
LLM Architecture Series – Lesson 17 of 20. After many transformer layers, we have a final hidden vector for each position. The output layer turns this into raw scores for every token in the vocabulary.
This linear layer is often called the language model head and is where most parameters of the model live.
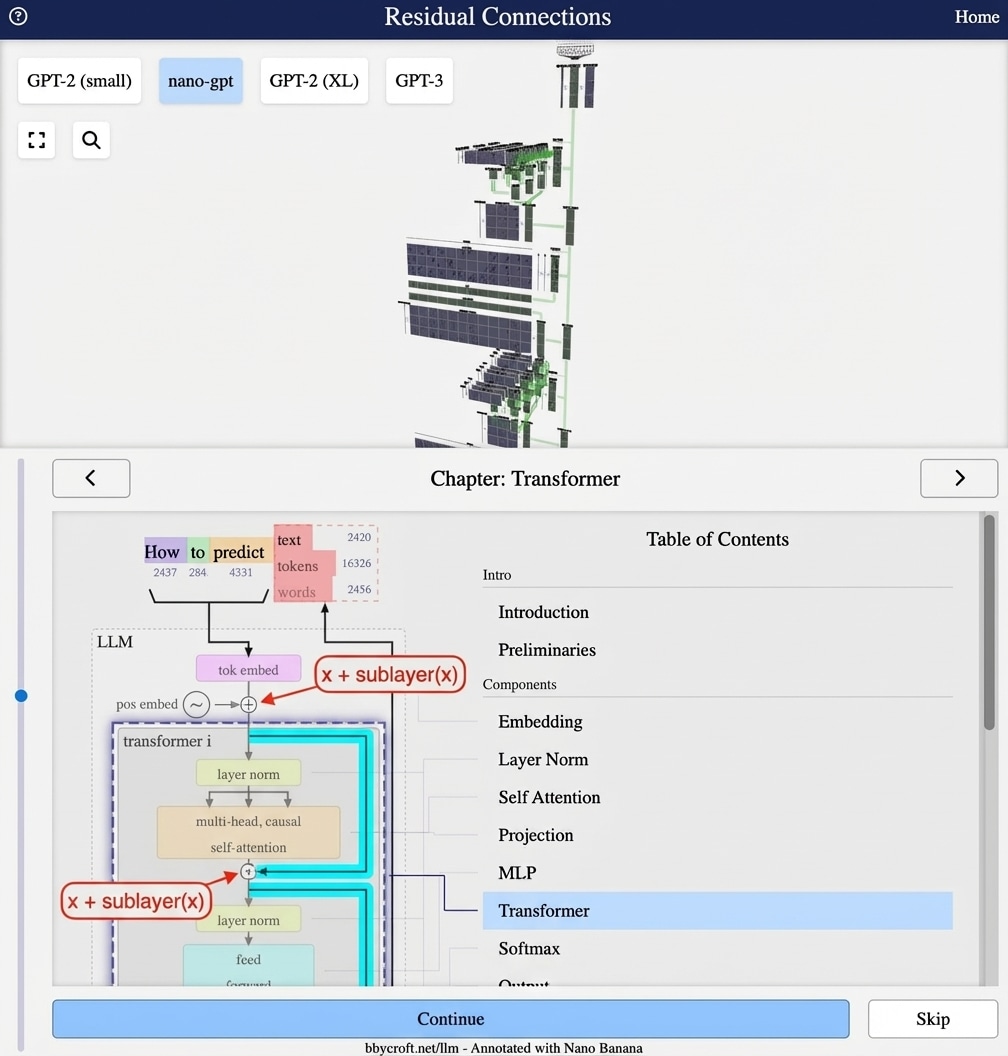
Visualisation from bbycroft.net/llm augmented by Nano Banana.
