

Here is a confession that will make every senior engineer nod slowly: you’ve shipped production code that you wrote in 45 minutes with an AI, it worked fine in your three test cases, and three weeks later it silently eats someone’s data because of a state transition you forgot exists. Welcome to vibe coding, the craft of going extremely fast until you aren’t. It’s not a bad thing. But it needs a theory to go with it, and that theory has a body count attached.
What vibe coding actually is
Vibe coding, the term popularised by Andrej Karpathy in early 2025, is the style of development where you describe intent, the model generates implementation, you run it, tweak the prompt, ship. The feedback loop is tight. The output volume is startling. A solo developer can now scaffold in an afternoon what used to take a sprint. That is genuinely revolutionary, and anyone who tells you otherwise is protecting their billable hours.
The problem is not the speed. The problem is what the speed hides. Frederick Brooks, in The Mythical Man-Month, observed that the accidental complexity of software, the friction that isn’t intrinsic to the problem itself, was what actually ate engineering time. What vibe coding does is reduce accidental complexity at the start and silently transfer it to structure. The code runs. The architecture is wrong. And because the code runs, you don’t notice.
The model is optimised to produce the next plausible token. It is not optimised to maintain global structural coherence across a codebase it has never fully read. It will add a feature by adding code. It will rarely add a feature by first asking “does the existing state machine support this transition?” That question is not in the next token; it is in a formal model of your system that the model does not have.
The 80% problem, precisely stated
People talk about “the 80/20 rule” in vibe coding as if it’s folklore. It isn’t. There’s a real mechanism. The first 80% of a feature, the happy path, the obvious inputs, the one scenario you described in your prompt, is exactly what training data contains. Millions of GitHub repos have functions that handle the normal case. The model has seen them all. So it reproduces them, fluently, with good variable names.

The remaining 20% is the error path, the timeout, the cancellation, the “what if two events arrive simultaneously” case, the states that only appear when something goes wrong. Training data for these is sparse. They’re the cases the original developer also half-forgot, which is why they produced so many bugs in the first place. The model reproduces the omission faithfully. You inherit not just the code but the blind spots.
Practically, this shows up as stuck states (a process enters a “loading” state with no timeout or error transition, so it just stays there forever), flag conflicts (two boolean flags that should be mutually exclusive can both be true after a fast-path branch the model added), and dead branches (an error handler that is technically present but unreachable because an earlier condition always fires first). None of these are typos. They are structural, wrong shapes, not wrong words. A passing test suite will not catch them because you wrote the tests for the cases you thought of.
