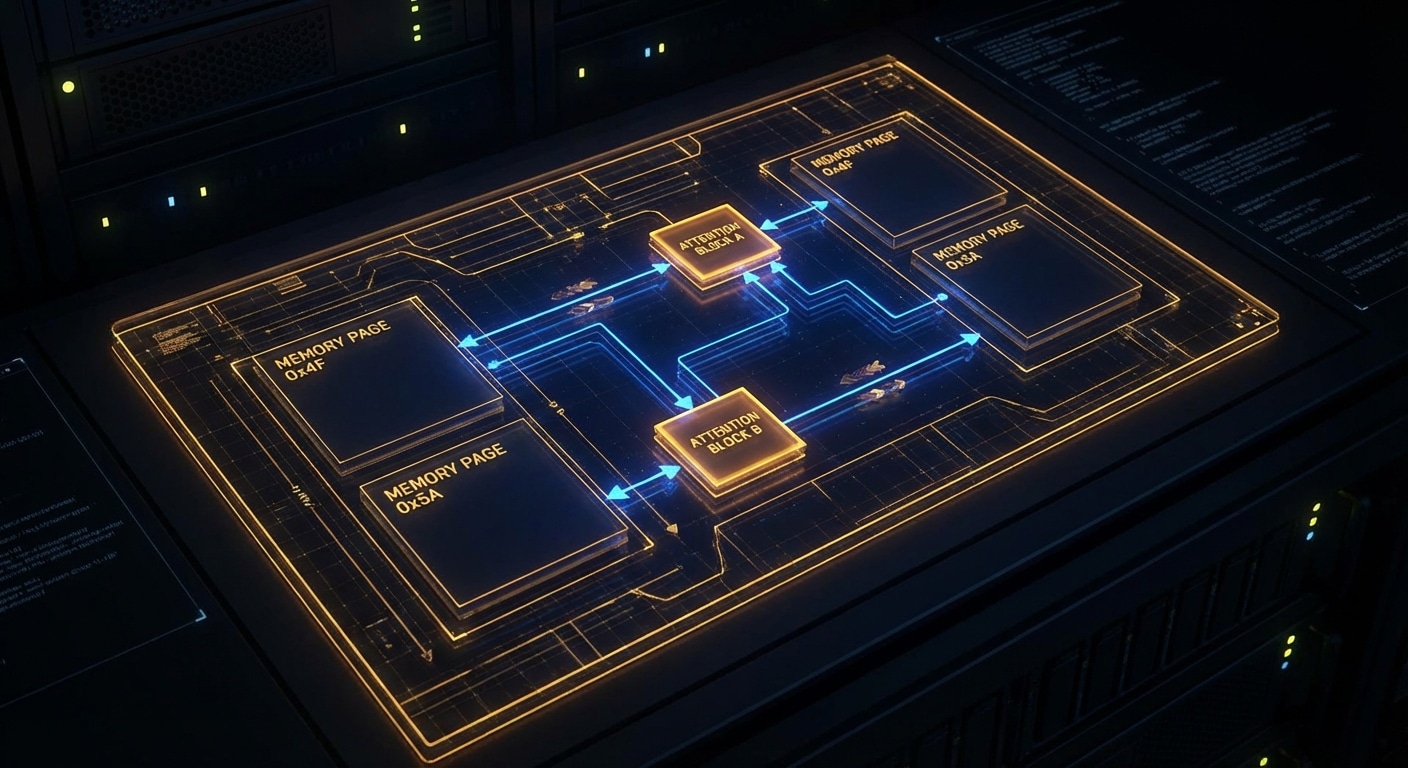
Early LLM APIs hit a wall: GPUs had plenty of compute, but memory for the “KV cache”, the key and value tensors that attention uses for long contexts, fragmented and wasted space. Different requests had different sequence lengths, so pre-allocating a block per request either ran out of memory or left big holes. vLLM’s insight was to borrow an idea from operating systems: paging. Treat the KV cache as a heap of fixed-size blocks and allocate only what each request actually needs. That one change drove huge gains in throughput and made long-context serving practical.
PagedAttention works like virtual memory. The logical KV cache for a sequence is split into blocks. A request allocates blocks as it generates; when the request ends, blocks go back to a pool. No more worst-case allocation per request, and no fragmentation in the same way. The attention kernel then has to gather from these non-contiguous blocks, which vLLM does efficiently. The result is that you can pack many more concurrent requests onto one GPU, and latency stays predictable.
The rest of vLLM is built around this: continuous batching (add new requests and decode steps as they’re ready), CUDA graphs and custom kernels to reduce overhead, and an OpenAI-compatible API so existing clients and apps work. It’s open source and has become the default choice for many teams serving Llama, Mistral, and similar models in production.
You do pay a small cost: the gather step and block management add some complexity and a bit of overhead compared to a single-request path. For short, single-user use cases, a simpler engine might be fine. For multi-tenant APIs and high utilisation, PagedAttention is what makes the numbers work.
Expect more variants: different block sizes, eviction policies for “infinite” context, and tighter integration with quantized and speculative decoding.
nJoy 😉