
LLM Architecture Series – Bonus Lesson. In earlier lessons you saw how tokens become vectors. This article goes deeper into what those vectors mean and how simple arithmetic on them can reveal structure in concepts.
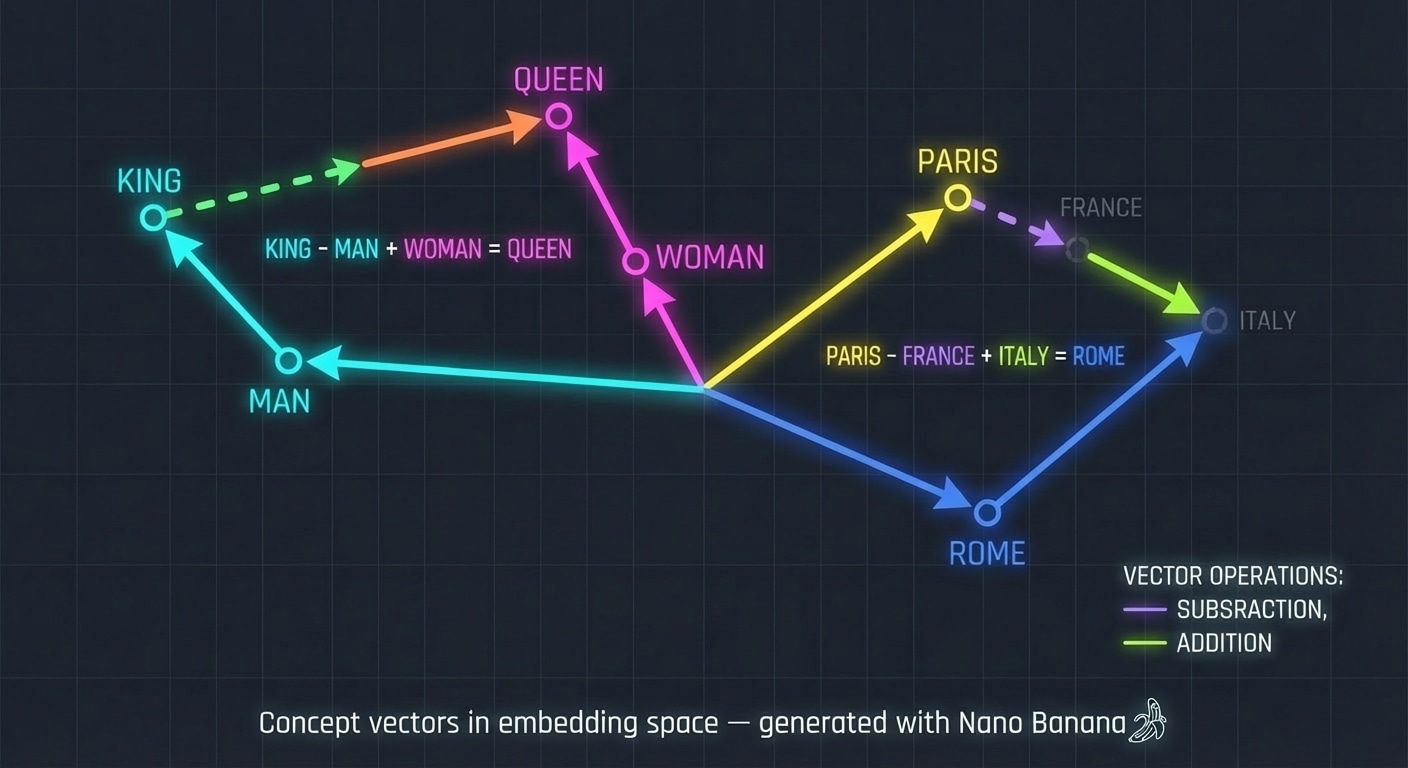
Concept vectors in embedding space, generated with Nano Banana.