
LLM Architecture Series – Lesson 4 of 20. So far we know the meaning of each token. Now we teach the model where each token sits in the sequence.
Position embeddings make it possible for the model to tell the difference between subject and object, start and end, and repeated words at different places.
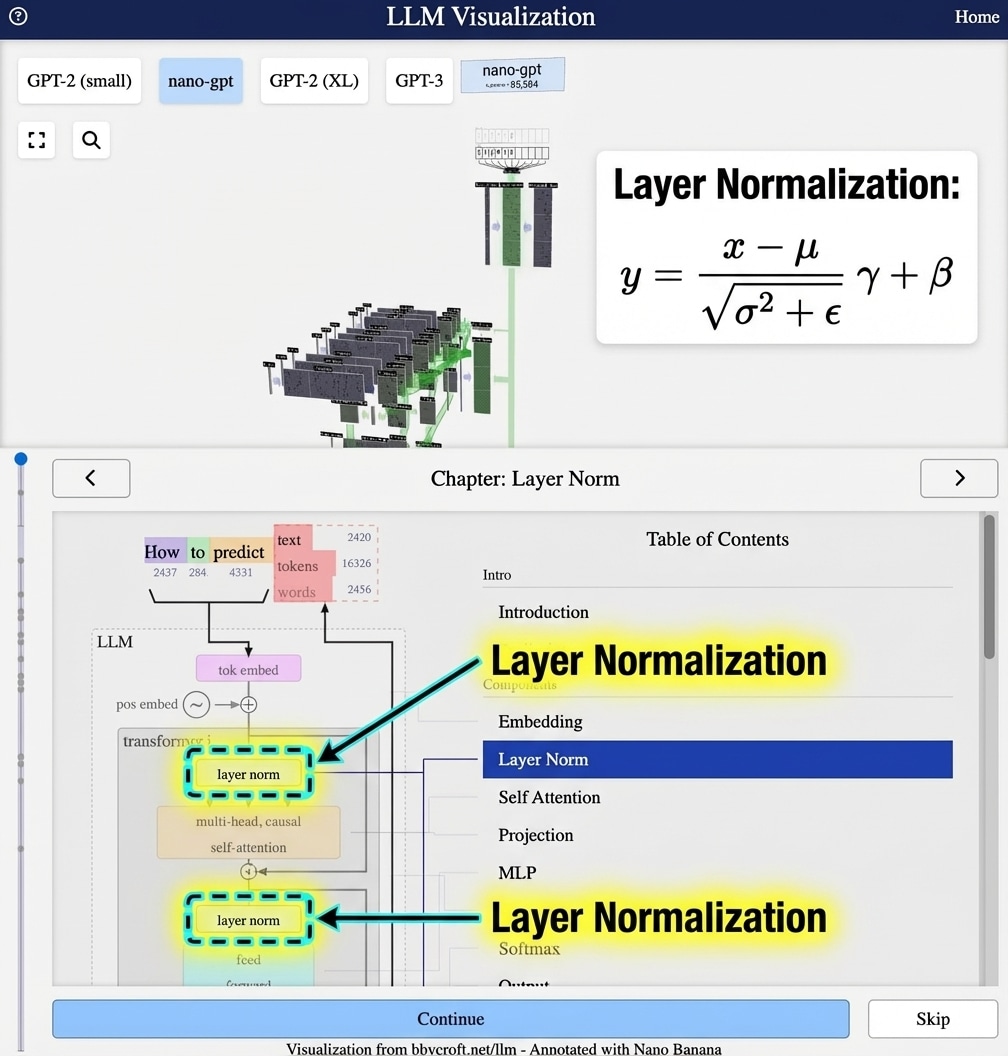
Visualisation from bbycroft.net/llm augmented by Nano Banana.
