Your monolithic Apache-PHP-MySQL server from 2009 is still alive. It is held together with cron jobs, a hand-edited httpd.conf, and the quiet prayers of a sysadmin who has since left the company. You know exactly who you are. The good news: Docker will not judge you. It will just containerise the whole mess and make it someone else’s problem in a much more structured way.
Containerising legacy applications is one of the most practically impactful things you can do for an ageing system short of a full rewrite. This guide walks you through the entire process: why it matters, the mechanics of Dockerfiles and networking, persistent data, security, and a real end-to-end example lifting a CRM stack off bare metal and into containers. No hand-waving. Let’s get into it.
Why Bother? The Case Against “If It Ain’t Broke”
The classic argument for leaving legacy systems alone is that they work. True, but so did physical post. The problem is not what the system does today; it is what happens the next time you need to update a dependency, onboard a new developer, or scale under load. Hunt and Thomas put it well in The Pragmatic Programmer: the entropy that accumulates in software systems compounds over time, and the cost of ignoring it is paid with interest.
Containers solve three compounding problems simultaneously. First, environment uniformity: the application and every one of its dependencies are packaged together, so “it works on my machine” becomes a meaningless sentence. The container you run on your laptop is structurally identical to the one in production. Second, horizontal scalability: containers start in milliseconds, not the several seconds a VM needs. That gap matters enormously when a load spike hits at 2 am. Third, deployment speed and rollback: shipping a new version is swapping an image tag. Rolling back is swapping it back. No more change-freeze weekends.
The shift from physical servers to VMs already multiplied the number of machines we managed. Containers take that abstraction one step further: a container is essentially a well-isolated process sharing the host kernel, with no hypervisor overhead. Docker’s contribution was not inventing that idea; it was making the developer experience smooth enough that everyone actually used it.
The Dockerfile: Your Application’s Constitution
A Dockerfile is a recipe. Each instruction adds a layer to the resulting image; Docker caches those layers, so rebuilds after small changes are fast. Consider a Python Flask application that was previously deployed by SSH-ing into a server and running python app.py inside a screen session (we have all seen this):
# app.py
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello_world():
return 'Hello, World!'
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)The Dockerfile that containerises it:
FROM python:3.11-slim
WORKDIR /app
COPY requirements.txt /app/
RUN pip install --no-cache-dir -r requirements.txt
COPY . /app/
CMD ["python", "app.py"]Build and run:
docker build -t my-legacy-app .
docker run -p 5000:5000 my-legacy-appThat is it. The application now runs in an isolated environment reproducible on any machine with Docker installed. The FROM python:3.11-slim line pins the runtime; no more implicit dependency on whatever Python version happens to be installed on the server. Knuth would approve of the precision.

Networking: Containers Talking to Containers
Single-container deployments are the easy case. Legacy applications rarely are that simple; they almost always involve a web server, an application layer, and a database. Docker’s networking model needs to be understood before you wire them together.
The most basic scenario is exposing a container port to the host with the -p flag:
docker run -d -p 8080:80 --name web-server nginxPort 8080 on the host routes into port 80 inside the container. Straightforward. For inter-container communication, the old approach was --link, which is now deprecated. The correct approach is a user-defined bridge network:
docker network create my-network
docker run -d --network=my-network --name my-database mongo
docker run -d --network=my-network my-web-appWithin my-network, containers resolve each other by name. my-web-app can reach the Mongo instance at the hostname my-database. Docker handles the DNS. For anything beyond a pair of containers, Docker Compose is the right tool:
services:
web:
image: nginx
networks:
- my-network
database:
image: mongo
networks:
- my-network
networks:
my-network:
driver: bridgeOne docker compose up and the entire topology comes up, networked and named correctly. One docker compose down and it evaporates cleanly, which is more than you can say for that 2009 server.
Volumes: Because Containers Are Ephemeral and Databases Are Not
A container’s filesystem dies with the container. For stateless web processes, that is fine. For a database, it is a disaster. Volumes are Docker’s answer: they exist independently of any container and survive container restarts and deletions.
Three flavours. Anonymous volumes are created automatically:
docker run -d --name my-mongodb -v /data/db mongoNamed volumes give you control:
docker volume create my-mongo-data
docker run -d --name my-mongodb -v my-mongo-data:/data/db mongoHost volumes mount a directory from the host machine directly:
docker run -d --name my-mongodb -v /path/on/host:/data/db mongoHost volumes are useful for development, where you want live code reloading. For production databases, named volumes are the right choice. In Docker Compose, the volume declaration is clean:
services:
database:
image: mongo
volumes:
- my-mongo-data:/data/db
volumes:
my-mongo-data:One practical note on databases: you do not have to containerise them at all. Running a containerised web layer against an AWS RDS instance is a perfectly legitimate architecture. Amazon handles provisioning, replication, and backups; you handle the application. The common pattern is a containerised database in local development (spin up, load test data, tear down without ceremony) and a managed database service in production. Your application connects via the same protocol either way.
