
LLM Architecture Series – Lesson 18 of 20. The output layer produces one logit per token in the vocabulary. Softmax converts these logits into a proper probability distribution.
These probabilities drive sampling strategies such as greedy decoding, top k sampling, and nucleus sampling.
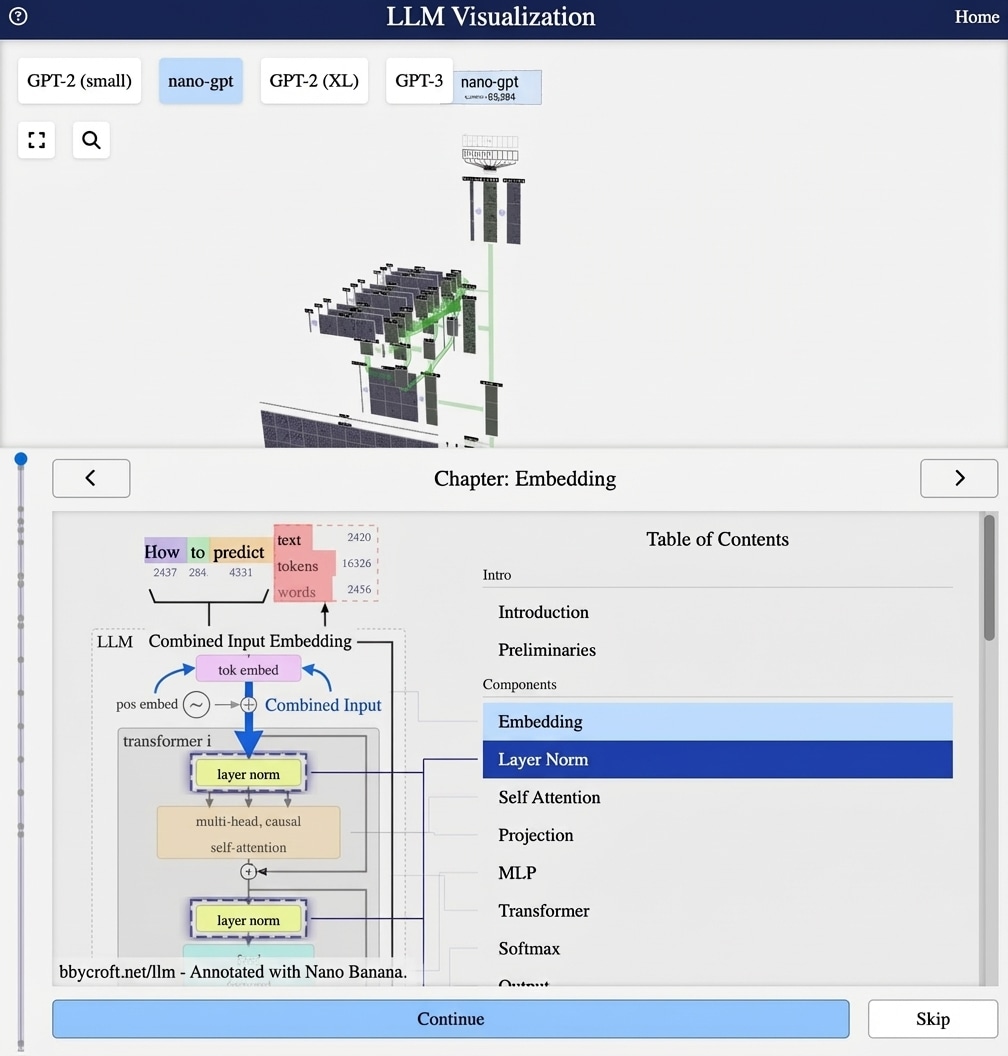
Visualisation from bbycroft.net/llm augmented by Nano Banana.