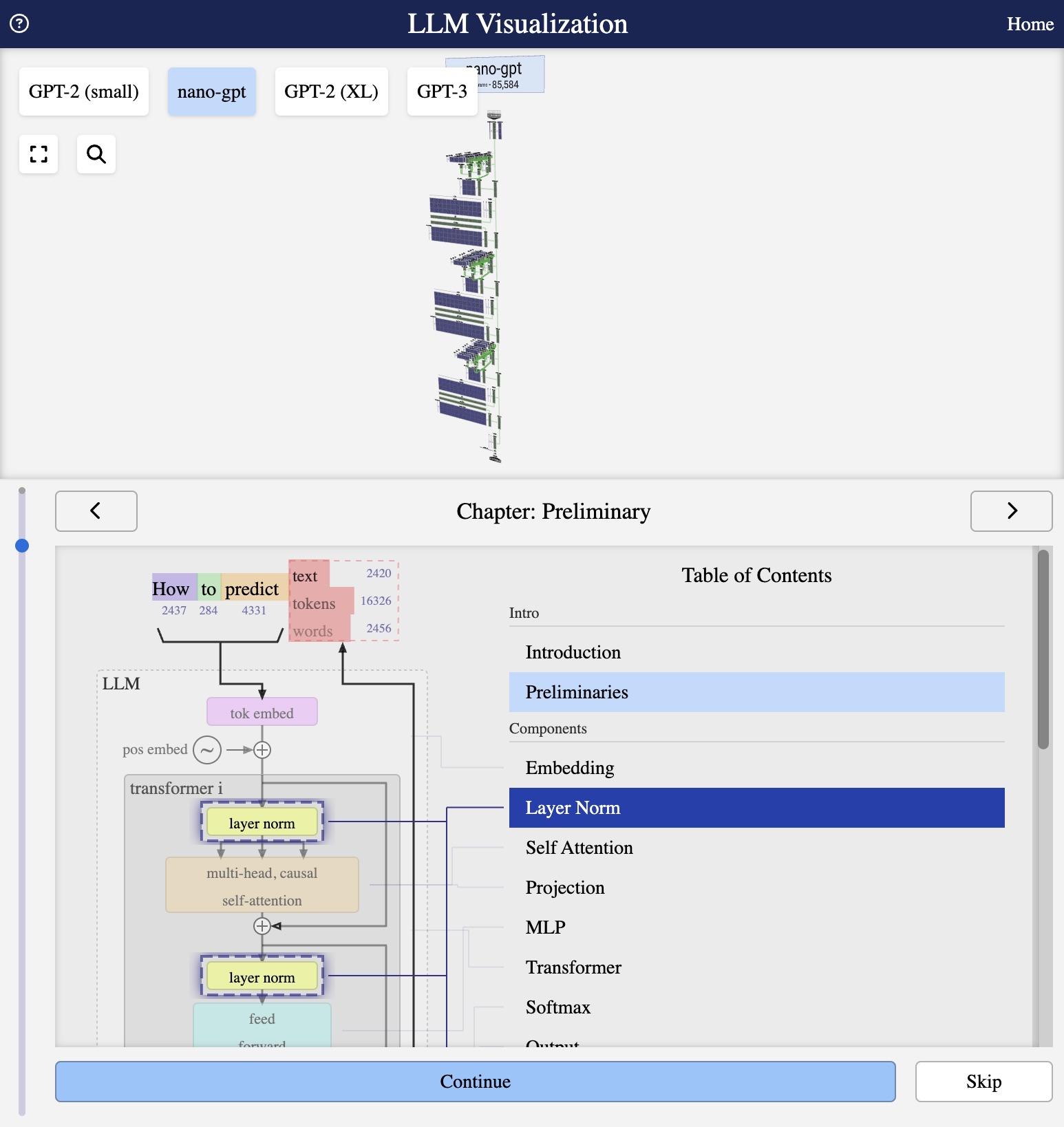
Visualisation from bbycroft.net/llm
Why Position Matters
Unlike RNNs that process tokens sequentially, transformers process all tokens simultaneously. This parallelism is efficient but loses positional information. Consider:
- “The cat sat on the mat”
- “The mat sat on the cat”
Without position information, these would look identical to the model!
Position Embedding Matrix
Similar to token embeddings, position embeddings use a learnable matrix:
P ∈ Rmax_seq_len × d
Each position (0, 1, 2, …) gets its own learned vector of the same dimension as token embeddings.
Combining Token and Position
The input to the transformer is the sum of token and position embeddings:
xi = TokenEmbed(tokeni) + PosEmbed(i)
This simple addition encodes both “what” (the token) and “where” (the position).
Learned vs Sinusoidal
There are two main approaches:
- Learned (GPT): Position embeddings are trained parameters
- Sinusoidal (Original Transformer): Fixed mathematical patterns
GPT models use learned positional embeddings, which work well in practice.
Series Navigation
Previous: Token Embeddings
Next: The Combined Input Embedding
This article is part of the LLM Architecture Series. Interactive visualisations from bbycroft.net/llm.
Analogy and intuition
Think of reading a music score. Notes with the same pitch mean different things depending on when they are played. Position embeddings are like the timing marks on the score.
In language, the word “bank” near “river” means something very different from “bank” near “loan”. Position information helps the model disambiguate meaning over time.
Looking ahead
In the next lesson we will combine token embeddings and position embeddings into a single input vector for each position.