
Every prompt that hits your API is not created equal, but your billing statement treats them as if they are. A twenty-token label extraction and a three-thousand-token reasoning trace cost the same per token at the same endpoint. That means every routing decision you do not make is implicitly a decision to use your most expensive capable model for everything – including the work that does not need it.
Task-tier routing is the fix: a thin layer between your application and the model pool that dispatches each request to a model whose capability (and cost) matches the job. Build it yourself in middleware, use a cascade, or adopt a managed semantic router. The architecture is the same across all three. Only the operational burden differs.
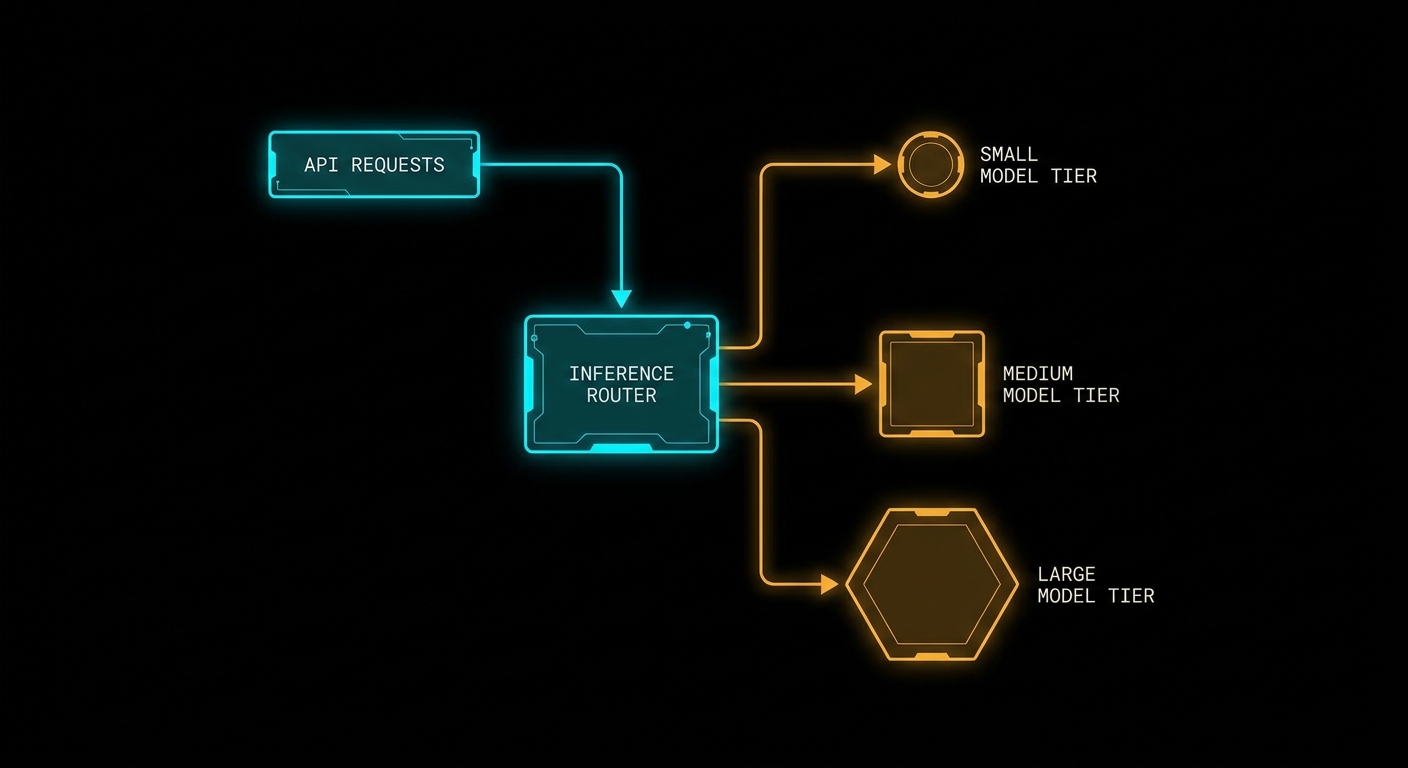
The One-Model Bill
Most production backends have at least three distinct call shapes running in parallel, even when they do not know it. Consider a realistic example:
- Labelling – short text in, a single category token out. The model needs vocabulary and context, not deep reasoning.
- Conversational answers – multi-turn prose, user-visible, tone-sensitive. Speed and coherence matter.
- Analysis – long working, structured output, citations. Quality matters more than cost per call.
When all three routes share one endpoint, the label call pays frontier model prices. Here is what that actually costs:
// $/1M tokens (illustrative - your provider rates will differ, ratios hold):
// Small instruct: $0.10 input / $0.30 output
// Frontier chat: $3.00 input / $15.00 output
// Reasoning-class: $1.25 input / $10.00 output
//
// Label call (~120 input tokens, 20 output tokens):
// Small model: ~$0.000018
// Frontier model: ~$0.000660 (~37x more expensive)
//
// At 500,000 label calls per month:
// Small model: ~$9
// Frontier model: ~$330 -- on one call type alone
That waste never appears as a line item. It hides inside one aggregate model spend figure, which is why most teams only discover it when they go looking.