Configuration and Environment Variables: Don’t Hard-Code Secrets
Legacy applications often have configuration scattered across a dozen INI files, some environment variables, and several values that someone once hard-coded “just temporarily” in 2014. Docker gives you structured ways to handle all of it.
For immutable build-time config, use ENV in the Dockerfile:
FROM openjdk:11
ENV JAVA_HOME /usr/lib/jvm/java-11-openjdk-amd64For runtime config that varies per environment, use the -e flag or, better, a .env file:
# .env
DB_HOST=database.local
DB_PORT=3306docker run --env-file .env my-applicationIn Docker Compose with variable substitution across environments:
services:
my-application:
image: my-application:${TAG:-latest}
environment:
DB_HOST: ${DB_HOST}
DB_PORT: ${DB_PORT}Never commit .env files containing passwords to a public repository. This is obvious advice that nonetheless appears in breach post-mortems with depressing regularity. Add .env to your .gitignore and use a secrets manager for production credentials.
For configuration files (Apache’s httpd.conf, PHP’s php.ini), mount them as volumes rather than baking them into the image. This keeps the image immutable and the configuration adjustable at runtime:
services:
web:
image: my-apache-image
volumes:
- ./my-httpd.conf:/usr/local/apache2/conf/httpd.confSecurity: Every Layer Counts
Containerisation improves security through isolation, but it introduces its own attack surface if you are careless. The Docker Unix socket at /var/run/docker.sock is effectively root access to the host; restrict who can reach it. Scan your images for known CVEs before deployment: docker scout cve my-image gives you a breakdown.
Do not run containers as root. Specify a non-root user in your Dockerfile:
FROM ubuntu:latest
RUN useradd -ms /bin/bash myuser
USER myuserDrop Linux capabilities you do not need and add back only what the container requires:
docker run --cap-drop=all --cap-add=net_bind_service my-applicationMount sensitive data read-only:
docker run -v /my-secure-data:/data:ro my-applicationInstrument containers with Prometheus and Grafana or the ELK stack. Unexpected outbound traffic or CPU spikes in a container are worth knowing about in real time, not in the morning post-mortem.
Real-World Example: Dockerising a Legacy CRM
This is where it gets concrete. Suppose you have a CRM system running on a single aging physical server: Apache serves the web layer, PHP handles the application logic, MySQL stores the data. The components are tightly coupled, share the same filesystem, and have never been deployed anywhere else. Every update involves downtime.
The migration follows six steps.
Step 1: Isolate components. Decouple Apache first by introducing NGINX as a reverse proxy routing to a separate Apache process. Move the MySQL database to a separate instance. Identify shared libraries or PHP extensions that need to be present in the isolated environments. Use mysqldump to migrate data consistently:
mysqldump -u username -p database_name > data-dump.sql
mysql -u username -p new_database_name < data-dump.sqlIf sessions were stored locally on the filesystem, migrate them to a distributed store like Redis at this stage.
Step 2: Write Dockerfiles. One per component:
# Apache
FROM httpd:2.4
COPY ./my-httpd.conf /usr/local/apache2/conf/httpd.conf
COPY ./html/ /usr/local/apache2/htdocs/# PHP-FPM
FROM php:8.2-fpm
RUN docker-php-ext-install pdo pdo_mysql
COPY ./php/ /var/www/html/# MySQL
FROM mysql:8.0
COPY ./sql-scripts/ /docker-entrypoint-initdb.d/Step 3: Network and volumes. Create a user-defined bridge network and attach all containers to it. Bind a named volume to the MySQL container for data persistence:
docker network create crm-network
docker volume create mysql-data
docker run --network crm-network --name my-apache-container -d my-apache-image
docker run --network crm-network --name my-php-container -d my-php-image
docker run --network crm-network --name my-mysql-container \
-e MYSQL_ROOT_PASSWORD=my-secret \
-v mysql-data:/var/lib/mysql \
-d my-mysql-imageOr, the cleaner Compose version:
services:
web:
image: my-apache-image
networks:
- crm-network
php:
image: my-php-image
networks:
- crm-network
db:
image: my-mysql-image
environment:
MYSQL_ROOT_PASSWORD: my-secret
volumes:
- mysql-data:/var/lib/mysql
networks:
- crm-network
networks:
crm-network:
driver: bridge
volumes:
mysql-data:Step 4: Configuration management. Move all credentials and environment-specific values into a .env file. Mount Apache and PHP configuration files as volumes so they can be adjusted without rebuilding images. Use envsubst to populate configuration templates at container startup rather than hard-coding values.
Step 5: Testing. Run functional parity tests against both the legacy and dockerised environments in parallel using Selenium for the web UI and Postman for any API surfaces. Load test with Apache JMeter or Gatling. Run OWASP ZAP for dynamic security scanning; it dockerises cleanly and can be dropped into a CI pipeline. Have a rollback plan before you touch production.
