
Pick one flagship model, point every API call at it, and your integration story stays simple. Your finance story does not. A twenty-token label extraction and a three-thousand-token reasoning trace should not share the same price tier, yet most backends bill them identically because the endpoint is identical.
Task-tier routing fixes the mismatch: a thin layer between your app and the model pool that sends each prompt to capability (and cost) proportional to the job. Build it yourself in middleware, use a cascade, or buy a managed semantic router. The shape is the same; only the ops burden differs.
The One-Model Bill
Picture a backend with three call shapes that coexist in production:
- Labelling — short text in, single category out.
- Conversational answers — multi-turn, user-visible prose.
- Analysis — long working, detailed output.
Illustrative economics (your provider rates will differ; ratios hold):
// $/1M tokens (illustrative):
// Small instruct: $0.10 in / $0.30 out
// Frontier chat: $3.00 in / $15.00 out
// Reasoning-class: $1.25 in / $10.00 out
//
// Label call (~120 in / 20 out):
// Small: ~$0.000018
// Frontier: ~$0.000660 (~37×)
//
// At 500k labels/month: ~$9 vs ~$330 on that path alone
The waste never appears as “mis-routing fee” on an invoice. It hides inside one model line item.
“Through extensive experiments, we demonstrate that when compared to standalone expert models, TO-Router improves query efficiency by up to 40%, and leads to significant cost reductions of up to 30%, while maintaining or enhancing model performance by up to 10%.” — Stripelis et al., TensorOpera Router, EMNLP 2024
Three Ways to Decide Where a Prompt Goes
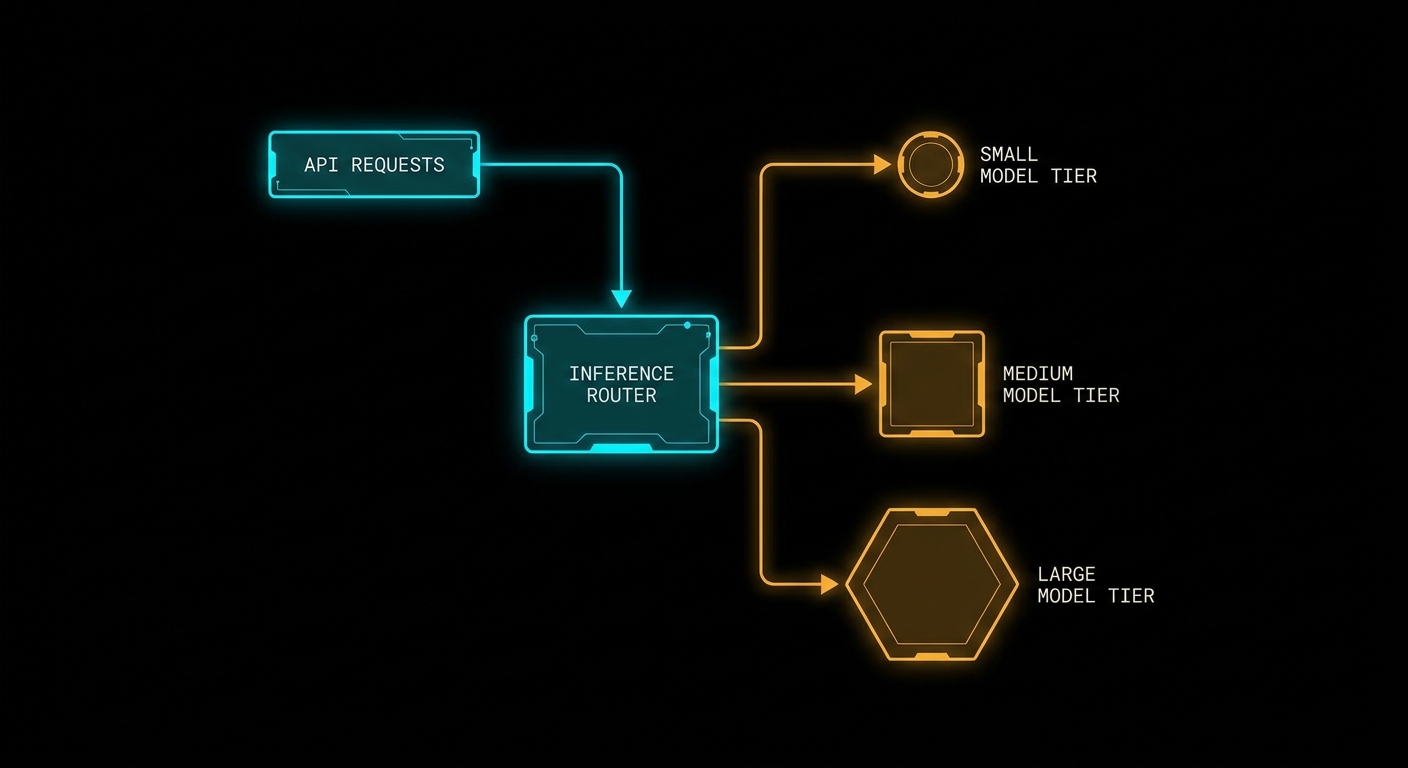
