
LLM Architecture Series – Lesson 2 of 20. In the previous lesson you saw the full architecture. Now we zoom into the very first step, tokenization.
We turn text into a sequence of tokens so that the model can work with discrete pieces instead of raw characters.
Visualisation from bbycroft.net/llm augmented by Nano Banana.
Visualisation from bbycroft.net/llm
What is Tokenization?
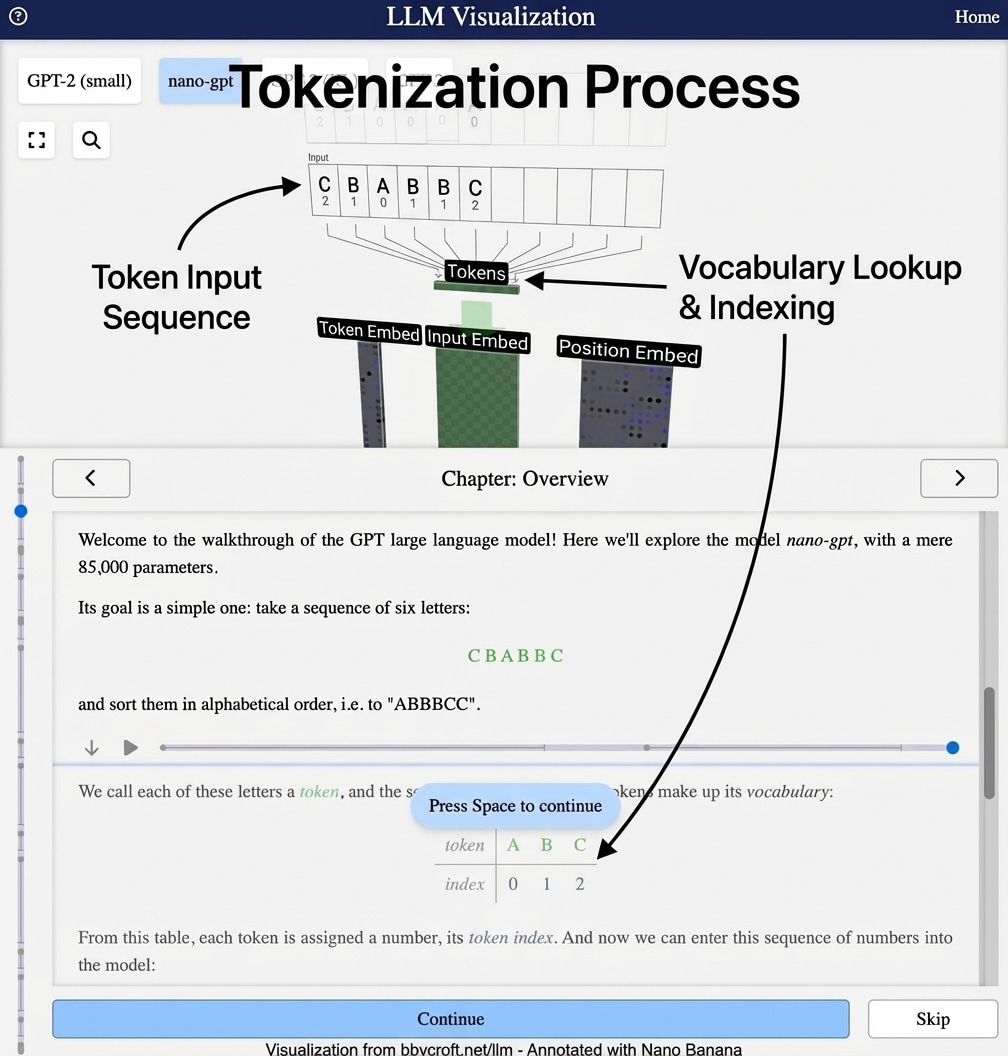
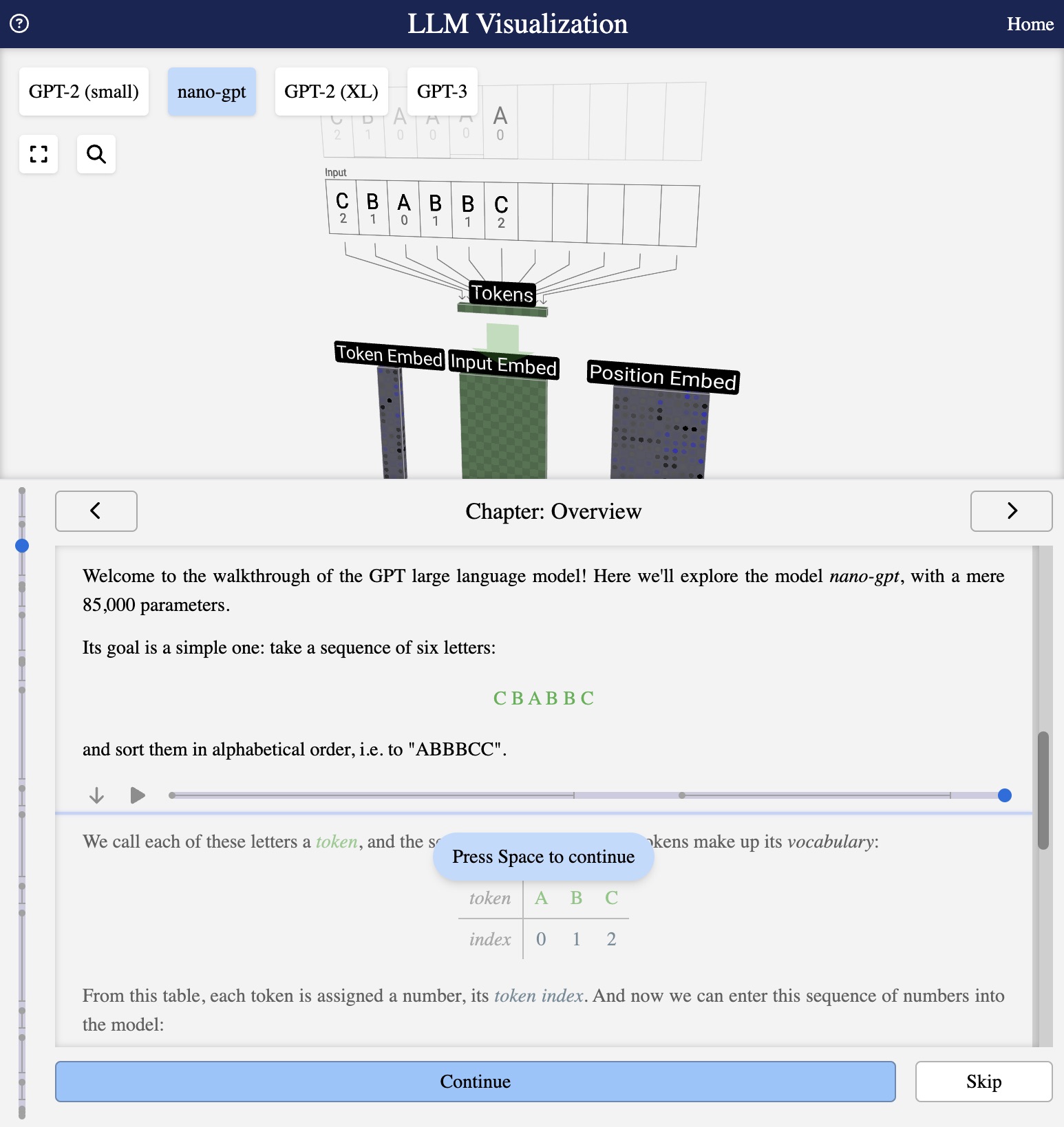
Tokenization is the first step in processing text for a language model. It breaks down input text into smaller units called tokens. Each token is then assigned a unique numerical index from the model’s vocabulary.
The Vocabulary
Every LLM has a fixed vocabulary – a set of all tokens it knows. In the nano-gpt example, the vocabulary is simple:
token | A | B | C
index | 0 | 1 | 2
Production models like GPT-3 use vocabularies of 50,000+ tokens, including whole words, word pieces, and special characters.
From Text to Numbers
When you input “CBABBC”, the tokenizer:
- Splits the text into individual tokens: [C, B, A, B, B, C]
- Looks up each token’s index: [2, 1, 0, 1, 1, 2]
- Creates a sequence of integers that the model can process
Why Tokenization Matters
The choice of tokenization scheme significantly impacts model performance:
- Character-level: Simple but creates very long sequences
- Word-level: Natural but struggles with unknown words
- Subword (BPE): Balance of efficiency and flexibility – used by GPT models
Series Navigation
Previous: Introduction to Large Language Models
Next: Token Embeddings – Converting Words to Vectors
This article is part of the LLM Architecture Series. Interactive visualisations from bbycroft.net/llm.
Analogy and intuition
Think of tokenization like cutting a long sentence into small Lego bricks. Each brick is big enough to be meaningful, but small enough that we can reuse it in many different constructions.
Different tokenization schemes are like different ways of cutting a word, similar to how some people break a task into many tiny steps while others prefer bigger chunks.
Looking ahead
Next we will see how each token is turned into a vector of numbers through token embeddings.
This series explains LLM architecture in a very clear and intuitive way. I really liked how you start from the big picture and then break everything down step by step, especially using nano-GPT to make the concepts easier to grasp. The visualizations and analogies make ideas like tokenization, embeddings, and transformer blocks much more understandable, even for beginners. It’s a great balance between intuition and technical depth, and a very solid learning path for anyone wanting to truly understand how LLMs work, Thank you for the great effort!
You are very welcome !!!