
LLM Architecture Series – Lesson 8 of 20. You have seen single head self attention. In practice transformers use many attention heads in parallel.
Each head can focus on different kinds of patterns such as subject verb agreement, long range dependencies, or punctuation structure.
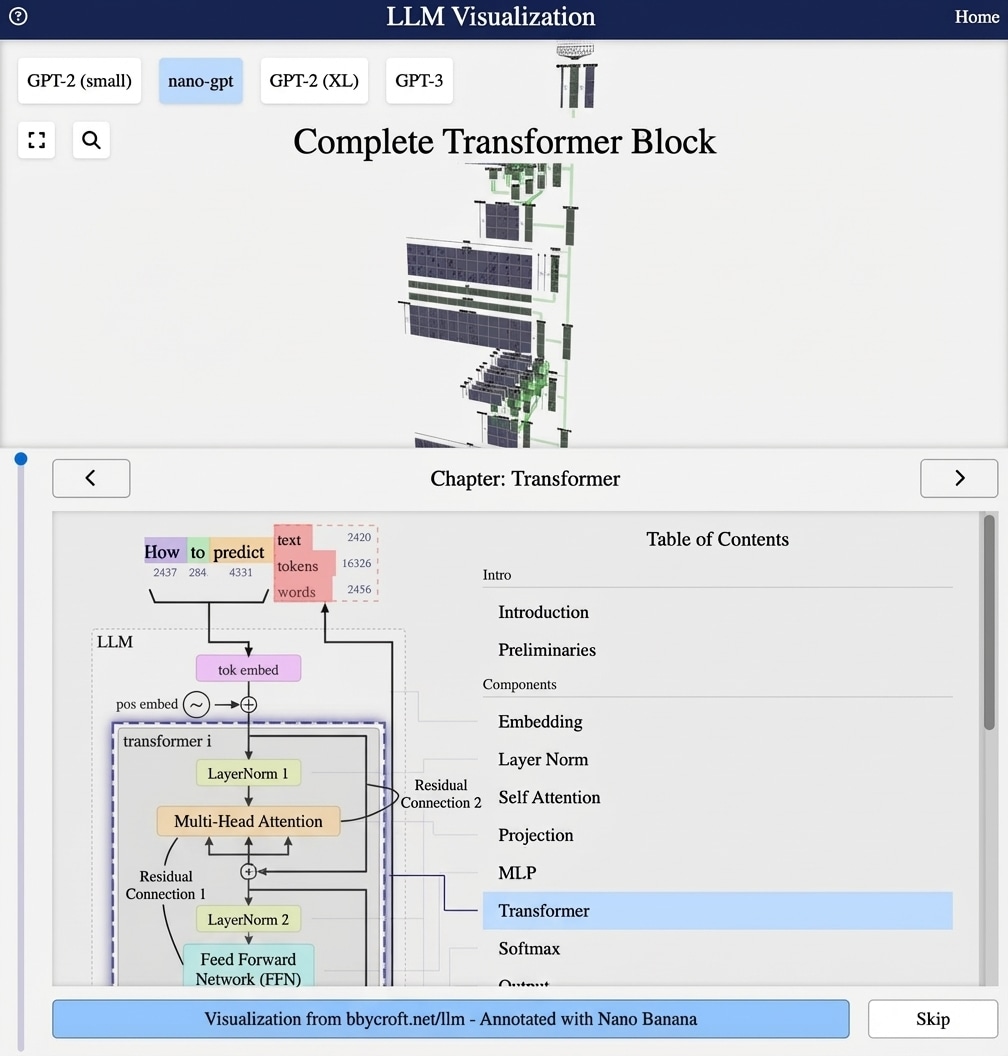
Visualisation from bbycroft.net/llm augmented by Nano Banana.

Visualisation from bbycroft.net/llm
Why Multiple Heads?
Multi-head attention runs several attention operations in parallel, each with different learned projections. This allows the model to attend to information from different representation subspaces.
Different Heads, Different Patterns
Each attention head can learn to focus on different relationships:
- Head 1: Syntactic relationships (subject-verb)
- Head 2: Positional patterns (adjacent words)
- Head 3: Semantic similarity
- Head 4: Coreference (pronouns to nouns)
The Multi-Head Formula
MultiHead(X) = Concat(head1, …, headh)WO
Where each head is:
headi = Attention(XWQi, XWKi, XWVi)
Dimensions
In nano-gpt with embedding dimension 48 and 3 heads:
- Each head operates on 48/3 = 16 dimensions
- All heads are computed in parallel
- Results are concatenated back to 48 dimensions
Computational Efficiency
Despite having multiple heads, the total computation is similar to a single large attention – we just split the dimensions differently. This makes multi-head attention both powerful and efficient.
Series Navigation
Previous: Self-Attention Part 1
Next: Query, Key, Value in Attention
This article is part of the LLM Architecture Series. Interactive visualisations from bbycroft.net/llm.
Analogy and intuition
Multi head attention is like having several experts look at the same sentence, each with a different specialty. One looks for grammar, another for topic shifts, another for names and dates.
The outputs from all experts are then combined, giving the model a richer view than any single expert could provide.
Looking ahead
In the next lesson we will zoom into the Query, Key, and Value vectors that make attention work.