
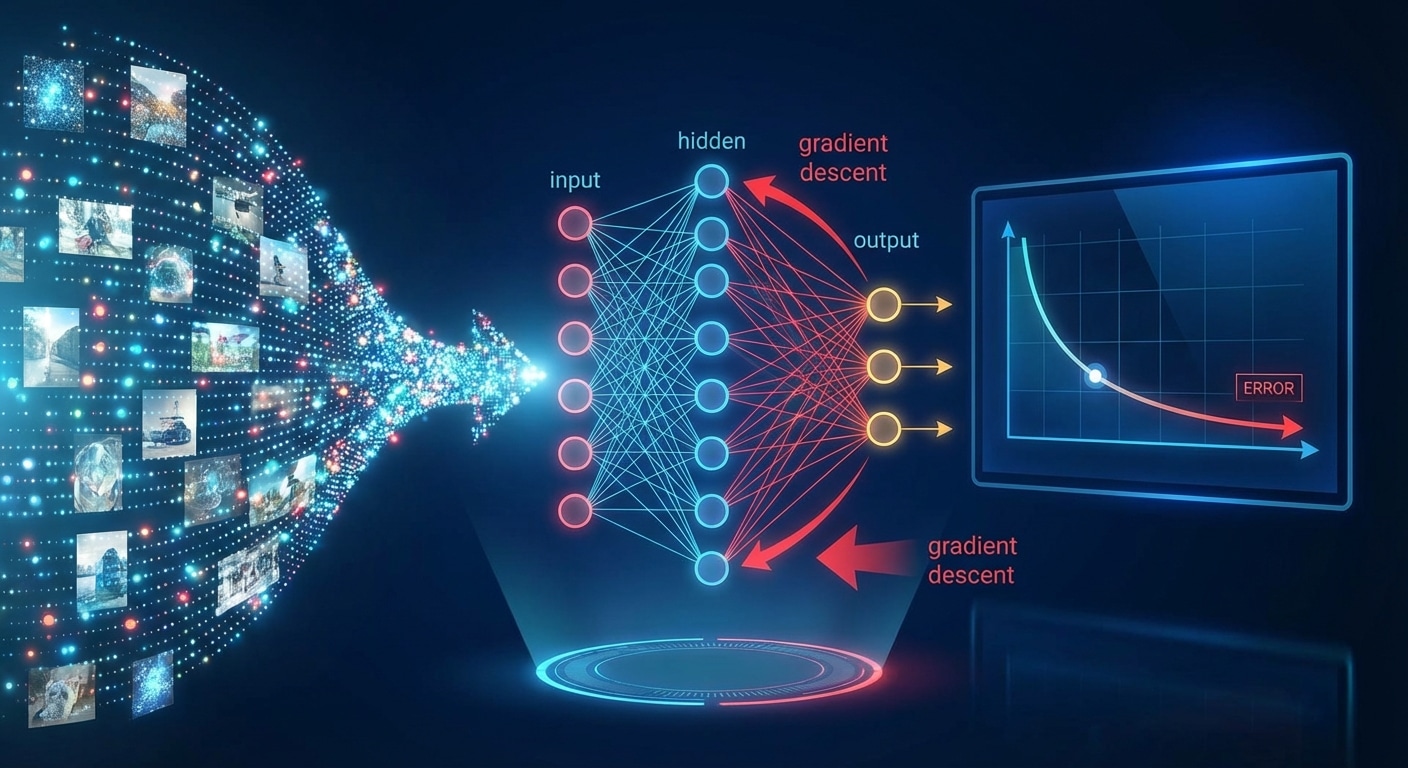
How Machine Learning Actually Learns
Machine learning is optimisation, not magic. The learning process iteratively adjusts model parameters to minimise a loss function measuring prediction errors. This systematic approach revolutionized intelligent systems, enabling computers to improve through experience rather than explicit programming.
The training loop follows a consistent pattern. During the forward pass, input flows through the model producing predictions. The loss function calculates deviation from targets. During backpropagation, gradients indicate how each parameter contributed to error. Finally, the optimiser updates weights to reduce loss. This cycle repeats millions of times.
Gradient descent drives optimisation. Imagine finding the lowest point in a landscape while blindfolded – you feel the slope and step downhill. Gradient descent follows the steepest path to minimum error. Learning rate controls step size: too large overshoots, too small gets stuck.
Modern optimisers like Adam and RMSprop improve upon basic gradient descent by adapting learning rates and using momentum to escape local minima. Understanding these fundamentals enables diagnosing training issues, tuning hyperparameters, and designing efficient architectures for any scale.