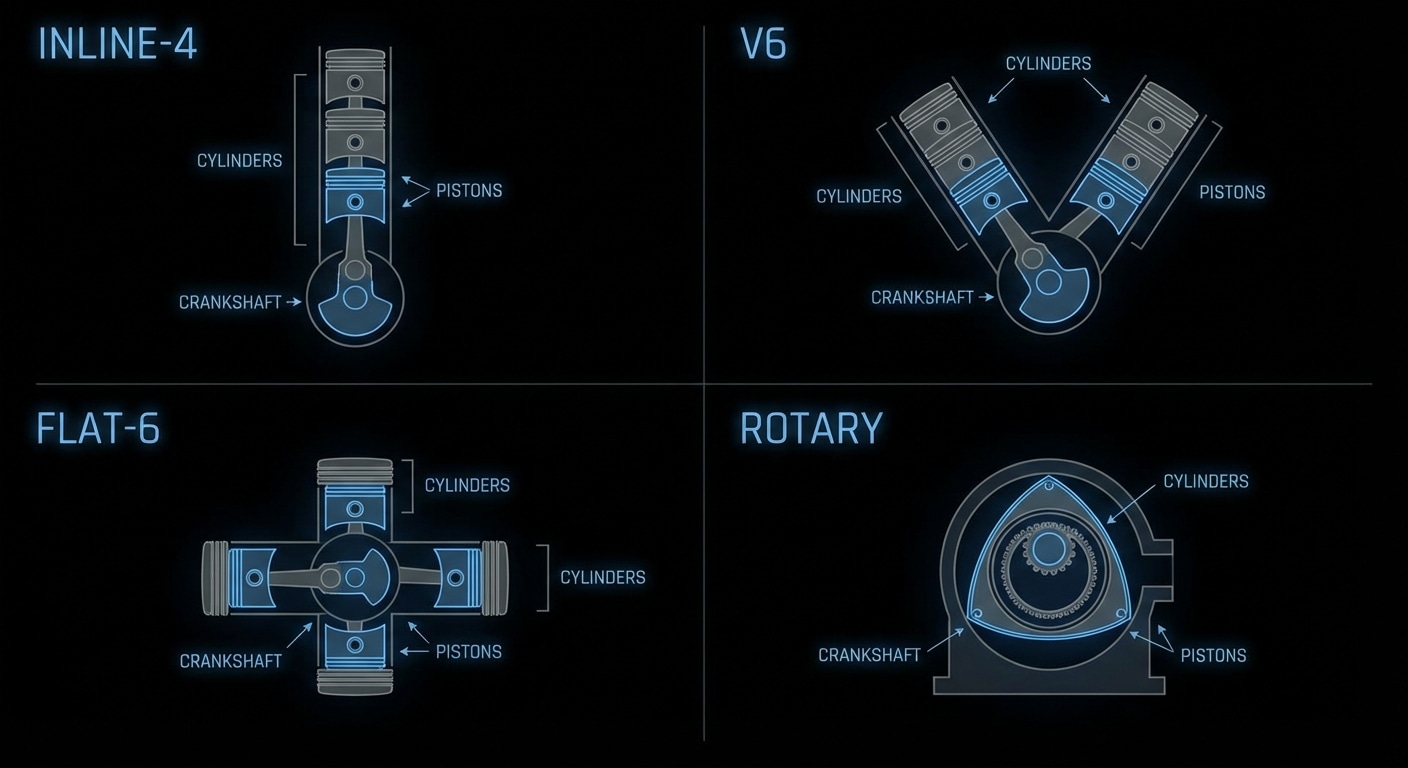
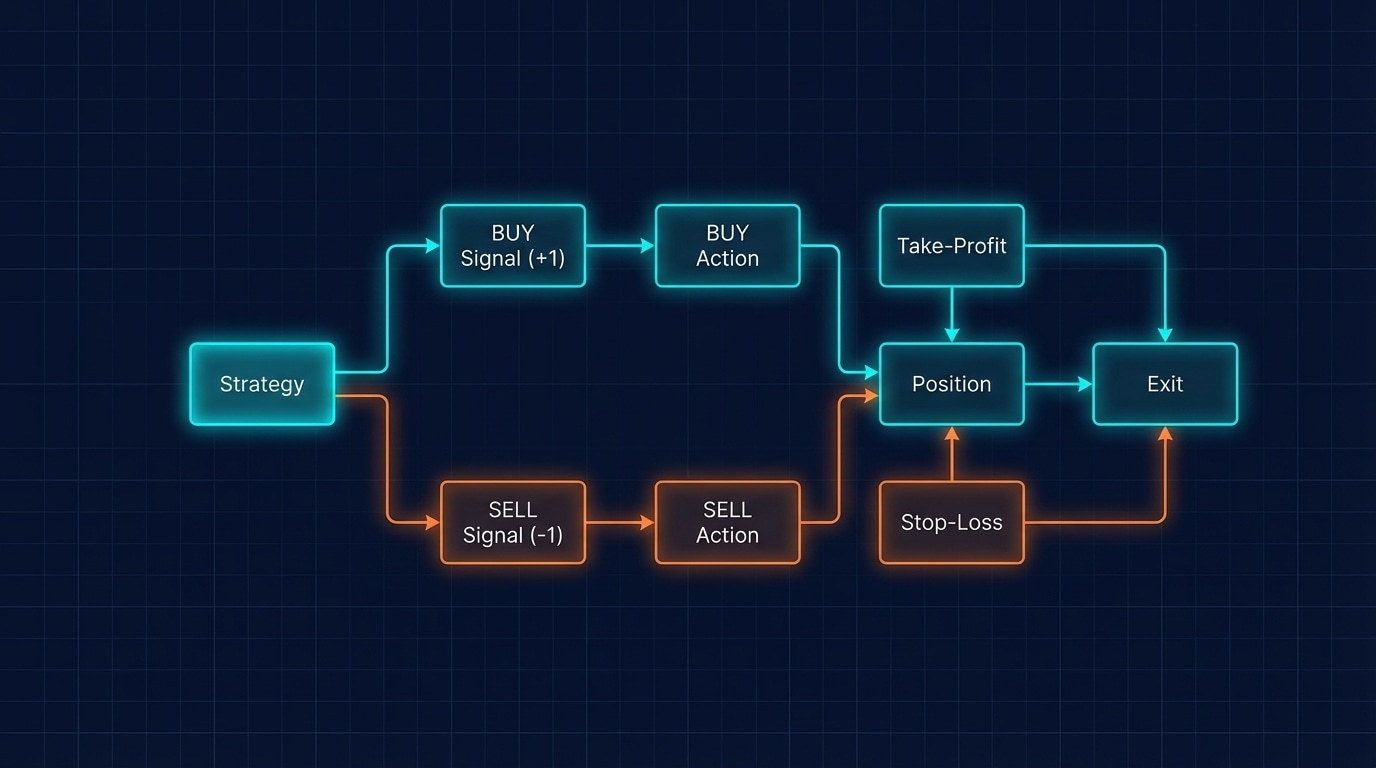
Traditional batch inference works like a bus: you wait until every passenger (request) is ready, then you run one big forward pass. When requests have different lengths or finish at different times, the bus still waits for the slowest. That wastes GPU time and inflates latency. Continuous batching fixes that by treating the batch as fluid: new requests join as soon as there’s room, and requests leave as soon as they’ve produced their next token. So at each step you’re decoding for a set of “active” sequences, not a fixed batch. Throughput goes up and tail latency goes down.