The additive trap
There is a deeper failure mode that deserves its own name: the additive trap. When you ask a model to “add feature X,” it adds code. It almost never removes code. It never asks “should we refactor the state machine before adding this?” because that question requires a global view the model doesn’t have. Hunt and Thomas, in The Pragmatic Programmer, call this “programming by coincidence”, the code works, you don’t know exactly why, and you’re afraid to change anything for the same reason. Vibe coding industrialises programming by coincidence.
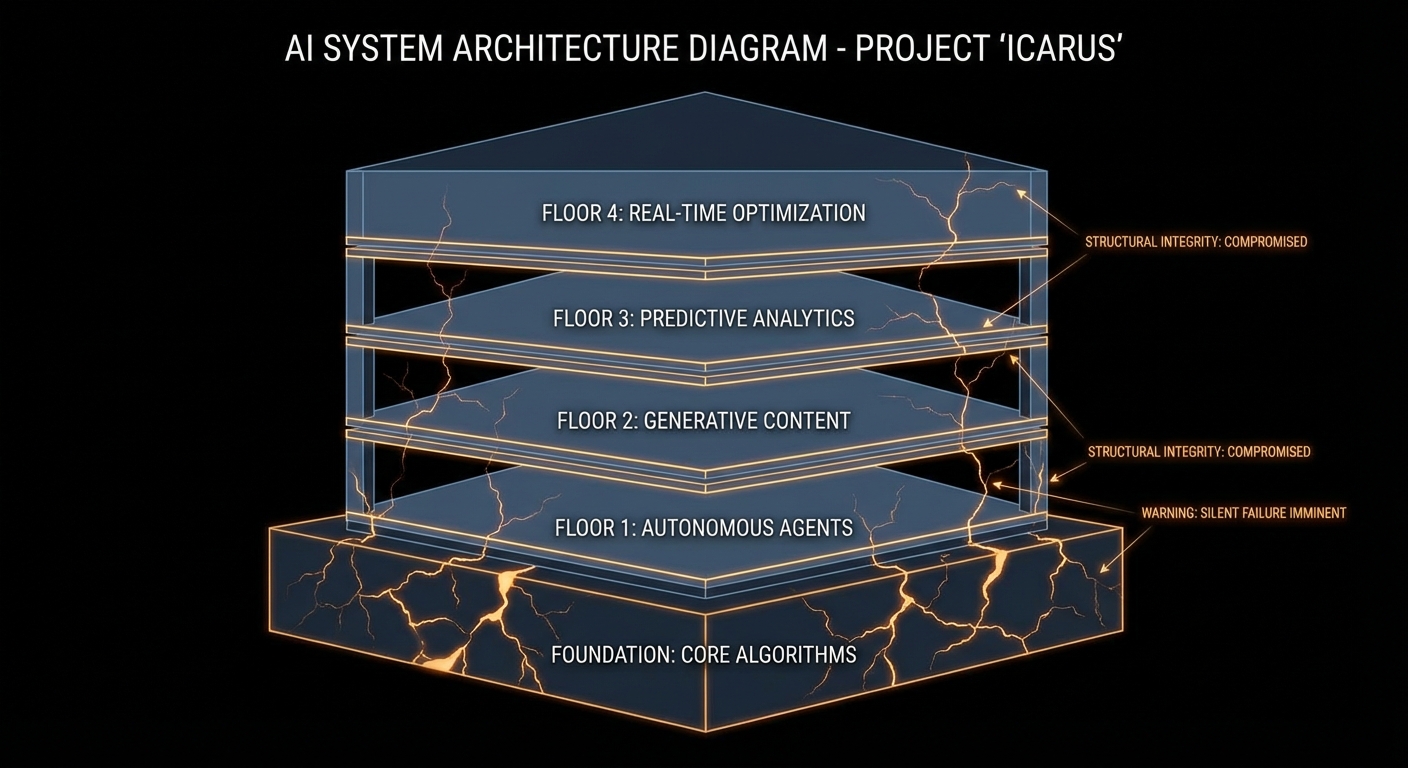
The additive trap compounds. Feature one adds a flag. Feature two adds logic that checks the flag in three places. Feature three adds a fast path that bypasses one of those checks. Now the flag has four possible interpretations depending on call order, and the model, when you ask it to “fix the edge case”, adds a fifth. At no point did anyone write down what the flag means. This is not a novel problem. It is the exact problem that formal specification and state machine design were invented to solve, sixty years before LLMs existed. The difference is that we used to accumulate this debt over months. Now we can do it in an afternoon.
Workflow patterns: the checklist you didn’t know you needed
Computer scientists have been cataloguing the shapes of correct processes for decades. Wil van der Aalst’s work on workflow patterns, 43 canonical control-flow patterns covering sequences, parallel splits, synchronisation, cancellation, and iteration, is the closest thing we have to a grammar of “things a process can do.” When a model implements a workflow, it usually gets patterns 1 through 5 right (the basic ones). It gets pattern 9 (discriminator) and pattern 19 (cancel region) wrong or absent, because these require coordinating multiple states simultaneously and the training examples are rare.
You don’t need to memorise all 43. You need a mental checklist: for every state, is there at least one exit path? For every parallel split, is there a corresponding synchronisation? For every resource acquisition, is there a release on every path including the error path? Run this against your AI-generated code the way you’d run a linter. It takes ten minutes and has saved production systems from silent deadlocks more times than any test suite.
// What the model generates (incomplete)
async function processPayment(orderId) {
await db.updateOrderStatus(orderId, 'processing');
const result = await paymentGateway.charge(order.amount);
await db.updateOrderStatus(orderId, 'complete');
return result;
}
// What the model forgot: the order is now stuck in 'processing'
// if paymentGateway.charge() throws. Ask: what exits 'processing'?
