
LLM Architecture Series – Lesson 20 of 20. We have visited every component of the architecture. This lesson ties them together into a single mental model.
By walking through a full end to end example you can see how tokenization, embeddings, attention, MLPs, and the output layer cooperate to produce text.
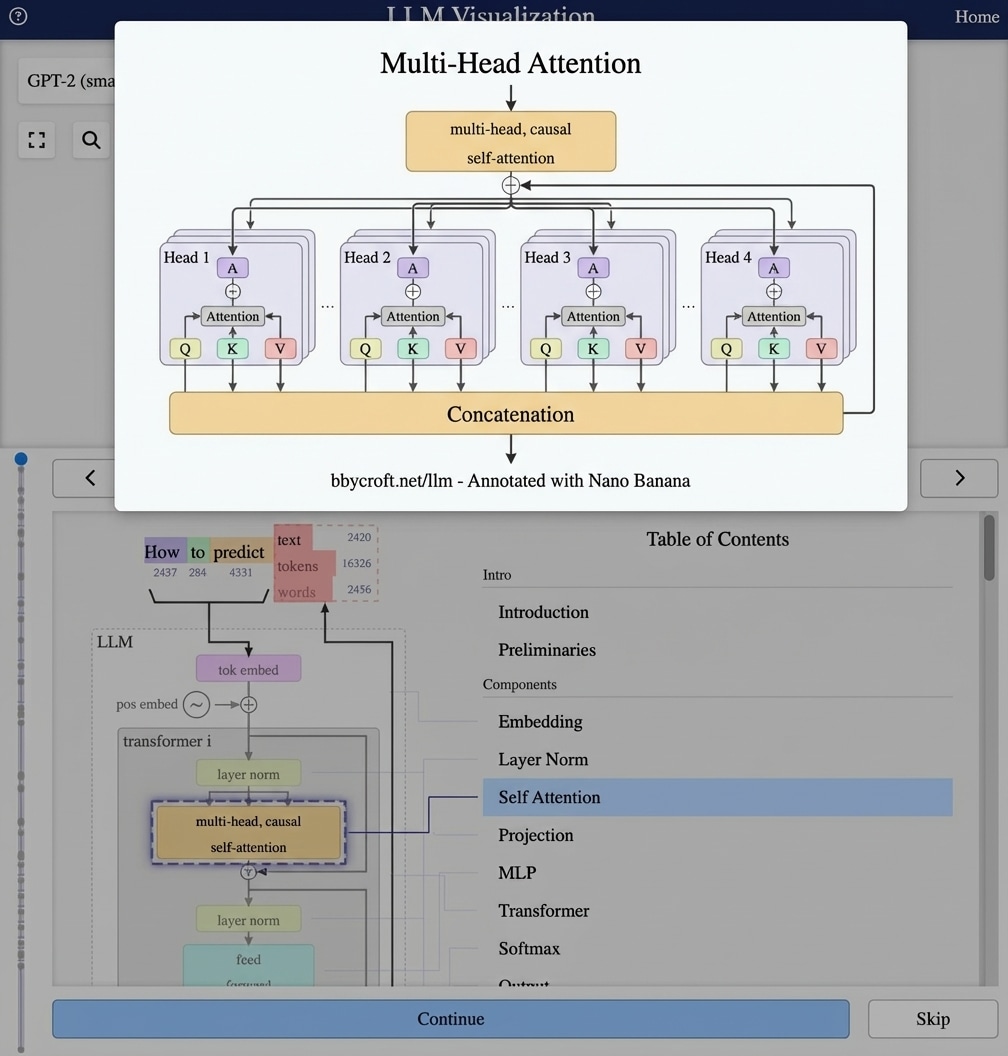
Visualisation from bbycroft.net/llm augmented by Nano Banana.
Visualisation from bbycroft.net/llm
The Complete Picture
We have now covered every component of a GPT-style Large Language Model. Let’s trace through the complete pipeline from input text to output prediction.
End-to-End Flow
- Tokenization: “How to predict” → [2437, 284, 4331]
- Token Embedding: Indices → d-dimensional vectors
- Position Embedding: Add positional information
- Transformer Blocks (× N):
- LayerNorm → Multi-Head Attention → Residual
- LayerNorm → Feed-Forward → Residual
- Final LayerNorm
- Output Projection: Hidden states → vocabulary logits
- Softmax: Logits → probabilities
- Sampling: Choose next token
Key Takeaways
- Self-attention enables context understanding across the entire sequence
- Residual connections enable training of very deep networks
- Layer normalisation stabilizes training
- Scaling unlocks emergent capabilities
Interactive Exploration
To truly understand LLMs, explore the interactive visualisation at bbycroft.net/llm. You can:
- See data flow through each component
- Compare different model sizes
- Watch attention patterns form
- Understand the mathematics visually
Series Complete
Congratulations! You’ve completed the LLM Architecture Series. You now understand how modern language models work from the ground up.
Series Navigation
Previous: Scaling LLMs
First Article: Introduction to LLMs
This article is part of the LLM Architecture Series. Interactive visualisations from bbycroft.net/llm.
Analogy and intuition
Think of the model as a production line that turns raw text into predictions. Each station on the line has a specific role, and information loops back through residual paths to refine the result.
Once you can picture this full pipeline, it becomes much easier to reason about performance, failure modes, and possible improvements.
Looking ahead
This closes the core architecture course. From here you can study training procedures, optimisation tricks, and safety alignment, all of which build on this foundation.