieval, reranking, repeated judging and fallback waves may increase coverage whilst multiplying latency and cost. Conversely, a faster route can look attractive because it silently skips difficult cases.
Report at least:
- p50, p95 and p99 end-to-end latency
- Timeout and dependency-error rate
- Tool calls and fallback rate
- Input and output tokens
- Actual or clearly estimated monetary cost
- Cold-start and warm-run behaviour
- Concurrency degradation
- Answer variance across repetitions
Average latency alone hides tail risk. A route averaging thirty seconds may still contain a class that regularly runs for three minutes. For interactive use, the tail determines trust.
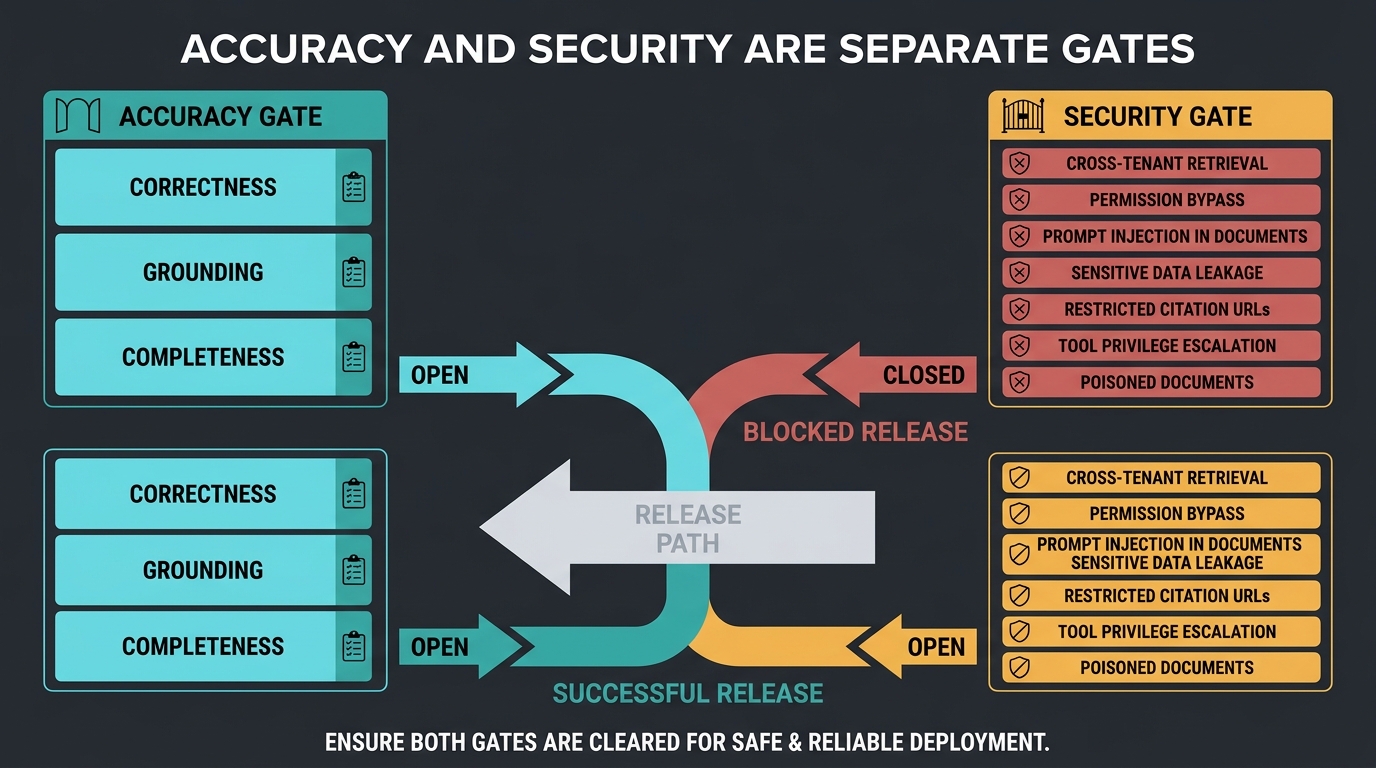
10. Accuracy and security are separate release gates
A system can answer correctly and still expose another tenant’s documents. It can retrieve authoritative evidence that contains prompt injection. It can cite a restricted file through a public URL. These are not ordinary answer-quality failures.