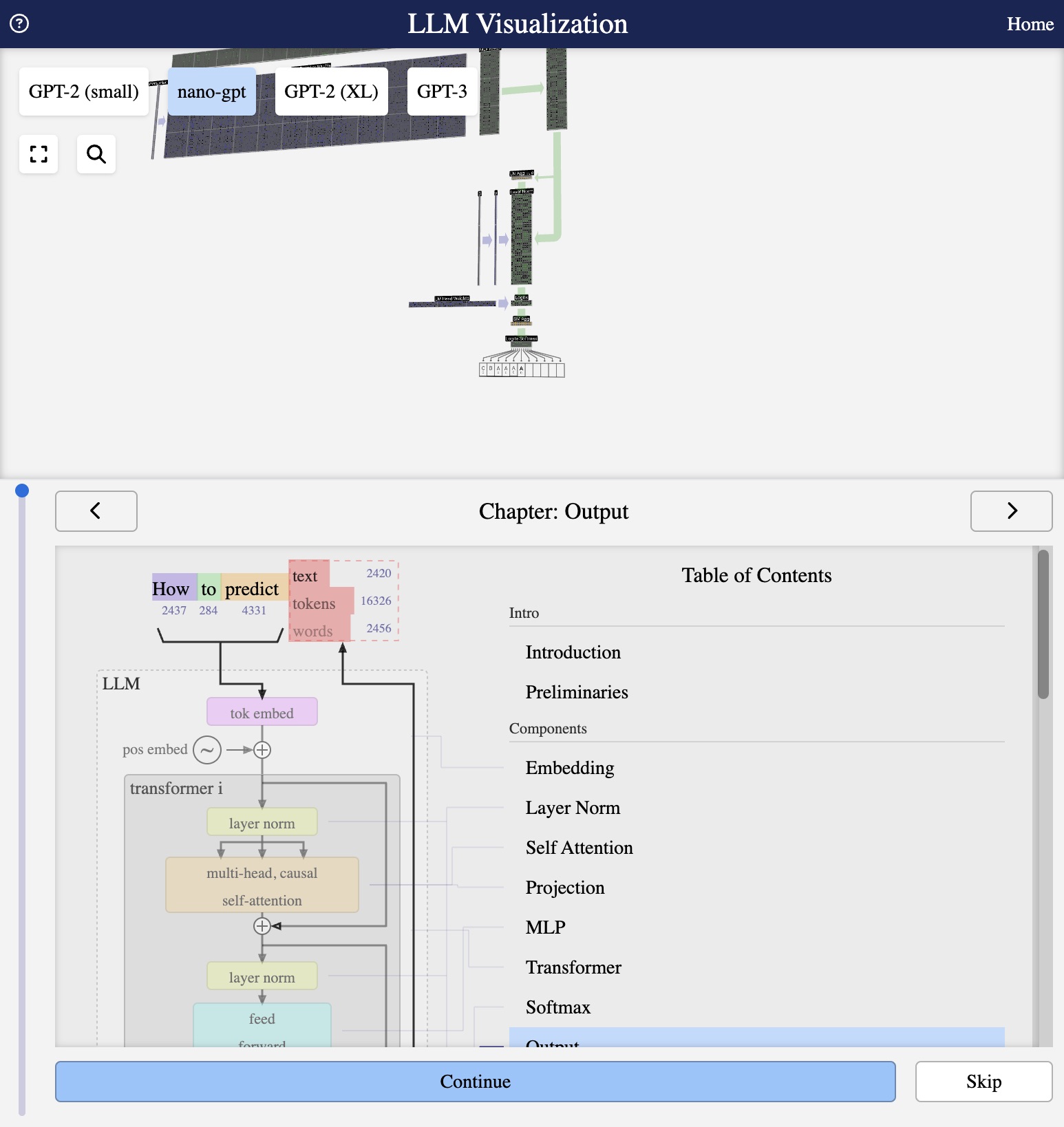
Visualisation from bbycroft.net/llm
From Representations to Predictions
After passing through all transformer blocks, we need to convert the final hidden states into predictions over the vocabulary. This is the job of the output layer.
The Language Model Head
The output layer (or “LM head”) projects from hidden dimension to vocabulary size:
logits = LayerNorm(hfinal) · Wvocab
Where:
- hfinal: Output from last transformer block (d dimensions)
- Wvocab: Projection matrix (d × V)
- logits: Raw scores for each vocabulary token (V dimensions)
Weight Tying
Many models use weight tying: the output projection matrix is the same as the token embedding matrix (transposed). This:
- Reduces parameters significantly
- Creates symmetry between input and output
- Often improves performance
Each Position Predicts Next Token
At each position i, the model outputs logits for predicting token i+1. During training, we have the actual next token to compare against.
Series Navigation
Previous: Stacking Layers
Next: From Logits to Probabilities – Softmax Output
This article is part of the LLM Architecture Series. Interactive visualisations from bbycroft.net/llm.
Analogy and intuition
You can think of the output layer as a large panel of dials, one for each possible next token. The hidden state decides how far to turn each dial up or down.
At this point the model has already done its reasoning. The output layer is just a final linear readout of those internal decisions.
Looking ahead
Next we will again use softmax, this time to convert vocabulary logits into actual probability values.