async function processPayment(orderId) {
await db.updateOrderStatus(orderId, 'processing');
try {
const result = await paymentGateway.charge(order.amount);
await db.updateOrderStatus(orderId, 'complete');
return result;
} catch (err) {
// Exit from 'processing' on failure — the path the model omitted
await db.updateOrderStatus(orderId, 'failed');
throw err;
}
}
How to vibe code without the body count
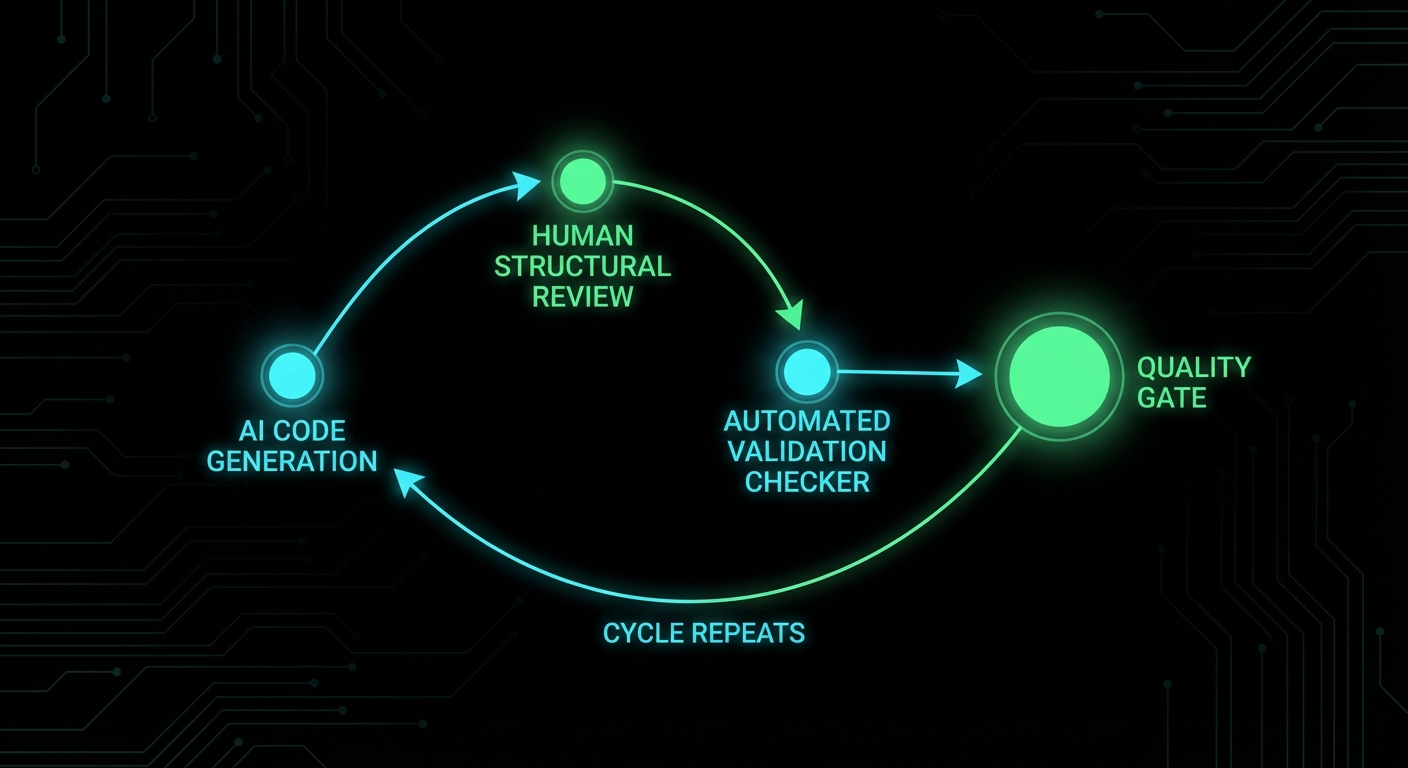
The model is a brilliant first drafter with poor architectural instincts. Your job changes from “write code” to “specify structure, generate implementation, audit shape.” In practice that means three things:
- Design state machines before prompting. Draw the states and transitions for anything non-trivial. Put them in a comment at the top of the file. Now when you prompt, the model has a spec. It will still miss cases, but now you can compare the output against a reference and spot the gap.
- Review for structure, not syntax. Don’t ask “does this code work?” Ask “does every state have an exit?” and “does every flag have a clear exclusive owner?” These are structural questions. Tests answer the first. Only a human (or a dedicated checker) answers the second.
- Treat model output as a first draft, not a commit. The model’s job is to fill in the known patterns quickly. Your job is to catch the unknown unknowns, the structural gaps that neither the model nor the obvious test cases reveal. Refactor before you ship. It takes a fraction of the time it takes to debug the stuck state in production at 2am.
Vibe coding is real productivity, not a gimmick. But it is productivity the way a very fast car is fast, exhilarating until you notice the brakes feel soft. The speed is the point. The structural review is the brakes. Keep both.
nJoy 😉