
LLM Architecture Series – Lesson 1 of 20. This article gives you the big picture of a modern language model before we zoom into each part.
You can think of a large language model as a very advanced auto complete engine that predicts the next token based on everything it has seen so far.
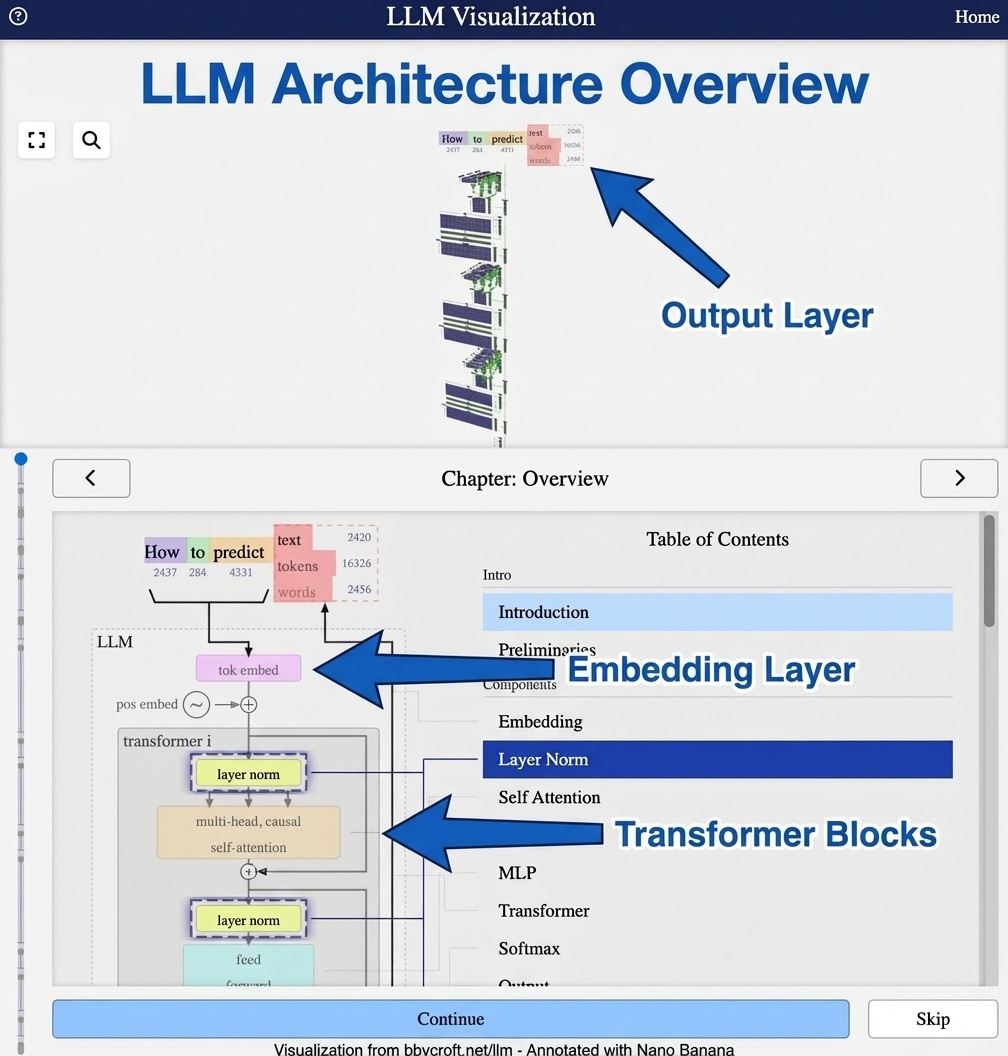
Visualisation from bbycroft.net/llm augmented by Nano Banana.
