
Convolutional Neural Networks: How AI Sees
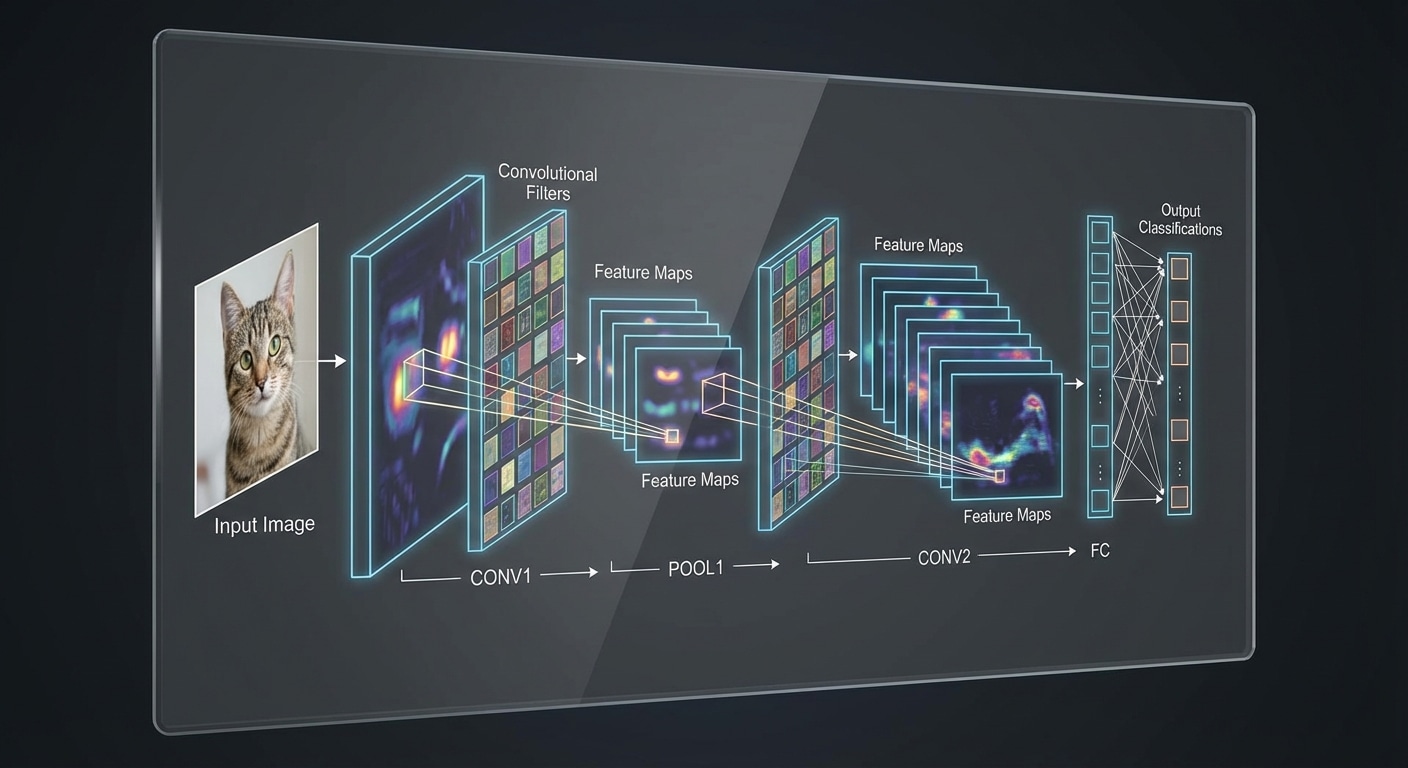
CNNs revolutionized computer vision by mimicking how the visual cortex processes images. Small learnable filters slide across the image detecting features, with early layers finding edges and later layers identifying complex objects. This hierarchical feature learning made accurate image recognition possible.
Key components include convolutional layers where filters detect local patterns, pooling layers that reduce spatial dimensions while preserving important features, and fully connected layers that combine features for final classification. The architecture dramatically reduces parameters through weight sharing.
CNNs achieve translation invariance – they detect features regardless of position in the image. A cat in the corner is recognised the same as one in the centre. This property emerges naturally from the sliding filter approach and makes CNNs robust to object placement.
Famous architectures include LeNet (1998), AlexNet (2012) which sparked the deep learning revolution, VGG demonstrating depth matters, ResNet enabling 100+ layer networks with skip connections, and modern EfficientNets balancing accuracy and efficiency. Each advanced our understanding of what makes CNNs effective.