
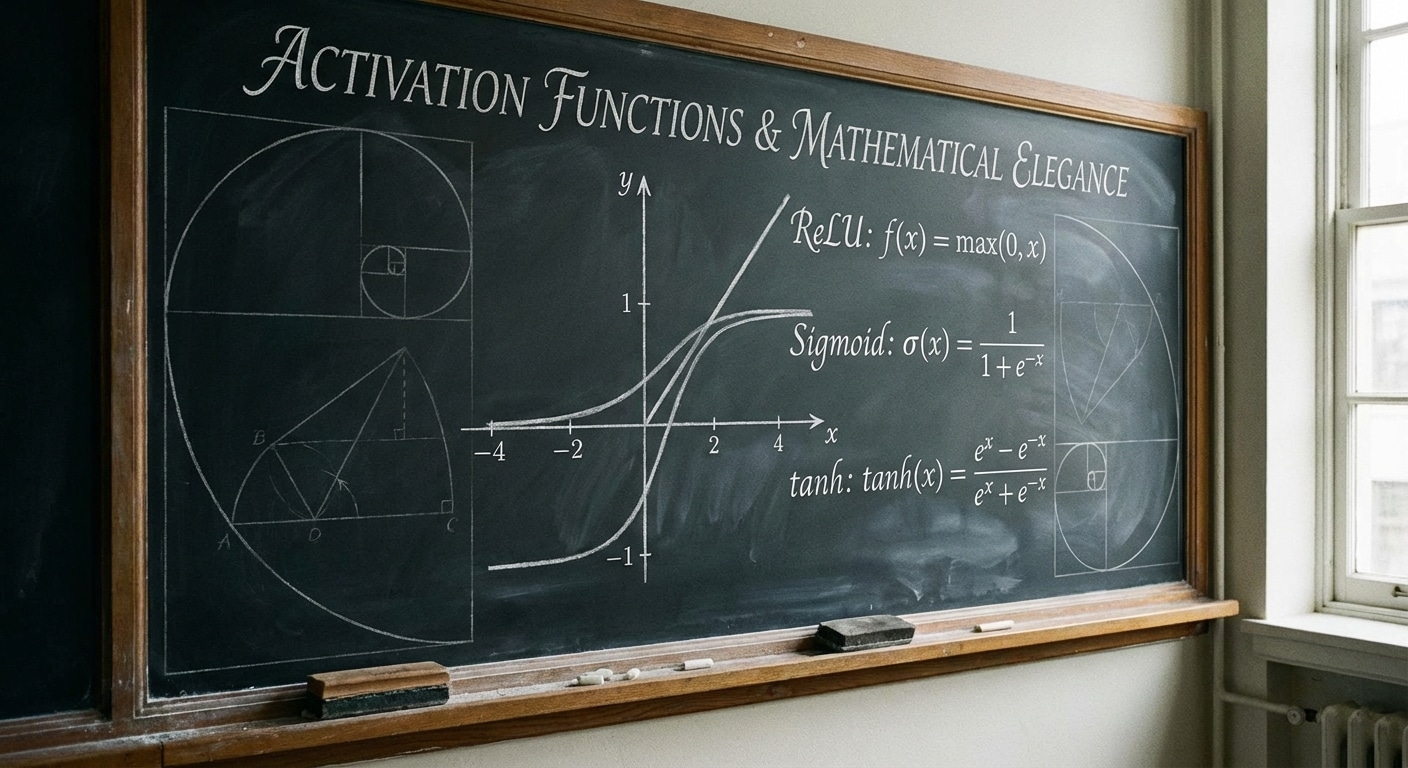
Activation Functions: The Key to Non-Linearity
Without activation functions, neural networks would be limited to linear transformations no matter how many layers they have. Activations introduce non-linearity, enabling networks to learn complex patterns like image recognition and language understanding that linear models cannot capture.
ReLU (Rectified Linear Unit) outputs max(0,x) – simple, fast, and surprisingly effective. It has become the default for hidden layers. Sigmoid squashes output to 0-1, useful for binary classification but prone to vanishing gradients. Tanh outputs -1 to 1, zero-centred which sometimes helps training.
For output layers, the choice depends on your task. Sigmoid for binary classification, softmax for multi-class (outputs sum to 1 as probabilities), and linear for regression. Modern variants like GELU and Swish offer slight improvements in specific contexts.
Understanding activations helps diagnose training issues. Dead ReLU neurons that never activate, saturated sigmoids causing vanishing gradients, and numerical instability all relate to activation choice. Experimentation within established guidelines usually yields good results.