
LLM Architecture Series – Lesson 13 of 20. After attention and projection we pass each position through a feed forward network.
This multilayer perceptron applies the same small neural network to every position independently, adding powerful non linear transformations.
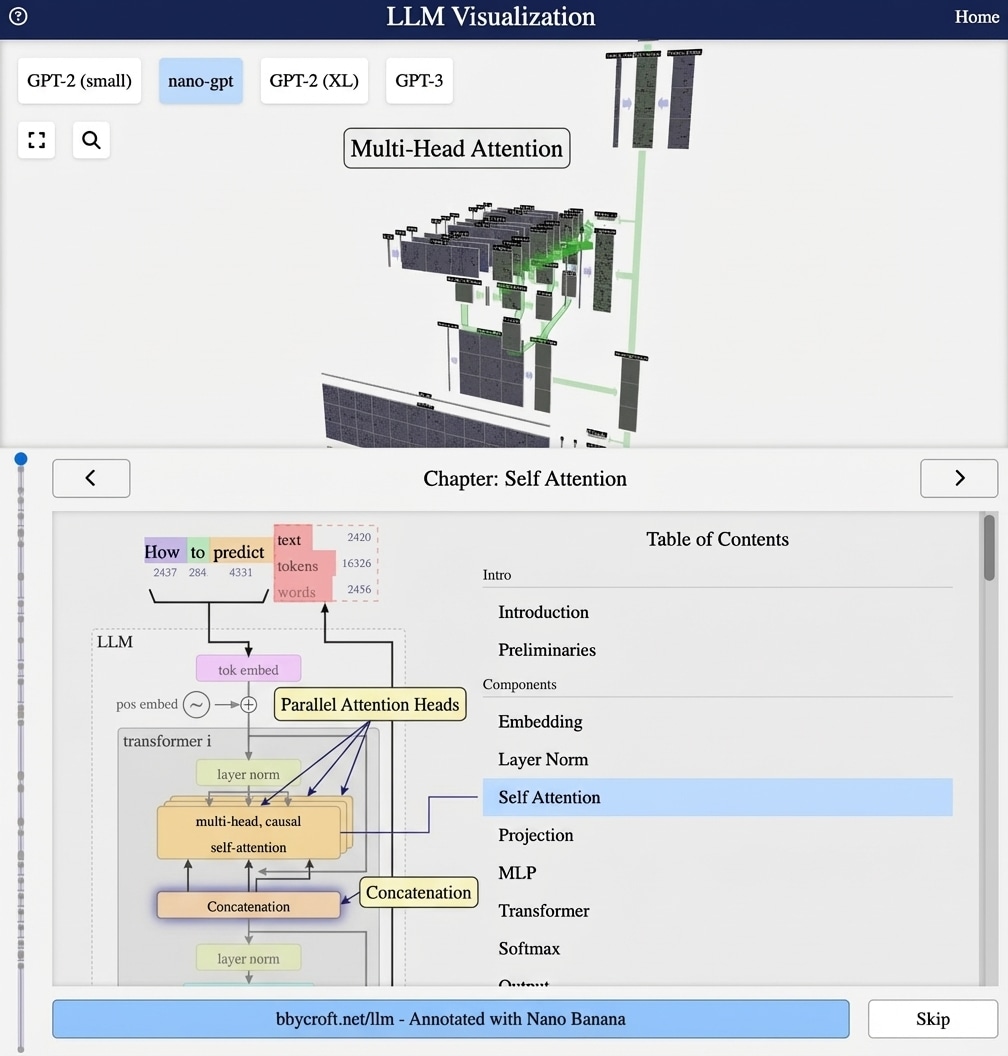
Visualisation from bbycroft.net/llm augmented by Nano Banana.

Visualisation from bbycroft.net/llm
The Feed-Forward Network
After self-attention, each token passes through a feed-forward network (FFN), also called MLP (Multi-Layer Perceptron). This is applied independently to each position.
The Architecture
The FFN consists of two linear layers with a non-linearity in between:
FFN(x) = GELU(xW1 + b1)W2 + b2
The Expansion Factor
The hidden dimension is typically 4x the model dimension:
- Input: d = 48 dimensions
- Hidden: 4d = 192 dimensions
- Output: d = 48 dimensions
This expansion allows the network to compute more complex functions.
GELU Activation
GELU (Gaussian Error Linear Unit) is smoother than ReLU:
GELU(x) = x · Φ(x)
Where Φ is the standard Gaussian CDF. It allows small negative values through, unlike ReLU.
Position-wise Processing
Unlike attention (which mixes information across positions), the FFN processes each position independently. This is where the model:
- Transforms gathered context into useful features
- Stores “factual knowledge” in its weights
- Computes complex token-level representations
Series Navigation
Previous: Projection Layer
Next: Residual Connections
This article is part of the LLM Architecture Series. Interactive visualisations from bbycroft.net/llm.
Analogy and intuition
You can think of the MLP as a small thinking step that each token takes on its own, after listening to others through attention.
It lets the model apply complex non linear rules, similar to how a person might internally reframe or combine ideas after hearing a conversation.
Looking ahead
Next we will look at residual connections, which allow the model to keep information from earlier layers while adding new refinements.