
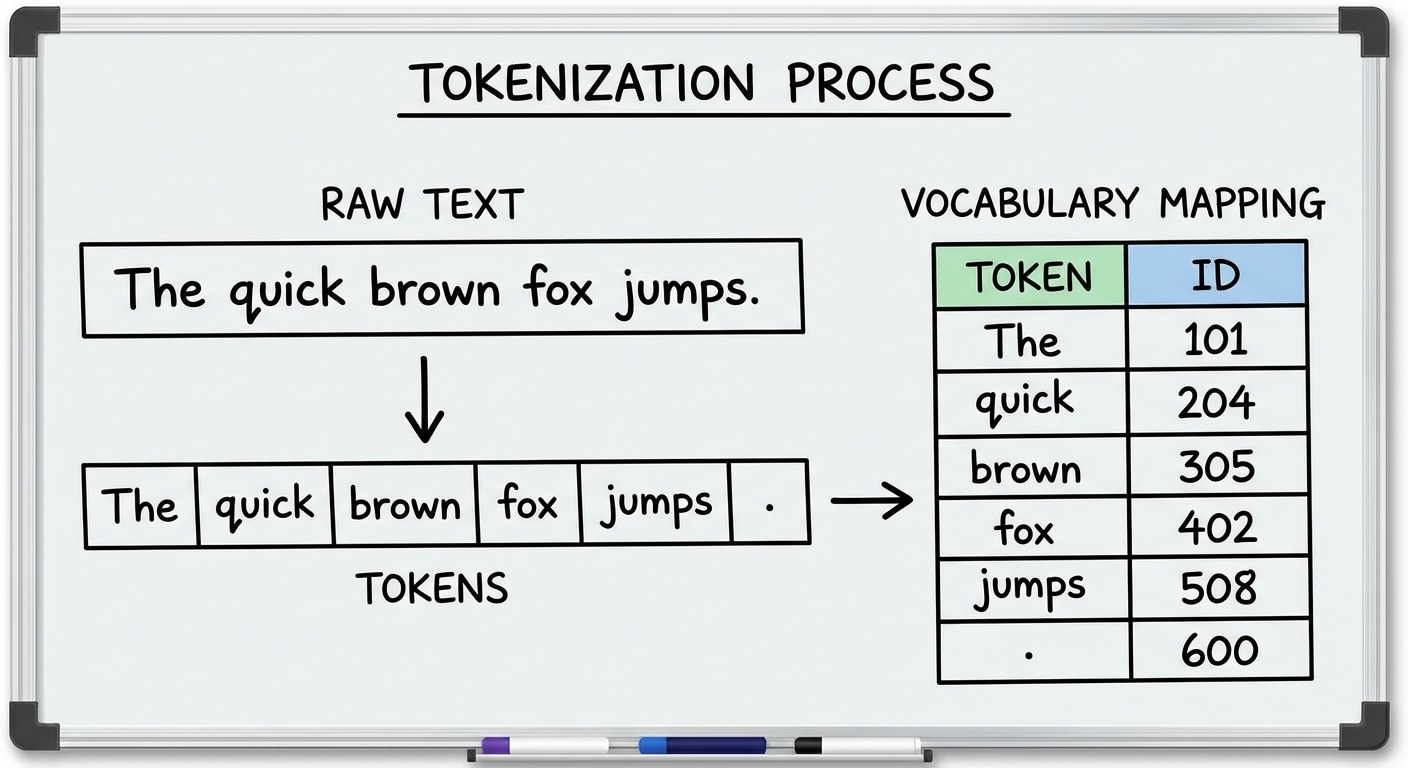
Tokenization: Breaking Text for AI
Before AI can process text, it must be split into tokens – the fundamental units the model works with. Tokenization strategy significantly impacts model performance, vocabulary size, and ability to handle rare or novel words. Getting it right matters more than many realise.
Word-level tokenization splits on whitespace, creating intuitive tokens but massive vocabularies. Unknown words become impossible to handle. Character-level uses each character as a token, handling any text but losing word-level semantics and creating very long sequences.
Subword tokenization like BPE and WordPiece offers the best of both worlds. Common words remain whole while rare words split into meaningful subwords. The vocabulary stays manageable at 32K-100K tokens while handling novel words by decomposition.
Modern tokenizers also handle special tokens for model control: beginning and end of sequence markers, padding tokens, and special separators. Understanding tokenization helps debug model behaviour – sometimes strange outputs trace back to unexpected token boundaries.