
Deep Learning: Layers of Abstraction
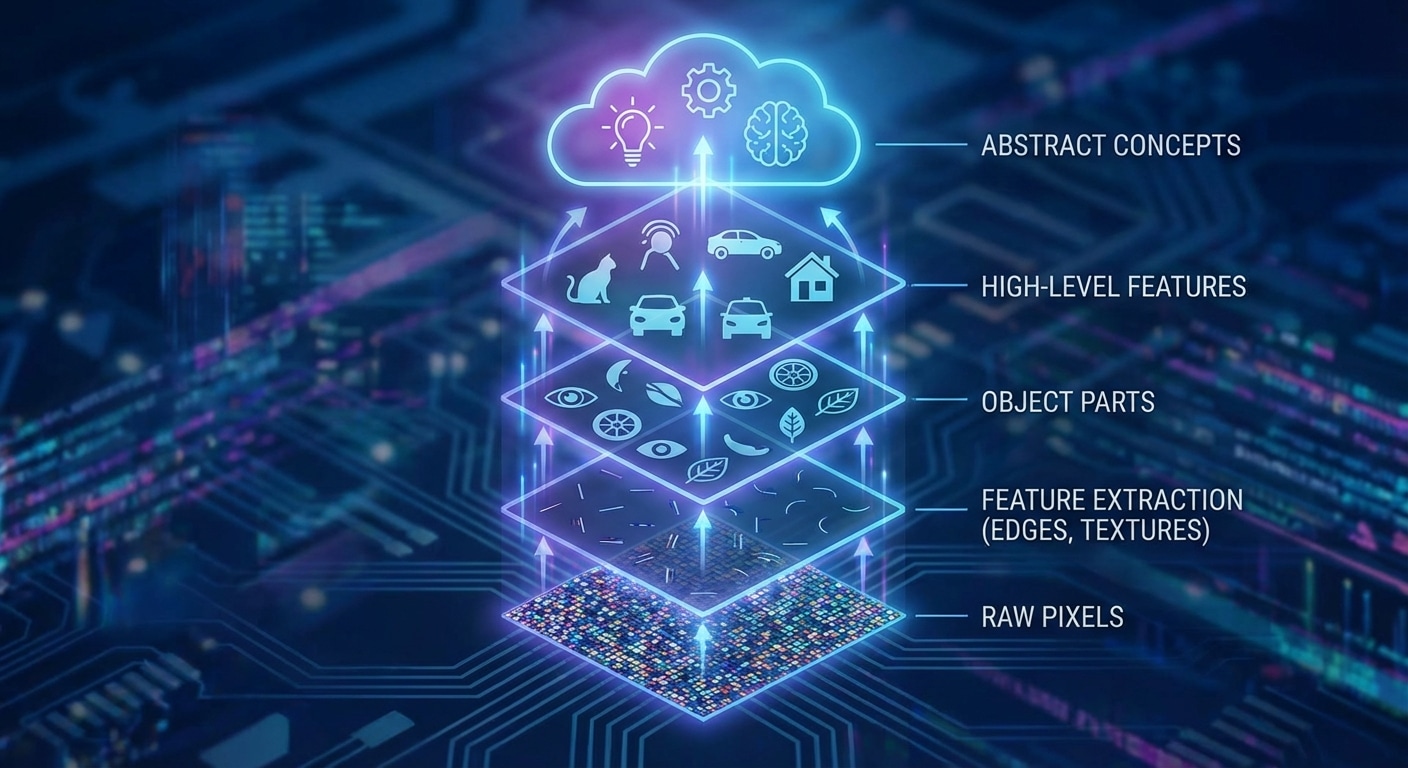
Deep learning derives its name from having many layers, but depth accomplishes more than just size. Each layer builds increasingly abstract representations, transforming raw inputs into meaningful features. This hierarchical learning mirrors how the visual cortex processes information from simple edges to complex objects.
In image recognition, early layers detect edges and simple patterns. Middle layers combine these into textures and shapes. Deeper layers recognise parts like eyes or wheels. Final layers identify complete objects and scenes. This progression from concrete to abstract happens automatically through training.
Deeper networks can represent more complex functions with fewer parameters than shallow networks. However, training deep networks historically faced the vanishing gradient problem where gradients became infinitesimally small in early layers. Innovations like ReLU activation and residual connections solved this, enabling networks with hundreds of layers.
Understanding layer-wise abstraction helps in architecture design and debugging. Visualising intermediate activations reveals what each layer learns. Transfer learning exploits this by reusing early general-purpose layers while fine-tuning later task-specific ones.