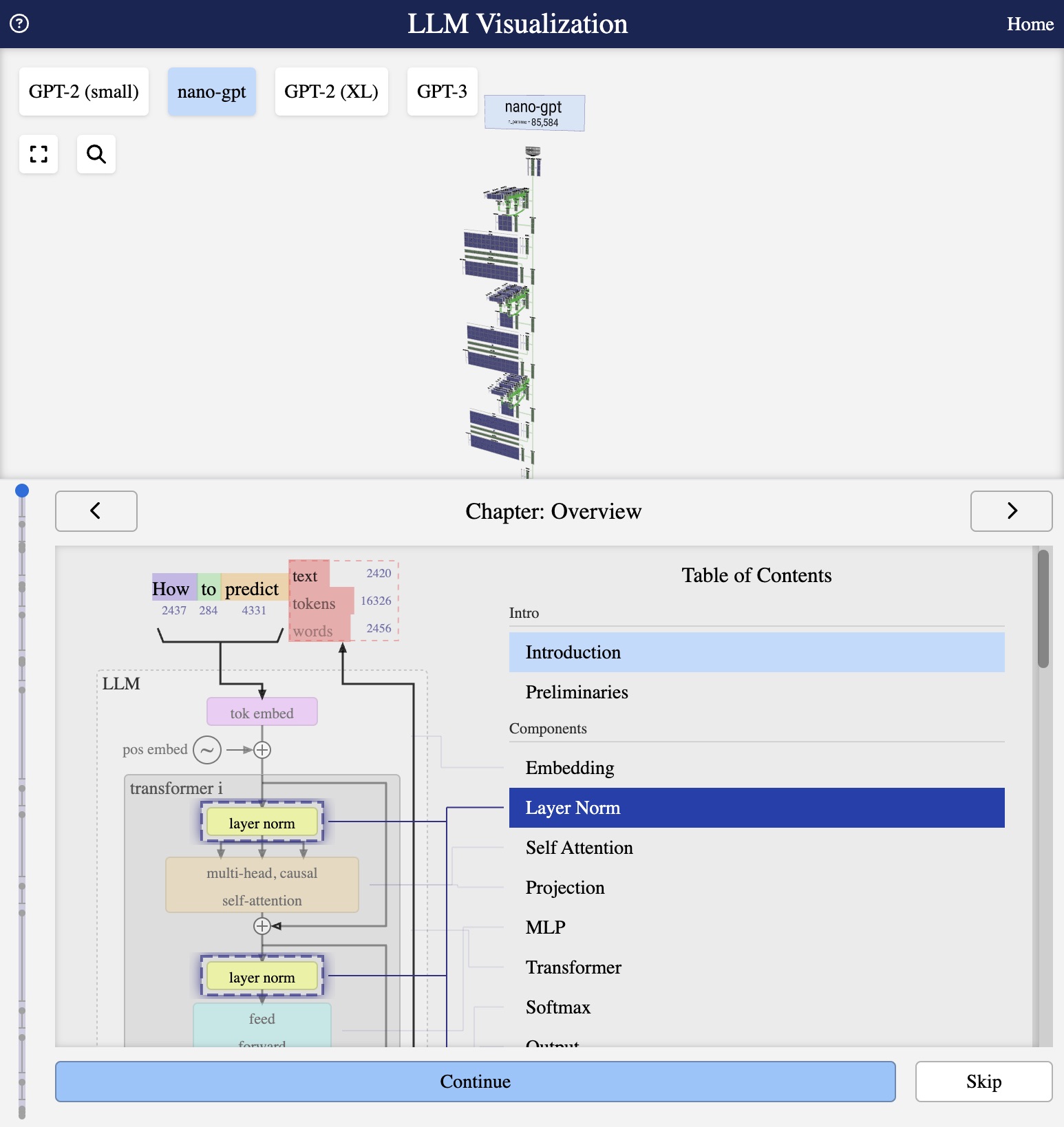
Visualisation from bbycroft.net/llm
What is a Large Language Model?
A Large Language Model (LLM) is a type of artificial intelligence that has been trained on vast amounts of text data to understand and generate human-like text. These models, part of the GPT (Generative Pre-trained Transformer) family, can be described as “context-based token predictors” – they predict the next word (or token) in a sequence based on all the previous words.
The visualisation above shows a complete LLM architecture – specifically nano-gpt, a minimal model with just 85,000 parameters. While production models like GPT-3 have 175 billion parameters, the fundamental architecture remains the same, making nano-gpt perfect for understanding how these systems work.
The Core Components
An LLM consists of several key components working together:
- Token Embedding – Converts input text into numerical vectors
- Position Embedding – Encodes the position of each word in the sequence
- Transformer Blocks – The heart of the model, containing attention and feed-forward layers
- Output Layer – Produces probability distributions over possible next tokens
How It Works: A Simple Example
Consider the input “How to predict”. The model:
- Breaks this into tokens: [“How”, “to”, “predict”]
- Converts each token to a vector embedding
- Adds position information
- Processes through transformer layers
- Outputs probabilities for what comes next
This series will walk through each component in detail, explaining the mathematics and intuition behind modern language models.
Series Navigation
Next: How LLMs Process Text – Tokenization Basics
This article is part of the LLM Architecture Series. Interactive visualisations from bbycroft.net/llm.
Analogy and intuition
Imagine a very dedicated reader who has read millions of books and tries to guess the next word in a sentence by remembering similar phrases from the past. The model does something similar but uses vectors and matrix multiplications instead of human memories.
Each block in the diagram is like a step in that reader thought process. First it converts words to numbers, then it decides which words are important, then it transforms this information several times before it produces a prediction.
Looking ahead
In the next lesson we look at tokenization which is how raw text is broken into the small pieces that the model can understand.