
LLM Architecture Series – Lesson 15 of 20. Now we bring all familiar components together into the standard transformer block.
Each block contains attention, MLP, layer norms, and residual paths wired in a specific order.
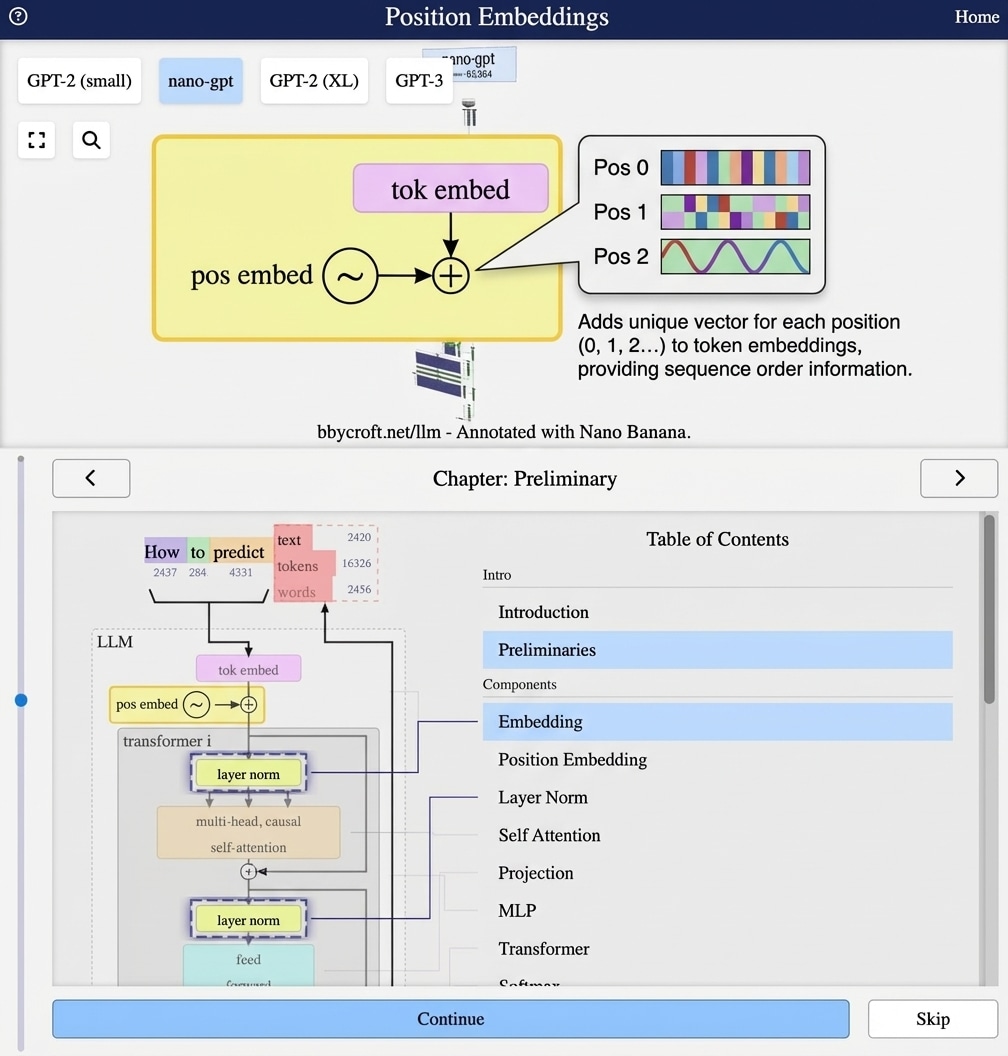
Visualization from bbycroft.net/llm augmented by Nano Banana.