“Through extensive experiments, we demonstrate that when compared to standalone expert models, TO-Router improves query efficiency by up to 40%, and leads to significant cost reductions of up to 30%, while maintaining or enhancing model performance by up to 10%.” — Stripelis et al., TensorOpera Router, EMNLP 2024
Three Ways to Decide Where a Prompt Goes
Each routing mechanism makes a different trade-off between latency overhead, implementation complexity, and accuracy.
Explicit routing. The caller tags its own request: a separate endpoint per task type, or a task field in the request body. Zero additional classifier latency, fully auditable, easy to debug. This is the right default when the caller already knows what kind of job it is sending – which is often the case in structured backends where each function in your code issues a specific type of prompt.
Content-based routing. A small classifier reads the prompt and matches it to a task description you maintain. Adds milliseconds to low seconds of overhead depending on model size, but keeps routing logic out of application code – useful when prompts arrive from users who do not specify intent. Crucially, task descriptions must describe the expected output shape, not the subject matter. “Return one label from: billing | bug | howto | account” will route correctly; “handle billing questions” will not.
Cascades. Send the prompt to the cheapest capable model first and escalate only when a confidence check fails. Yue et al. matched strong-model quality on reasoning benchmarks at approximately 40% of strong-model cost by escalating only when the weak model’s output showed low consistency across repeated samples.
“Through experiments on six reasoning benchmark datasets … we demonstrate that our proposed LLM cascades can achieve performance comparable to using solely the stronger LLM but require only 40% of its cost.” — Yue et al., arXiv:2310.03094
A Three-Tier Layout and Where It Breaks
A practical router uses three tiers: a small instruct model for extraction and labelling, a mid-tier chat model for interactive prose, and a reasoning-class model for deep analysis. The failure cases below are the ones that cause silent quality regressions or surprise cost spikes after initial deployment.
Case 1: Overlapping Task Descriptions Misroute Traffic
If two task descriptions could plausibly describe the same prompt, a semantic classifier will flip between tiers unpredictably or fall back to the default (usually the most expensive model). The problem is always in the description wording, not the classifier itself.
// Weak descriptions - both match "I have a billing question":
// label: "Handle user messages about the product"
// chat: "Help customers with billing"
//
// Strong descriptions - output contract, not subject:
// label: "Classify intent. Return exactly one token: billing|bug|howto|account"
// chat: "Write a helpful multi-sentence reply for the end user"
//
// The classifier routes on output shape, not topic.
// If you cannot write distinct output contracts, merge the tiers.
Case 2: Reasoning Paths Run Out of Completion Budget
Models that use extended thinking or chain-of-thought consume output tokens for reasoning before the visible answer. A 1024-token completion cap can yield empty visible content and a finish_reason: length response, with no error raised. On analysis-tier routes, treat 4096 tokens as a floor for the completion budget, not a ceiling.
Case 3: Switching Models Mid-Session Breaks Prefix Cache and Tone
When a multi-turn session starts on the mid-tier model and escalates to reasoning-class on turn three, two things break: the provider cannot reuse the cached prefix from the earlier turns (repaying full input cost), and the model’s response style may shift noticeably within one conversation. The fix is to pin a session to the model chosen on its first turn.
// Session-pinned routing in Node.js:
async function chat(sessionId, messages) {
// Look up the model assigned when this session started.
let tier = await sessionCache.get(sessionId);
if (!tier) {
// First turn: classify and persist.
tier = await classifyTaskTier(messages);
await sessionCache.set(sessionId, tier, { ttl: 3600 });
}
return invokeModel(tier, messages);
}
// Result: consistent prefix cache, consistent voice.