Step 6: Deploy. Push images to Docker Hub or a private registry. In production, a container orchestration layer like Kubernetes takes over from Docker Compose, but the images are identical. The operational model becomes declarative: you describe the desired state, and the orchestrator keeps reality matching the declaration. Kleppmann's treatment of distributed systems consensus in Designing Data-Intensive Applications is useful background if you are stepping into Kubernetes territory.
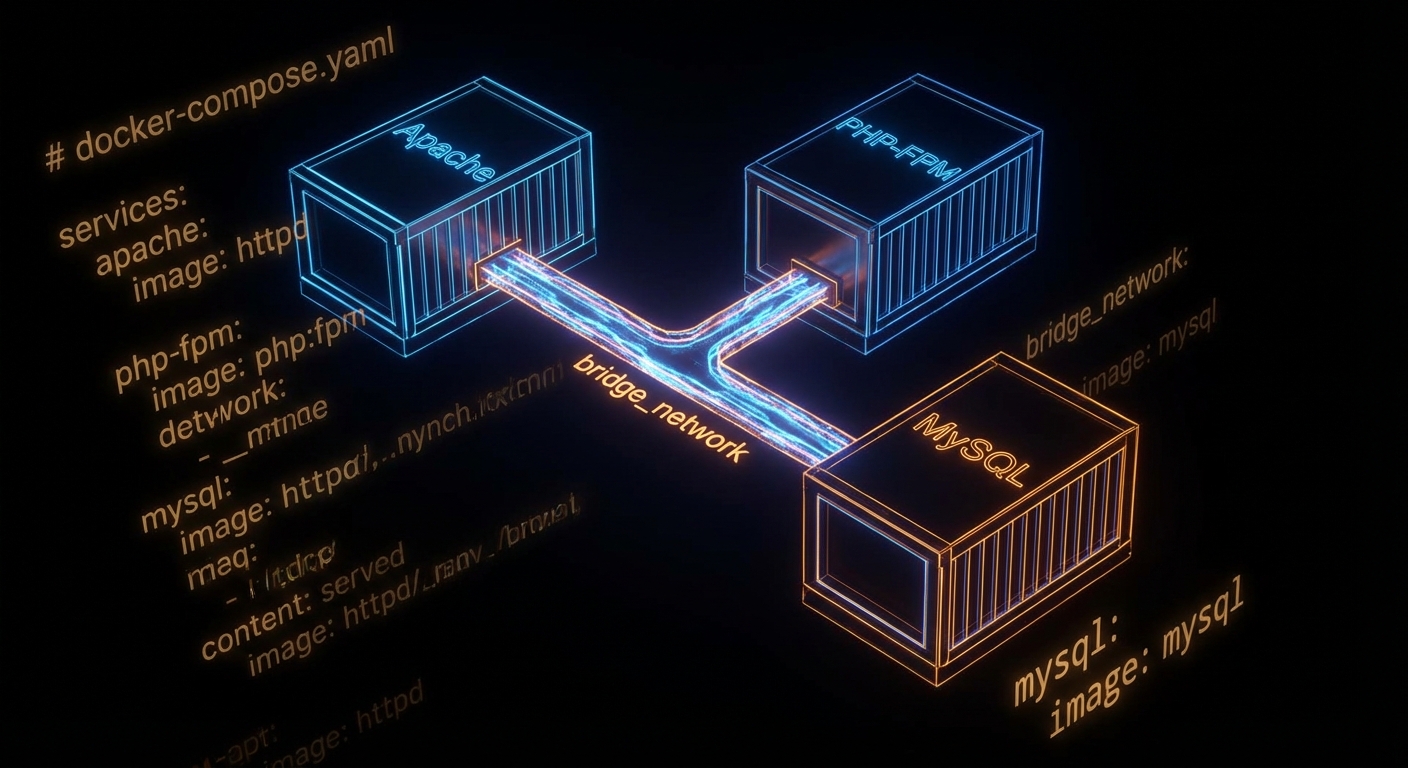
docker-compose.yml describes the entire legacy CRM stack: web, PHP, and database, all networked and persistent.What to Watch Out For
- Image bloat — start from
-slimor-alpinebase images. A 1.2 GB image that could be 120 MB is a pull-time tax on every deployment. - Secrets in layers — every
RUNinstruction creates a layer. If youCOPYa file with credentials and thenRUN rmit, the credentials are still in the layer history. Use multi-stage builds or external secret injection. - Running as root — the default. Don't. Add a non-root user in the Dockerfile and switch to it before
CMD. - Ignoring the
.dockerignorefile — equivalent to.gitignorefor build contexts. Without it, you send your entire project directory (includingnode_modules,.git, and that test database dump) to the Docker daemon on every build. - Ephemeral config confusion — containers are immutable; config should not live inside them. If you are
docker exec-ing into containers to tweak config files, you are doing it wrong and the next restart will undo everything. - Skipping health checks — add a
HEALTHCHECKinstruction so orchestrators know when a container is actually ready, not just started.
nJoy 😉