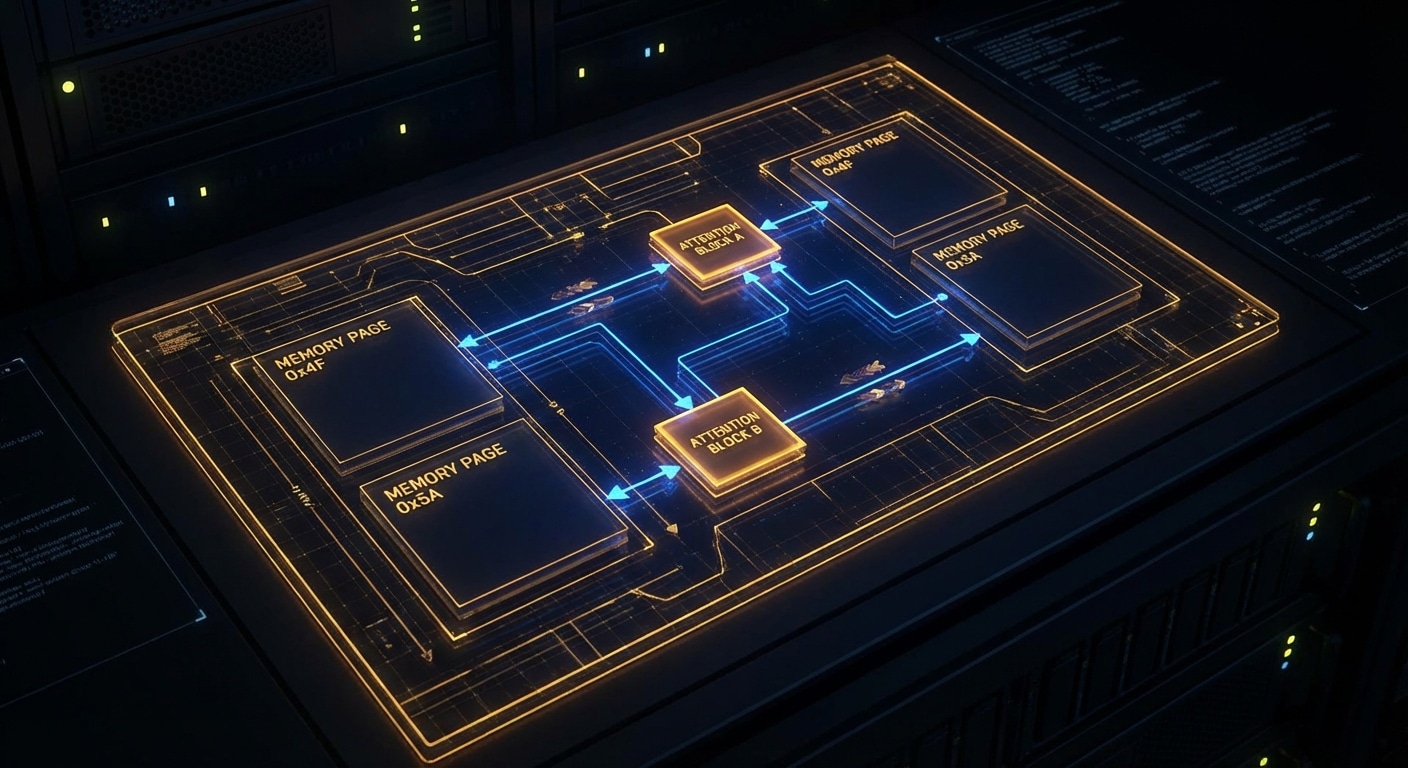
Under the hood, the server maintains a batch of in-flight sequences. Each step: run one decode for every sequence in the batch, append the new token to each, check for EOS or stop conditions, remove finished sequences, and add new ones from the queue. The batch shape changes every step. That requires dynamic shapes and careful memory handling, which is where PagedAttention and similar schemes help. vLLM and TGI both use continuous batching; it’s a big reason they can serve many users at once without turning into a queue.
For you as a user of an API, it means the server isn’t waiting for other people’s long answers before starting yours. For you as an operator, it means the GPU stays busy and you can set tighter latency targets.
The only downside is implementation complexity and the need for kernels that support variable-length batches. Once that’s in place, continuous batching is the default for any serious serving setup.
Expect continuous batching to become the norm everywhere; the next improvements will be around prioritisation, fairness, and better memory reuse.
nJoy 😉