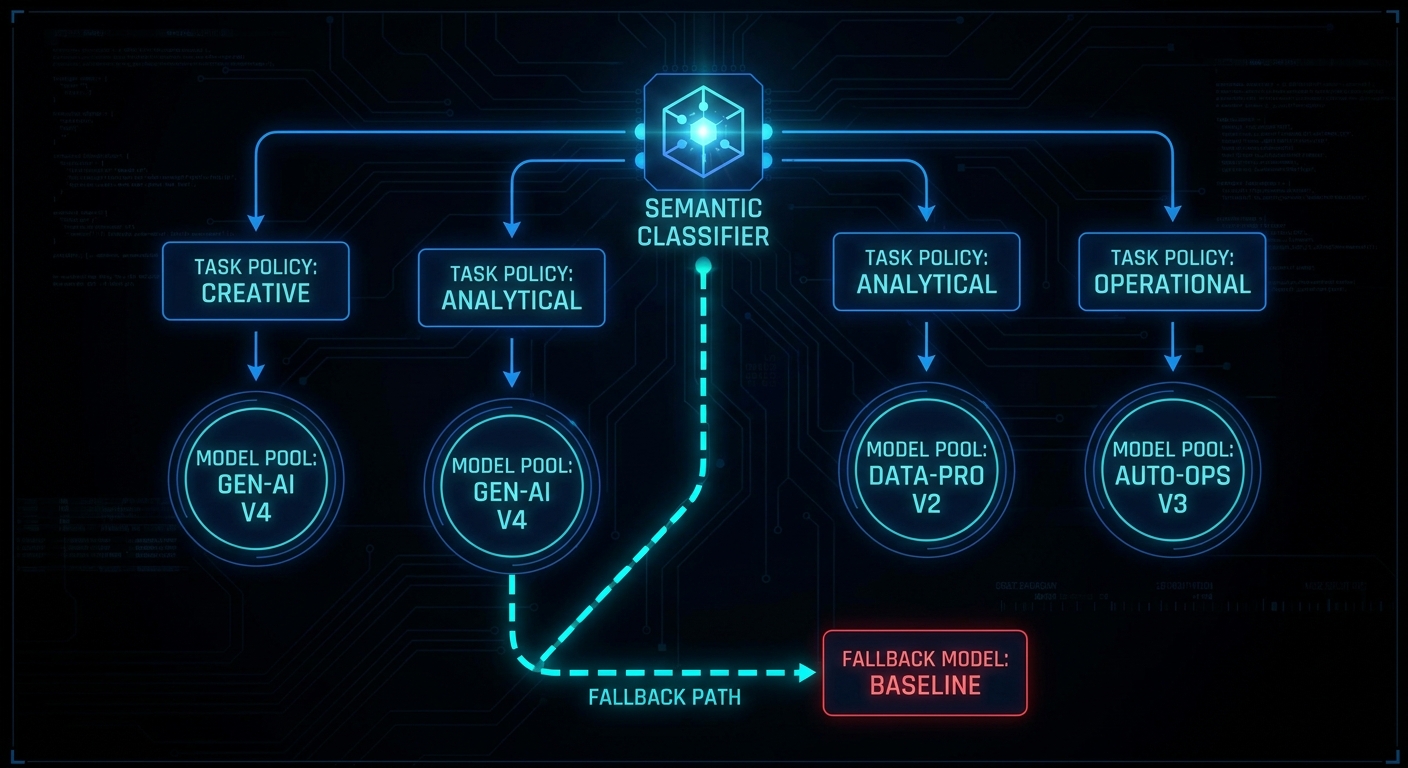
Selection Policies Inside Each Tier
Choosing a tier is half the decision. Within each tier you still need a policy for picking among multiple available models:
- Cheapest acceptable for labelling and extraction – quality differences between small models are negligible for binary classification.
- Lowest TTFT for interactive UI – a 200 ms response gap is noticeable to users; a 5% quality difference is not.
- Fixed priority list when you have a ranked preference (try provider A, fall back to B, then C on error).
- Cascade with confidence gate when most queries are easy but a long tail requires the flagship model – escalate only on low-confidence outputs from the cheaper tier.
Always define a fallback. Unmatched prompts should land on a cheap general model, not throw an error or silently route to the most expensive endpoint you have.
Telemetry You Actually Need
Without per-request logging, you cannot separate routing savings from a natural shift in traffic mix. Log these fields for every request: matched tier, serving model, tokens in, tokens out, estimated cost, TTFT, and total latency. After a week, plot cost-per-task-type before and after routing. That is the only number that proves the router is doing its job.
When to Skip Routing Altogether
Routing adds a moving part that requires calibration and monitoring. Skip it when:
- Every call genuinely needs the same capability – there is no cheaper model that passes your quality bar.
- Monthly spend is too small to justify the operational overhead of maintaining task descriptions.
- Your compliance requirements demand deterministic, explainable model selection for every request (use explicit endpoint tagging instead).
- You have not yet measured your actual task mix – routing based on assumptions rather than data will create more problems than it solves.
Rollout Without Surprises
- Sample first. Pull a week of production prompts and label them by task type manually. You need ground truth before building a classifier.
- Price the counterfactual. For each task type, calculate what it would cost at the cheaper tier. This is your upper-bound savings estimate.
- Eval the cheaper models on each task type before any traffic moves. Do not assume quality is adequate; measure it.
- Shadow-route. Run the router in logging-only mode: record decisions and estimated costs, but still serve the original model. Catch misroutes before they affect users.
- Canary 5% of live traffic. Watch real cost and quality metrics for a week before full cutover.
What to Check Right Now
- Task mix histogram from last week’s logs – if you do not have one, that is the first step.
- Retrospective cost estimate – what would tiered routing have cost versus what you actually spent?
- Task description overlap if you are already using or planning semantic routing.
- Completion token floors on any analysis or reasoning path – check that
max_tokensis not silently truncating outputs.
The waste is invisible until you look for it. Once you see the histogram of task types against the tier each one actually needed, it is very hard to unsee.
nJoy 😉