

You Are Not Behind: The Race Nobody Told You Was Fake
You open Instagram at 11:47 pm. Someone your age just launched a company. Another one is living in Bali. A third just announced they hit...
Jun 25, 2026
You open Instagram at 11:47 pm. Someone your age just launched a company. Another one is living in Bali. A third just announced they hit...
Jun 25, 2026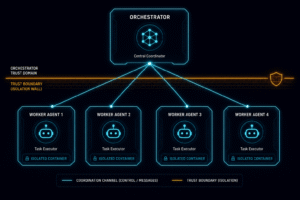
Six months ago, the question was “can we make agents work together?” We had topologies on whiteboards, coordination papers from Anthropic and Google, and a...
Jun 24, 2026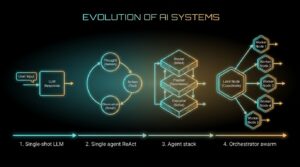
Two years ago, “AI” meant typing a prompt and getting text back. Today the same model might sit inside a loop that queries your database,...
Jun 24, 2026
Today is a good day at SudoAll. We launched Posterboy, our agentic publishing system for LinkedIn, and it feels like the site crossed a line...
Jun 24, 2026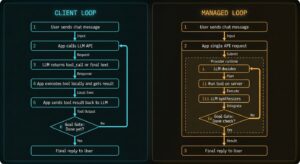
Models plan; code executes. The loop is non-negotiable: propose an action, run it, feed the result back, repeat until done. What is negotiable is where...
Jun 24, 2026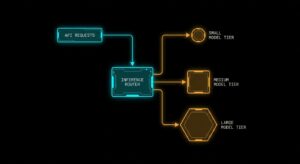
Every prompt that hits your API is not created equal, but your billing statement treats them as if they are. A twenty-token label extraction and...
Jun 24, 2026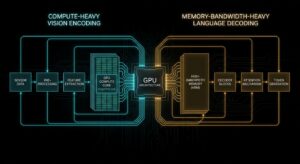
You shipped a vision-language model on the same GPU stack that served your text LLM. Same vLLM config, similar parameter count, no red alarms in...
Jun 24, 2026
Google just dropped a 31-billion-parameter model that sits on the same leaderboard row as Claude Sonnet 4.5 and outranks models 20 times its size. That...
Apr 3, 2026
Six months ago, the question was “can we make agents work together?” We had topologies on whiteboards, coordination papers from...
Jun 24, 2026
Two years ago, “AI” meant typing a prompt and getting text back. Today the same model might sit inside a...
Jun 24, 2026
Today is a good day at SudoAll. We launched Posterboy, our agentic publishing system for LinkedIn, and it feels like...
Jun 24, 2026
You shipped a vision-language model on the same GPU stack that served your text LLM. Same vLLM config, similar parameter...
Jun 24, 2026
FFmpeg is what happens when a Swiss Army knife gets a PhD in multimedia and then refuses to use a...

WordPress ships slow. Not broken-slow, but “a friend who takes 4 seconds to answer a yes/no question” slow. The default...
Redis is one of those tools you adopt on a Monday and depend on completely by Thursday. It’s fast, it’s...
For nmap to even make a guess, nmap needs to find at least 1 open and 1 closed port on...