A complete RAG evaluation programme needs dedicated tests for:
- Cross-tenant and cross-user retrieval
- Permission-filter bypass
- Prompt injection embedded in retrieved documents
- Sensitive-data leakage
- Restricted citation URLs
- Tool privilege escalation
- Poisoned documents
- Metadata-filter failure
Do not average security into an answer-quality score. Some properties are gates: one reproducible cross-tenant leak can block release regardless of mean correctness.
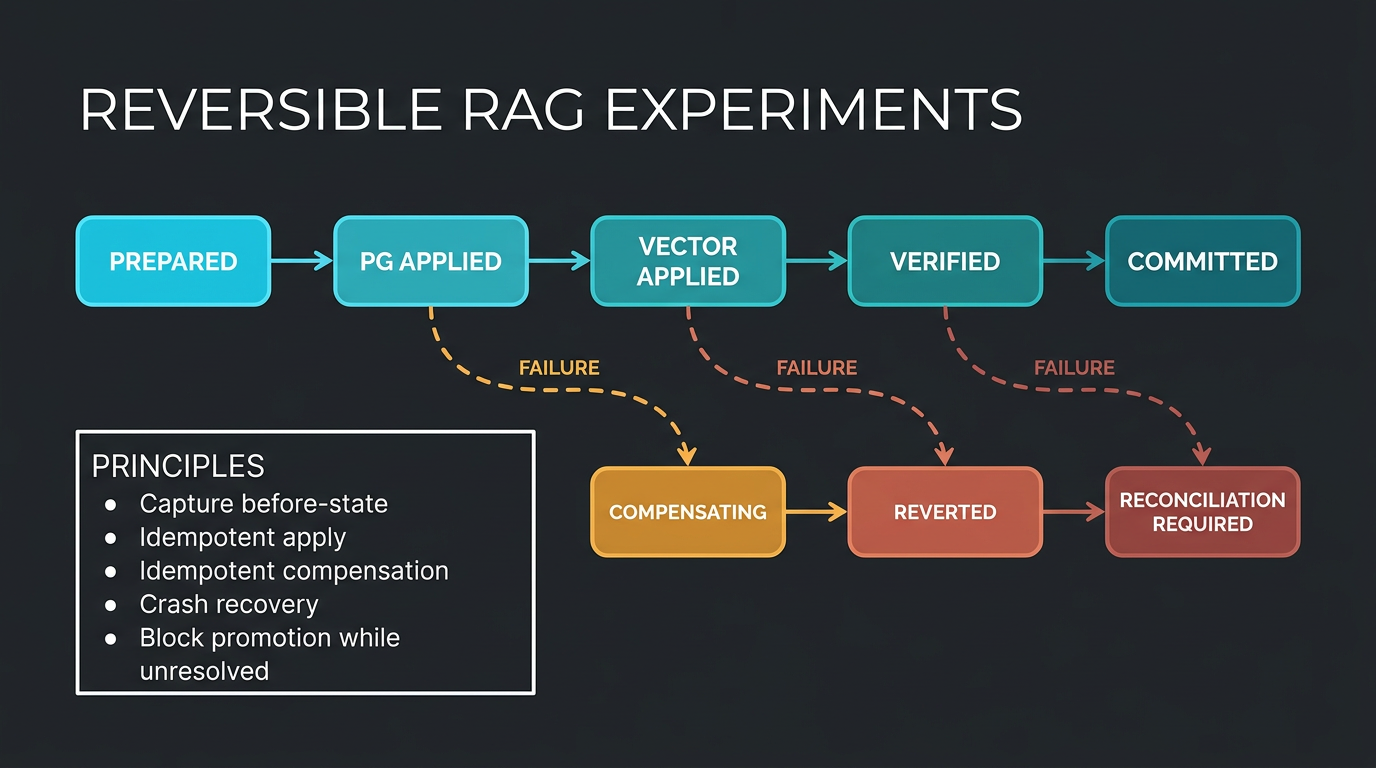
11. Automated improvement needs reversible experiments
Once a flywheel mutates prompts, knowledge records, relational state and vector entries, rollback becomes a distributed-systems problem. PostgreSQL and a vector database do not share one native transaction.