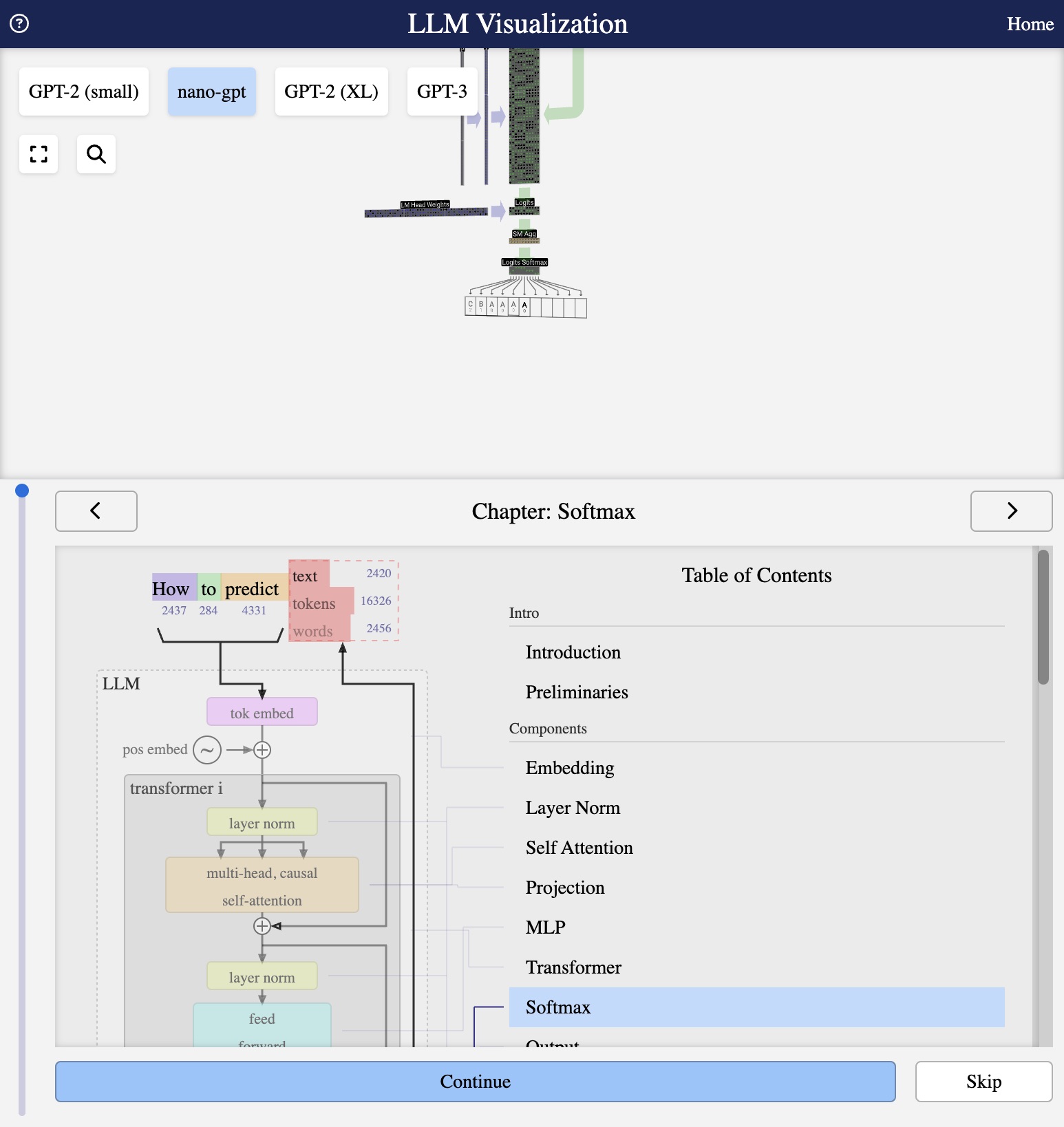
Visualisation from bbycroft.net/llm
From Logits to Probabilities
The output layer produces logits – raw scores that can be any real number. To get a probability distribution over the vocabulary, we apply softmax.
The Final Softmax
P(tokeni) = elogiti / Σj elogitj
This gives us a proper probability distribution:
- All probabilities are positive
- They sum to 1
- Higher logits = higher probabilities
Temperature Scaling
We can adjust the “sharpness” of the distribution using temperature:
P(tokeni) = elogiti/T / Σj elogitj/T
- T < 1: Sharper distribution (more confident)
- T = 1: Standard softmax
- T > 1: Flatter distribution (more random)
Sampling Strategies
Given probabilities, we can generate text by:
- Greedy: Always pick highest probability
- Sampling: Random sample from distribution
- Top-k: Sample from k most likely tokens
- Top-p (nucleus): Sample from smallest set summing to p
Series Navigation
Previous: Output Layer
Next: Scaling LLMs – nano-GPT to GPT-3
This article is part of the LLM Architecture Series. Interactive visualisations from bbycroft.net/llm.
Analogy and intuition
Think of logits as raw scores from many judges and softmax as the function that converts these scores into final vote percentages.
Because softmax is smooth and differentiable it works well with gradient based learning, and because it normalises values it produces intuitive probabilities.
Looking ahead
Next we will talk about scaling, which means changing the size of the model and the data to improve capability.