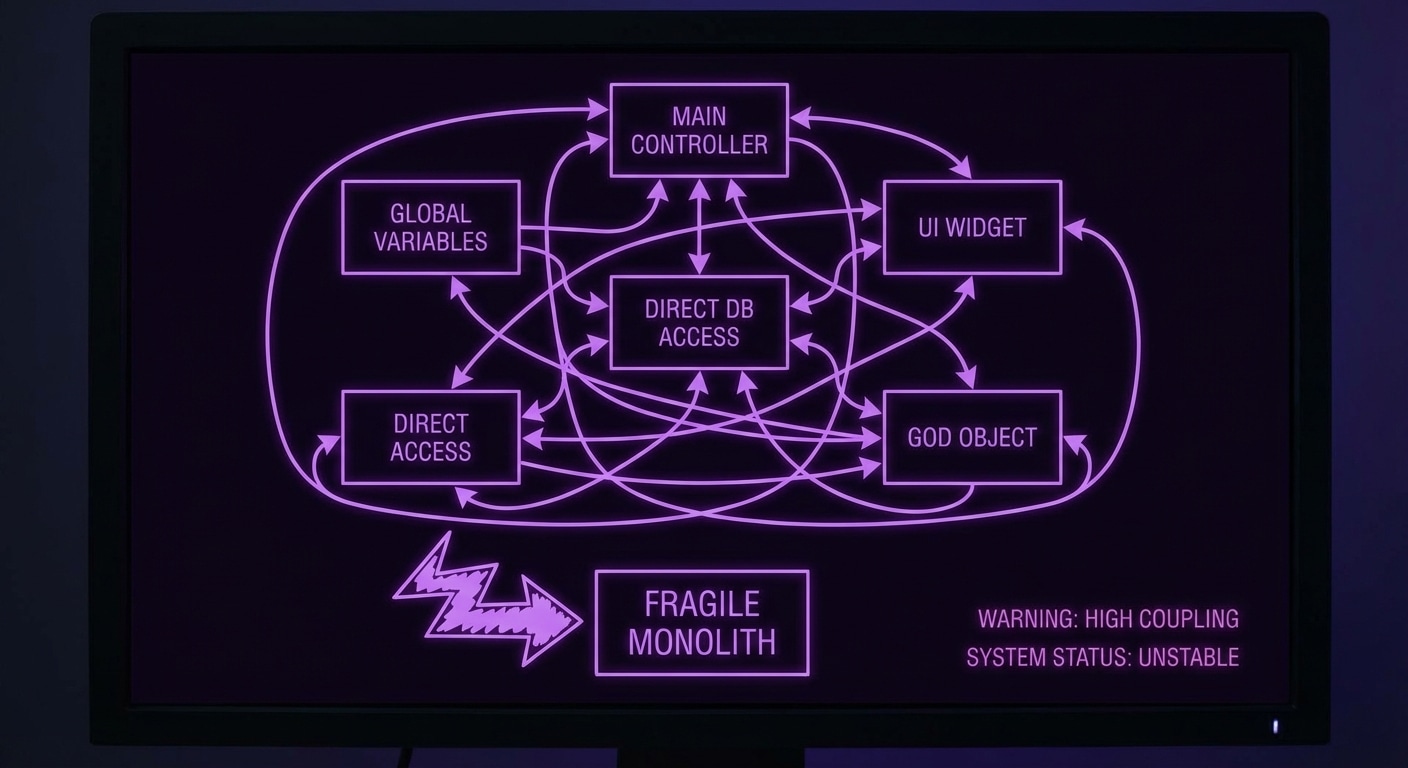
LLMs are probabilistic: they score and sample continuations. They’re great at “how do I do X?”, creative, fuzzy, pattern-matching. They’re bad at “is this true for all cases?” or “what’s missing?”, exhaustive, logical, deductive. Formal reasoning engines (theorem provers, logic engines, constraint solvers) are the opposite: they derive from rules and facts; they don’t guess. So one brain (the system) can combine two engines: the LLM for generation and the engine for verification or discovery of gaps.
