
Visualisation from bbycroft.net/llm – Annotated with Nano Banana
Welcome to the LLM Architecture Series
This comprehensive 20-part series takes you from the fundamentals to advanced concepts in Large Language Model architecture. Using interactive visualisations from Brendan Bycroft’s excellent LLM Visualisation, we explore every component of a GPT-style transformer.
Series Overview
Part 1: Foundations (Articles 1-5)
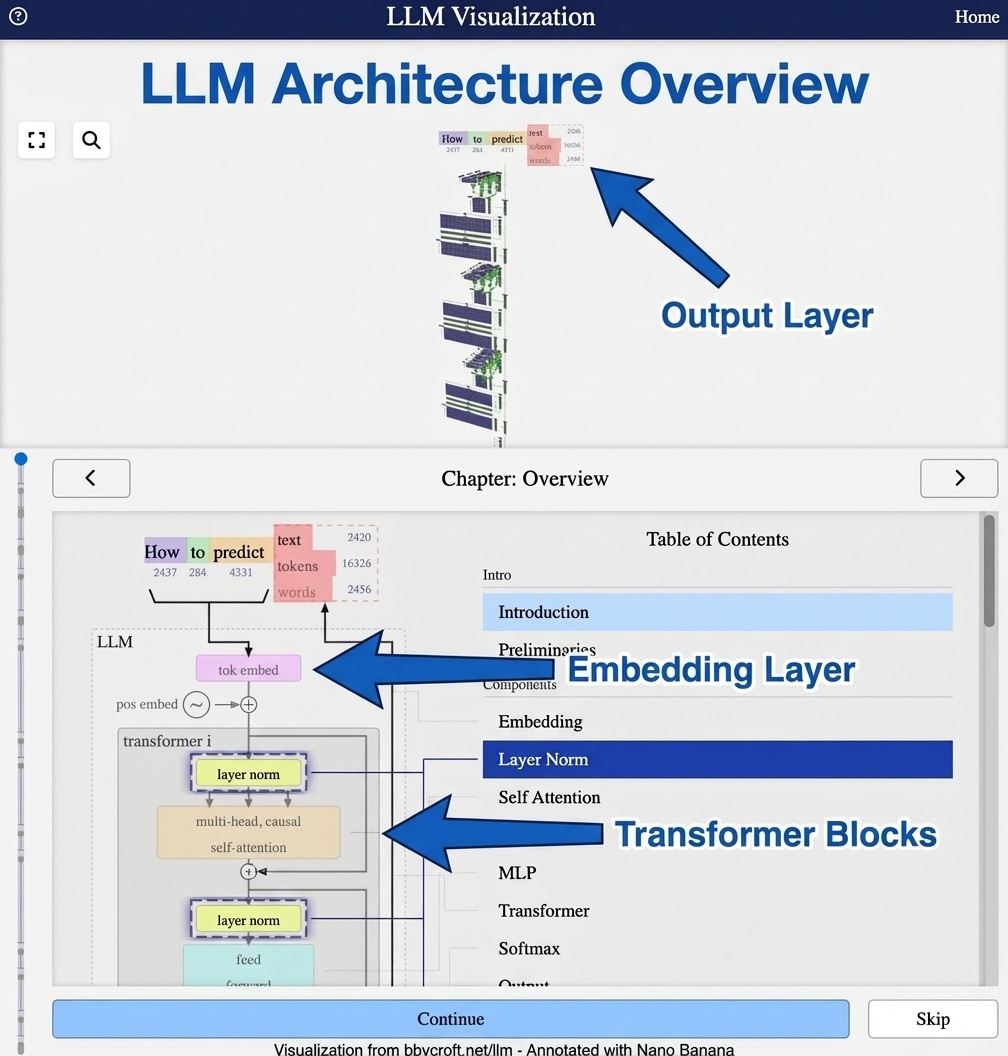
- Introduction to Large Language Models – What LLMs are and how they work
- Tokenization Basics – Converting text to tokens
- Token Embeddings – Converting tokens to vectors
- Position Embeddings – Encoding word order
- Combined Input Embedding – Putting it together
Part 2: The Transformer Block (Articles 6-14)
- Layer Normalisation – Stabilizing the network
- Self-Attention Part 1 – The core innovation
- Self-Attention Part 2 – Multi-head attention
- Query, Key, Value – The attention framework
- Causal Masking – Preventing future leakage
- Attention Softmax – Computing attention weights
- Projection Layer – Combining attention outputs
- Feed-Forward Networks – The MLP component
- Residual Connections – Skip connections for depth
Part 3: The Complete Model (Articles 15-20)
- Complete Transformer Block – All components together
- Stacking Layers – Building depth
- Output Layer – The language model head
- Output Softmax – From logits to probabilities
- Scaling LLMs – From nano-GPT to GPT-3
- Complete Pipeline – The full picture
About This Series
Each article includes:
- Interactive visualisations from bbycroft.net/llm
- Mathematical equations explaining each component
- Intuitive explanations of why each part matters
- Navigation links to previous and next articles
Start Learning
Begin with: Introduction to Large Language Models
Interactive visualisations courtesy of bbycroft.net/llm by Brendan Bycroft. Annotated images created with Nano Banana.