Explicit routing. Client sends task=classify or hits /api/classify. Zero classifier latency, fully auditable. Best when the caller already knows the job type.
Content-based routing. A small classifier matches prompt text to task descriptions you maintain. Adds milliseconds to seconds of overhead but keeps routing out of application code. Descriptions must describe output shape (“return one label”) not topic (“handle billing”).
Cascades. Cheap model first; escalate only when confidence checks fail. Yue et al. matched strong-model quality on reasoning benchmarks at ~40% of strong-model spend using consistency-based escalation.
“Through experiments on six reasoning benchmark datasets … we demonstrate that our proposed LLM cascades can achieve performance comparable to using solely the stronger LLM but require only 40% of its cost.” — Yue et al., arXiv:2310.03094
A Three-Tier Layout That Maps to Real Backends
Case 1: Overlapping Task Descriptions Misroute Traffic
“Answer questions about the product” matches nearly everything. The classifier flips between tiers or hits fallback. Fix: narrow descriptions to output contract, not subject matter.
// Weak:
// label: "Handle user messages"
// chat: "Help with the product"
//
// Strong:
// label: "Emit one token from: billing|bug|howto|account"
// chat: "Write a helpful multi-sentence reply for the end user"
Case 2: Reasoning Paths Run Out of Completion Budget
Models that think before they answer burn completion tokens invisibly. A 1024-token cap can yield empty content and finish_reason: length. Treat 4096 as a floor on analysis paths.
Case 3: Switching Models Mid-Session Breaks Prefix Cache
Turn three on a different model than turn one re-pays full input context and can change tone. Pin sessions to the first chosen model; store sessionId → model in your middleware.