Microsoft’s Saga pattern describes a sequence of local transactions with compensating transactions when a later step fails. Applied to RAG experimentation, the principle is simple:
- Capture the complete before-state.
- Make apply and compensation idempotent.
- Persist each transition.
- Recover after crashes.
- Provide reconciliation when compensation fails.
- Block promotion whilst reconciliation is pending.
For a first controlled experiment, avoid mutating knowledge or vectors. Use an isolated code branch, immutable manifests and Git rollback. Build cross-store compensation only after the evaluator has demonstrated that it can detect a real improvement.
See Microsoft’s Saga distributed transactions pattern for the underlying engineering model.
12. How much evaluation rigour do you actually need?
Not every prototype requires a sealed expert holdout, repeated trials and sentence-level provenance. Evaluation depth should follow risk, especially the impact of a wrong answer and how easily a user can detect it.
| Error impact | Detectability | Evaluation posture |
|---|---|---|
| Low | High | Lightweight regression suite and user feedback |
| Low | Low | Production sampling and grounding checks |
| High | High | Expert validation and release gates |
| High | Low | Sealed validation, provenance, abstention, reliability trials and human oversight |
The most dangerous RAG systems are not merely those with costly errors. They are systems where costly errors sound exactly like correct answers.

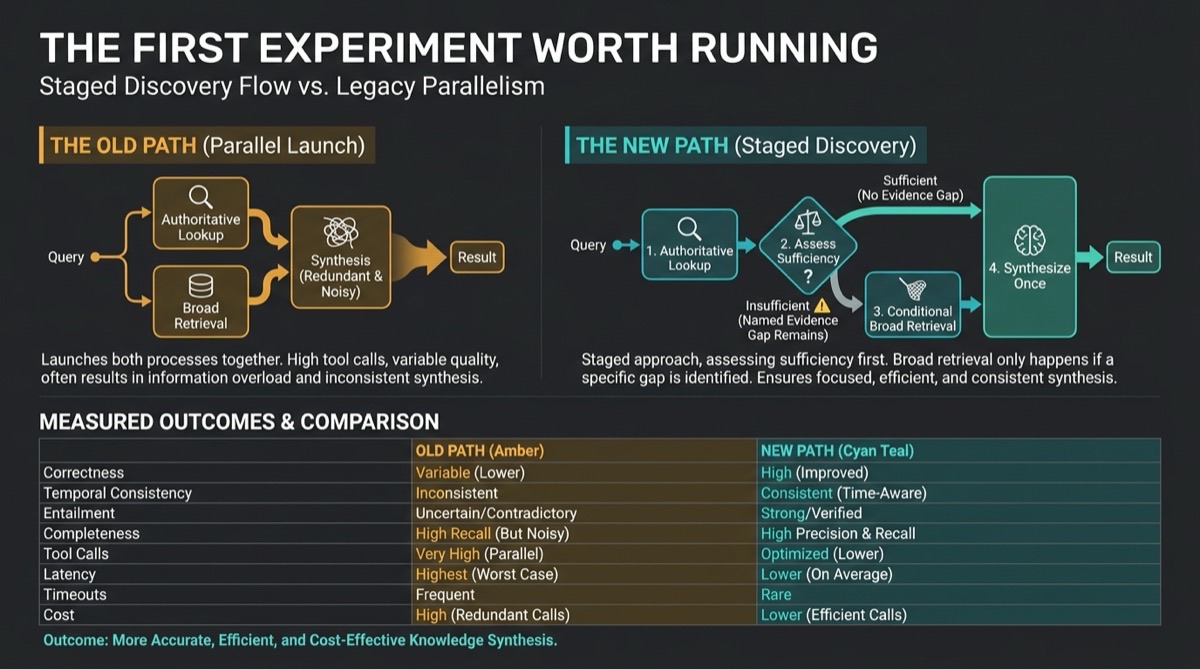
13. The first experiment worth running
Do not begin by automating a giant optimisation campaign. Begin with one mechanism whose effect is observable.
