
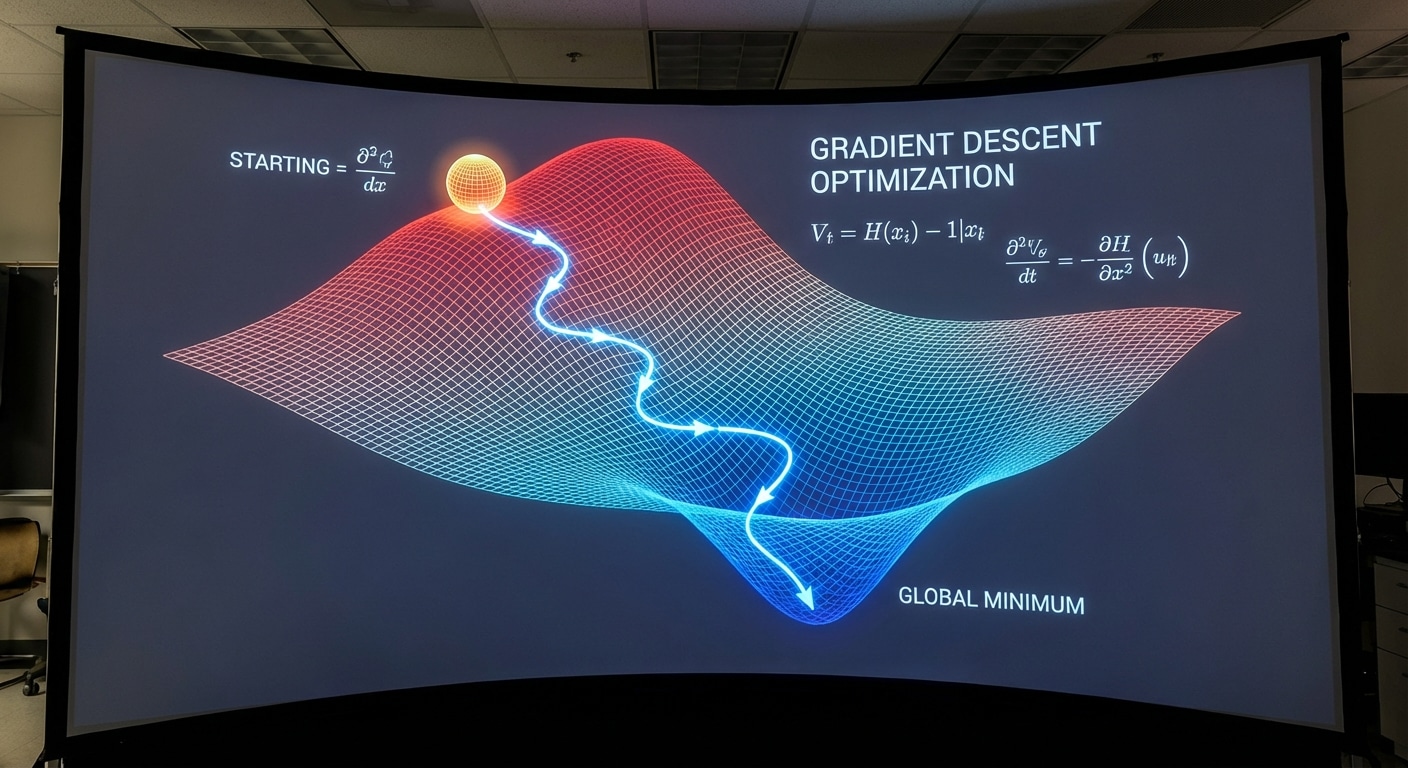
Gradient Descent: Finding Optimal Solutions
Gradient descent is the optimisation engine powering machine learning. It finds minimum error by iteratively moving in the direction of steepest descent on the loss surface. Understanding this algorithm is fundamental to training any neural network effectively.
Three main variants exist. Batch gradient descent uses the entire dataset per update – stable but slow. Stochastic gradient descent uses one sample – noisy but fast with implicit regularization. Mini-batch balances both using small batches of 32-512 samples.
Advanced optimisers improve upon vanilla gradient descent. Momentum accumulates velocity to escape local minima. RMSprop adapts learning rates per parameter. Adam combines both approaches and has become the default choice for most deep learning applications.
Learning rate scheduling further enhances training. Start with larger rates for fast progress, decay over time for fine convergence. Popular schedules include step decay, cosine annealing, and warmup followed by decay.