// Node.js sketch:
async function chat(sessionId, messages) {
let tier = cache.get(sessionId);
if (!tier) {
tier = await classify(messages);
cache.set(sessionId, tier);
}
return invoke(tier, messages);
}
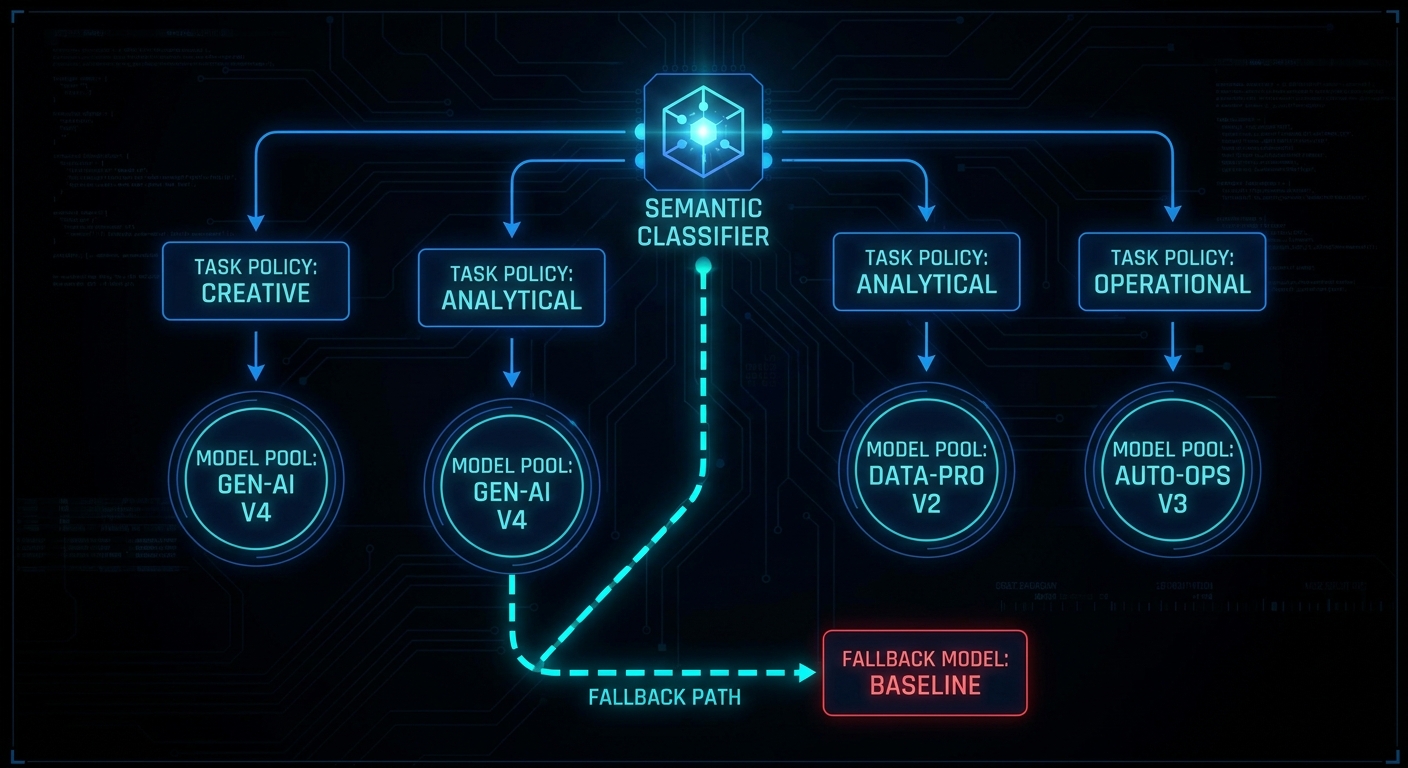
Policies Inside Each Tier
- Cheapest acceptable for labelling and extraction.
- Fastest TTFT for interactive UI.
- Fixed priority list when quality order is fixed (A, then B, then C).
- Cascade with confidence gate when most queries are easy but tails are hard.
Always define a fallback model. Unmatched prompts should land on a cheap general model, not error or silently upgrade.
Telemetry You Actually Need
Per request, log: matched tier, serving model, tokens in/out, estimated cost, TTFT, total latency. Without that, you cannot tell whether savings came from routing or from traffic mix shifting.
Skip Routing When
- Every call needs the same capability.
- Monthly spend is too small to justify router ops.
- Audit requires deterministic, explainable model choice (use explicit tags).
- You have not measured task mix yet.
Rollout Without Surprises
- Sample production prompts; label task type manually.
- Price what each tier would have cost retrospectively.
- Eval cheaper models per task before cutover.
- Shadow-route: log decisions, still serve old path.
- Canary 5% live traffic; watch cost and quality.
What to Check Right Now
- Task mix histogram from last week’s logs.
- Cost if everything stayed on frontier vs tiered estimate.
- Task description overlap if using semantic routing.
- Completion token floors on any analysis/reasoning path.
nJoy 😉