
LLM Architecture Series – Lesson 7 of 20. So far each position has a clean, normalised embedding. Now the model needs a way for each position to look at other positions.
Self attention lets every token decide which other tokens are important for predicting the next output.
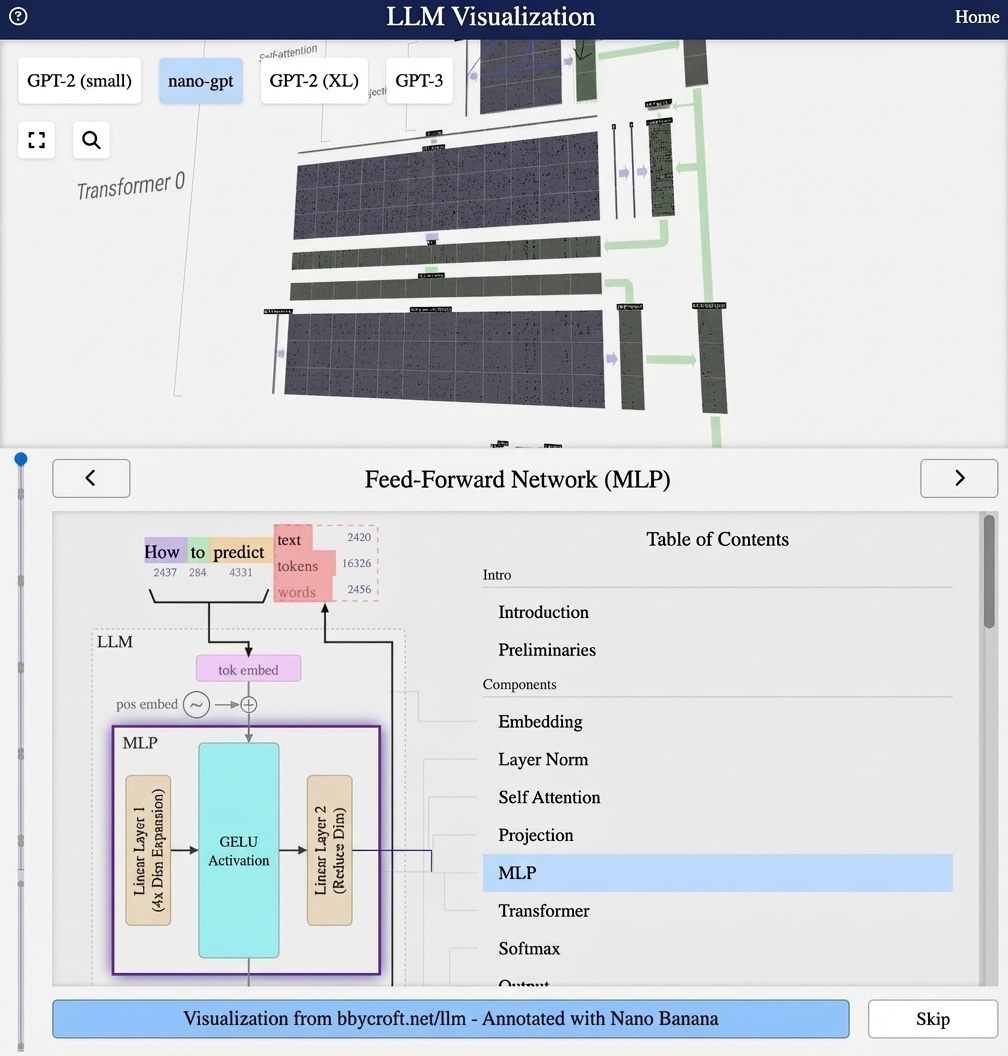
Visualisation from bbycroft.net/llm augmented by Nano Banana.

Visualisation from bbycroft.net/llm
The Heart of the Transformer
Self-attention is the mechanism that allows each token to “look at” and gather information from all other tokens in the sequence. It’s what makes transformers so powerful for understanding context.
The Core Intuition
For each token, self-attention asks: “Which other tokens are relevant to understanding me?”
For example, in “The cat sat on the mat because it was tired”:
- “it” needs to attend to “cat” to understand the reference
- “tired” might attend to “cat” to know what’s tired
Query, Key, Value
Self-attention uses three projections of each token:
- Query (Q): “What am I looking for?”
- Key (K): “What do I contain?”
- Value (V): “What information do I provide?”
Q = XWQ, K = XWK, V = XWV
The Attention Score
The relevance between tokens i and j is computed as:
score(i, j) = Qi · Kj / √dk
The dot product measures similarity – if query and key point in similar directions, the score is high.
Visualisation
In the 3D view, you can see attention as information flowing between token positions. The green lines show how each position gathers context from others.
Series Navigation
Previous: Layer Normalisation
Next: Understanding Self-Attention – Part 2 (Multi-Head)
This article is part of the LLM Architecture Series. Interactive visualisations from bbycroft.net/llm.
Analogy and intuition
Imagine a group discussion where each person listens to the others before speaking. Some voices matter more for a given topic, and attention is like assigning weights to those voices.
Self attention gives the model a flexible way to focus on the few most relevant words in a sentence, rather than treating every word as equally important.
Looking ahead
Next we will see how self attention is extended to multiple heads so that the model can look at different types of relationships in parallel.