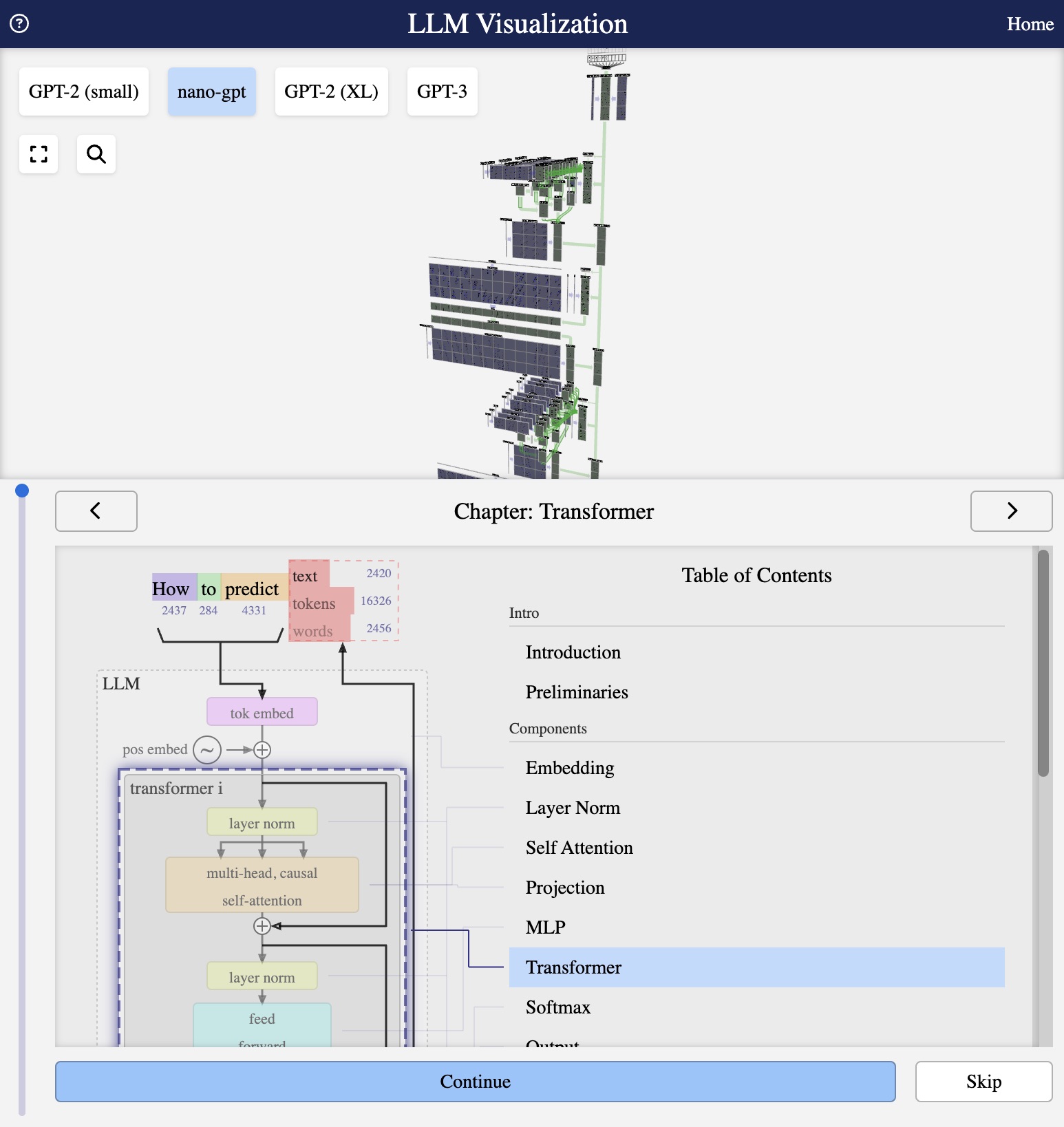
Visualization from bbycroft.net/llm
Putting It All Together
A transformer block combines all the components we have discussed into a single unit. GPT models stack multiple identical blocks to create deep networks.
The Block Architecture
Each transformer block contains (in order):
- Layer Norm (Pre-normalization)
- Multi-Head Self-Attention
- Residual Connection
- Layer Norm
- Feed-Forward Network (MLP)
- Residual Connection
The Complete Formula
h = x + MultiHeadAttention(LayerNorm(x))
output = h + FFN(LayerNorm(h))
Pre-LN vs Post-LN
GPT uses Pre-LN (LayerNorm before each sublayer), which:
- Makes training more stable
- Allows larger learning rates
- Enables training very deep networks
Parameters Per Block
For nano-gpt (d=48, 3 heads, 4x expansion):
- Attention: 4 × 48 × 48 = 9,216 parameters
- FFN: 2 × 48 × 192 = 18,432 parameters
- LayerNorm: 2 × 2 × 48 = 192 parameters
- Total per block: ~28,000 parameters
Series Navigation
Previous: Residual Connections
Next: Stacking Transformer Layers
This article is part of the LLM Architecture Series. Interactive visualizations from bbycroft.net/llm.
Analogy and intuition
You can think of a transformer block as one full reasoning step. Information flows in, attends to other positions, is processed by an MLP, and then passed on along residual paths.
Stacking many such blocks lets the model refine its understanding over multiple passes, similar to revisiting the same text with deeper insight each time.
Looking ahead
Next we will see what happens when we stack many transformer blocks on top of each other.