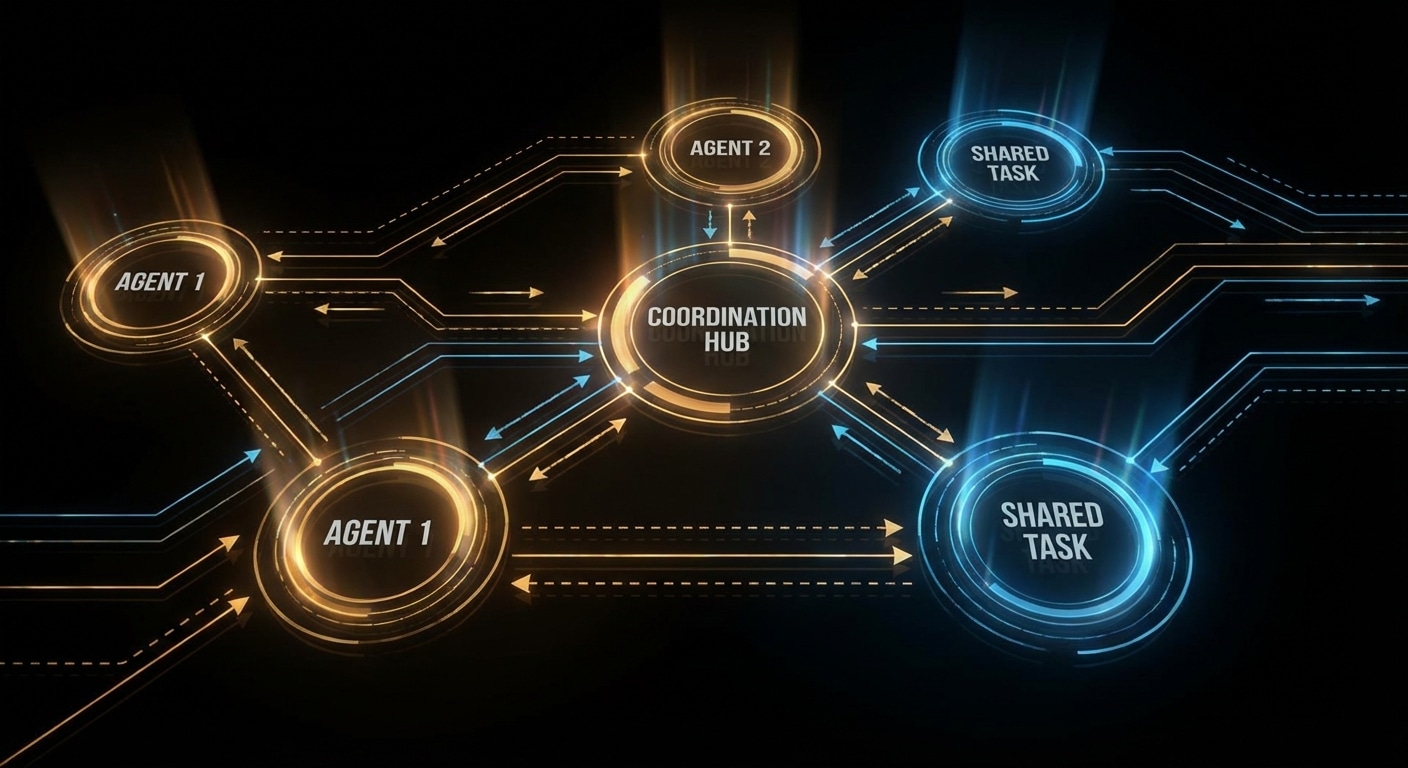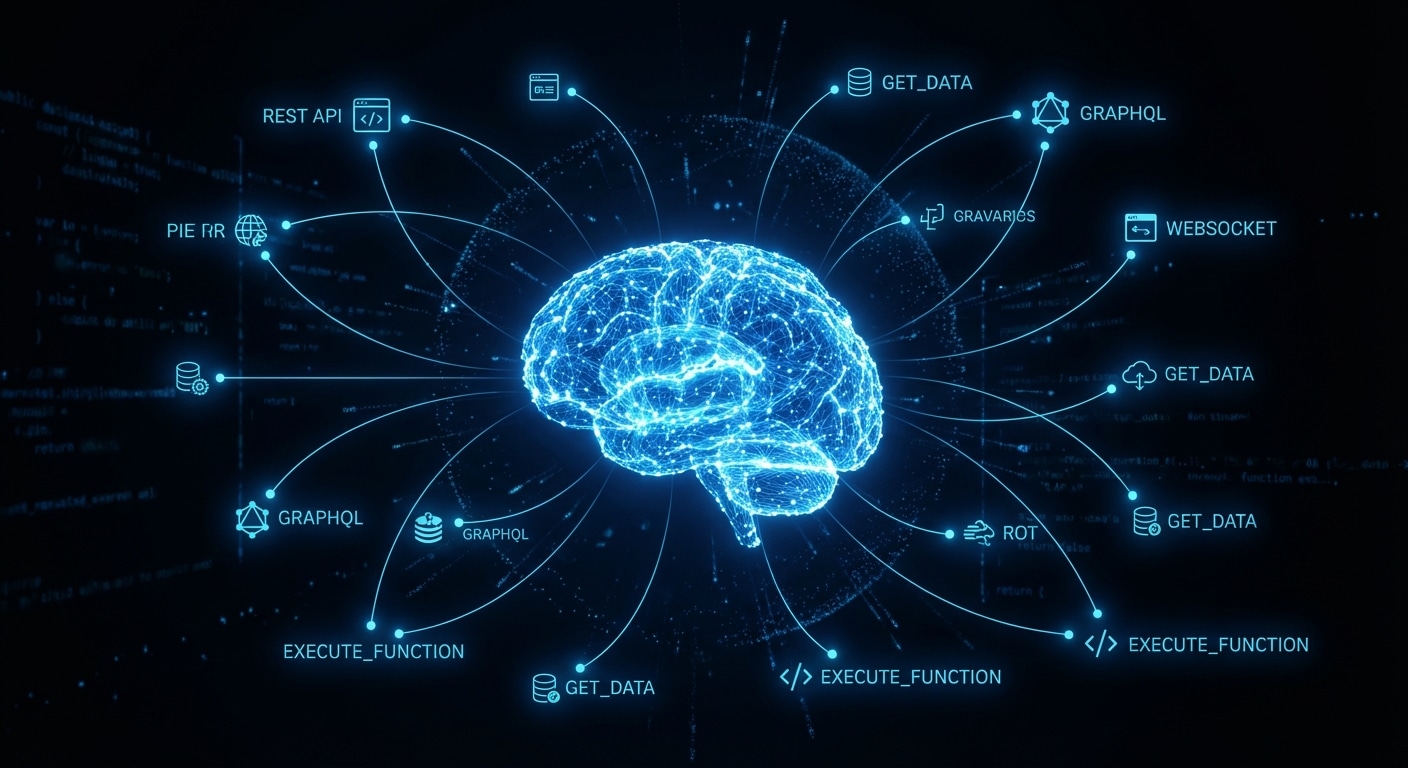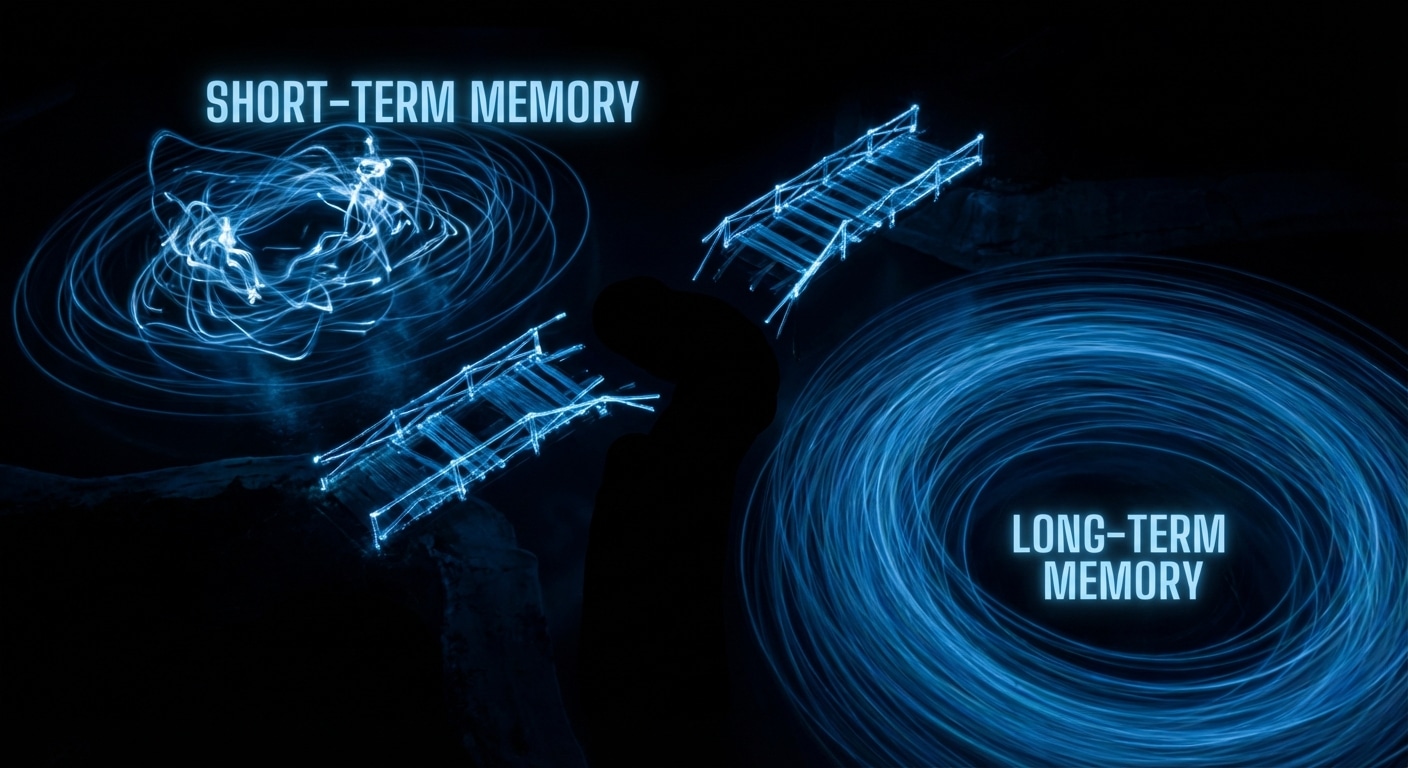
Agents have two kinds of “memory”: the context window (short-term) and everything else (long-term). Short-term is what you send in each request, the conversation so far, maybe a summary of older turns, plus any retrieved docs or tool results. That’s limited (e.g. 128K tokens) and expensive. Long-term would be a persistent store: facts about the user, past decisions, or project state that survives across sessions. Today most agents don’t have a real long-term memory; they get a fresh context each time or a hand-built “summary” that you inject.
The gap shows up when you want an agent that remembers your preferences, what it did last week, or the current state of a long project. Without long-term memory, you have to tell it again or rely on RAG over past transcripts. That works up to a point, but retrieval isn’t the same as “knowing”: the model might not get the right chunk or might contradict what it “remembered” before. True long-term memory would mean the agent updates a store (e.g. a knowledge graph or structured DB) and reads from it at the start of each run, still an open design problem.
Short-term is also a design choice: do you keep every message, or do you summarise old turns to save space? Summarisation loses detail; keeping everything hits context limits. Many systems use a sliding window plus a running summary. Tool results can be truncated or summarised too, so the model sees “the answer was X” instead of a 10K-character dump.
Until we have standard, reliable long-term memory, agents will stay best at single-session or well-scoped tasks. The progress will come from better retrieval, better summarisation, and eventually learned or hybrid memory that the agent can read and update safely.
Expect more work on agent memory architectures and on grounding agents in external state (databases, docs) as a stand-in for true long-term memory.
nJoy 😉