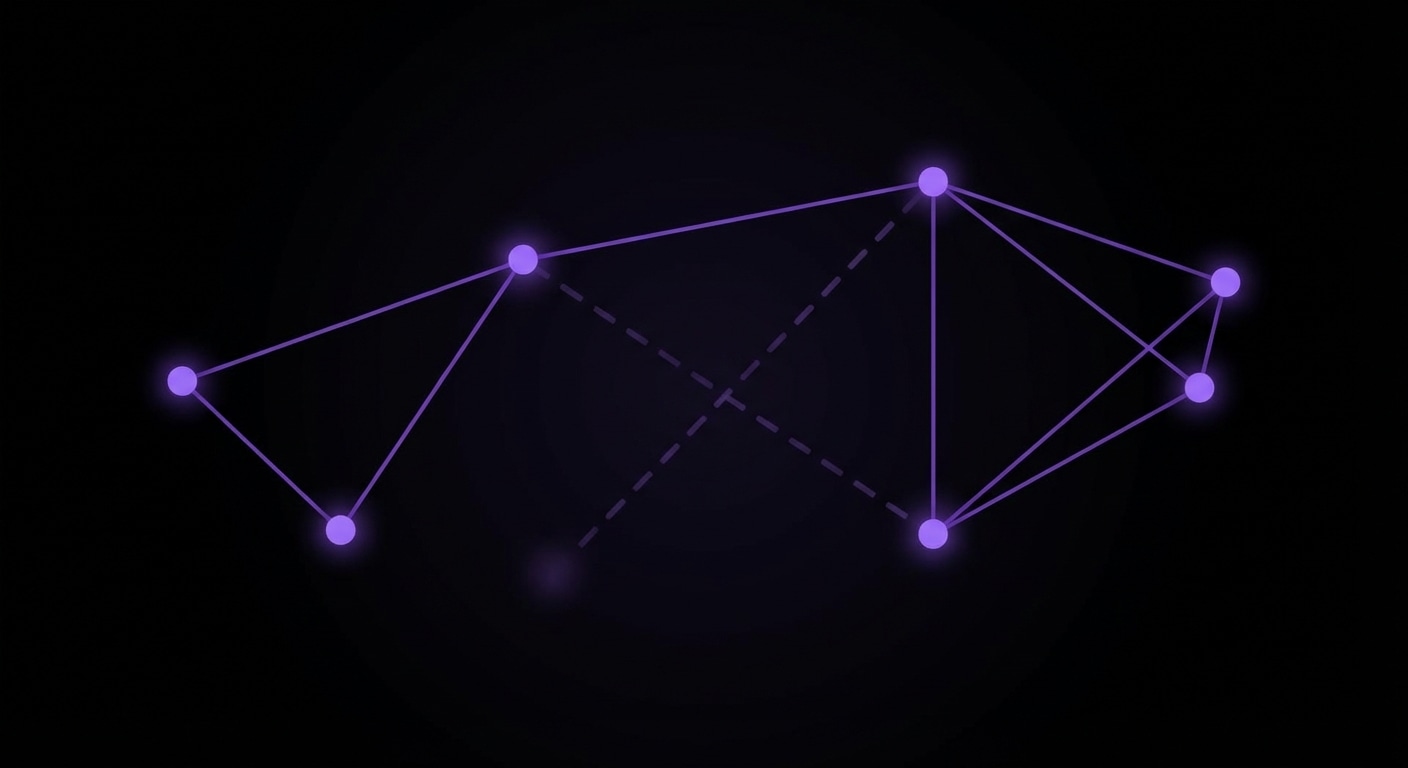
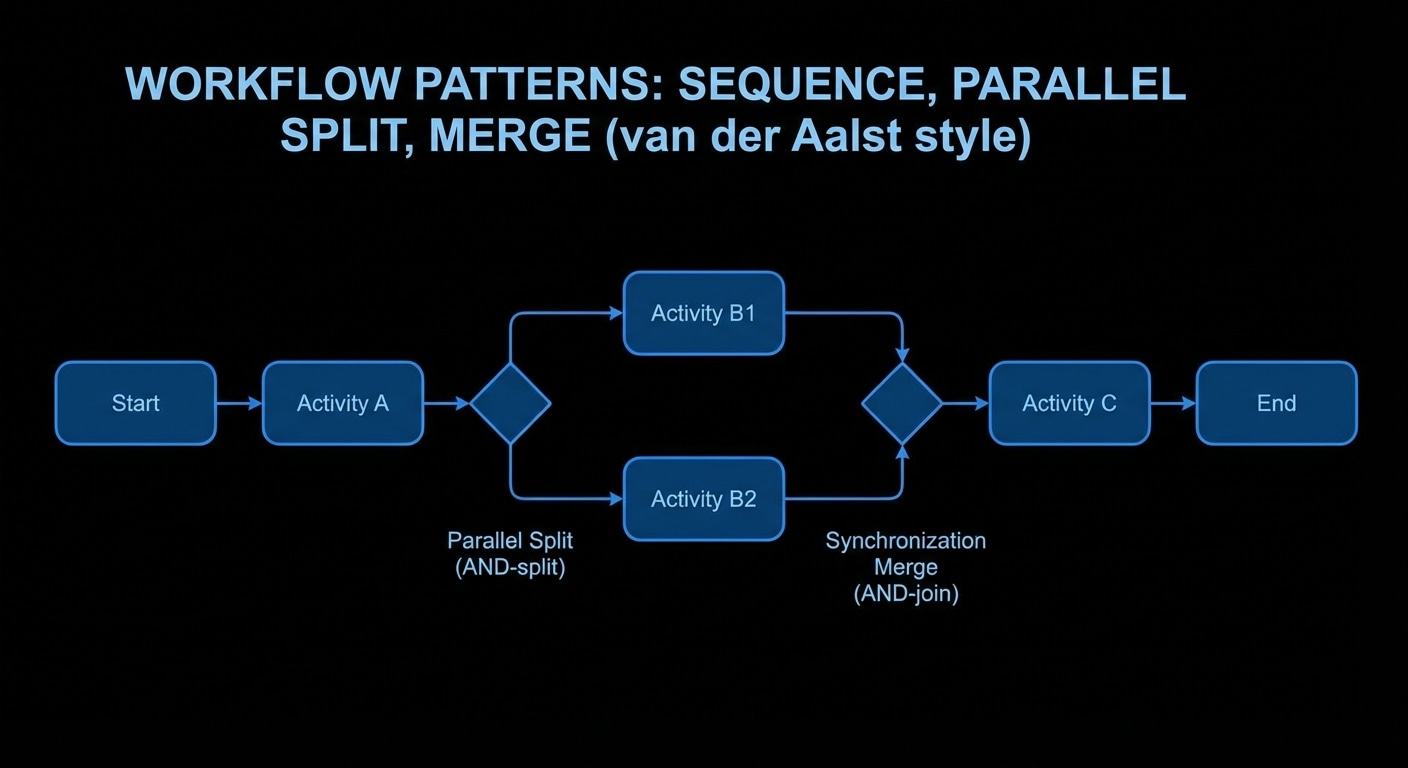
The combination works when the LLM produces a candidate (code, a state machine, a set of facts) and the engine checks it. The engine might ask: is every state reachable? Is there a deadlock? Is there a state with no error transition? The engine doesn’t need to understand the domain; it reasons over the shape. So you get “LLM proposes, engine disposes”, the model does the creative part, the engine does the precise part. Neither can do the other’s job well.
In practice the engine might be Prolog, an SMT solver, a custom rule set, or a model checker. The key is that it’s deterministic and exhaustive over the structure you give it. The LLM’s job is to translate (e.g. code into facts or a spec) and to implement fixes when the engine finds a problem. The engine’s job is to find what’s missing or inconsistent. Two engines, one workflow.
We’re not yet at “one brain” in a single model. We’re at “two engines in one system.” The progress will come from better translation (LLM to formal form) and better feedback (engine to LLM) so that the loop is tight and the user gets correct, structurally sound output.
Expect more research and products that pair LLMs with deductive back ends for code, specs, and workflows.
nJoy 😉