A strong pilot hypothesis is:
Assess authoritative lookup evidence before launching broad semantic retrieval. This should reduce historical contamination and redundant calls without reducing correctness or coverage.
Why this is a good first experiment:
- The treatment is narrow.
- The expected mediators are visible in tool traces.
- The failure mode is understandable: broad retrieval may introduce topically relevant but temporally or hierarchically wrong material.
- The benefit is testable across quality and operations.
- The change can be isolated in code without mutating the knowledge stores.
Measure legal or domain correctness, temporal correctness, claim-to-source entailment, completeness, fallback rate, tool calls, p50/p95 latency, timeout rate and cost. Use frozen-plan discovery to test the mechanism, then full-live runs to test production behaviour. If the effect does not repeat on fresh validation, stop. Infrastructure is not evidence.
14. A reusable RAG evaluation curriculum
For every metric or control, teach and document the same ten questions:
- What is it?
- Why does it matter?
- What failure does it detect?
- What exactly does it measure?
- What does it not measure?
- What are its advantages?
- What are its costs and limitations?
- When should it be used?
- What is a worked counterexample?
- How is it operated and reviewed?
This repeated structure matters for both people and AI systems. It prevents a metric definition from being learned without its limitations, and it prevents an operational recommendation from being repeated as universal scientific law.

What to check right now
- Label the suites: identify exposed development, promotion validation, shadow holdout and complete regression sets.
- Group correlated questions: partition by proposition, passage, template family, entity and incident.
- Fix the denominator: every fixture must report pass, fail, error, not_run or stale.
- Trace synthesis evidence: record the exact evidence IDs and passages provided to generation.
- Test citations at claim level: citation presence is not entailment.
- Model time explicitly: enforce version and as-of constraints where applicability changes.
- Calibrate the judge: use human-labelled subtle errors and report disagreement.
- Separate eval modes: frozen trace, frozen plan and full live answer different questions.
- Report uncertainty: use paired comparisons, appropriate intervals and a predeclared minimum effect.
- Measure reliability: first-answer success, repeated-answer variance, timeouts and tail latency.
- Keep security separate: access and prompt-injection failures are release gates.
- Start with one pilot: prove measurement truth before automating optimisation.
Source map: finding, principle or recommendation?
The article deliberately uses three evidence levels:
- Research findings: RAGAS, RAGVUE, SeedRG, VeriCite, small-eval statistics and temporal statutory QA.
- Established engineering principles: holdout discipline and Saga compensation.
- Proposed operating defaults: the four-set governance model, three diagnostic modes and the staged-discovery pilot. These are recommendations derived from the evidence, not claims that every project must use identical thresholds or trial counts.
The conclusion is deliberately narrower than “benchmarks are useless.” Benchmarks are indispensable. A regression suite preserves memory. A validation set tests promotion. A shadow holdout estimates generalisation. Production sampling tests relevance. Grounding traces explain why an answer deserves trust. The error is asking one green number to perform all five jobs.
Your RAG benchmark is not lying because it reports a score. It lies only when the organisation lets that score claim more than the experiment measured.
nJoy 😉