
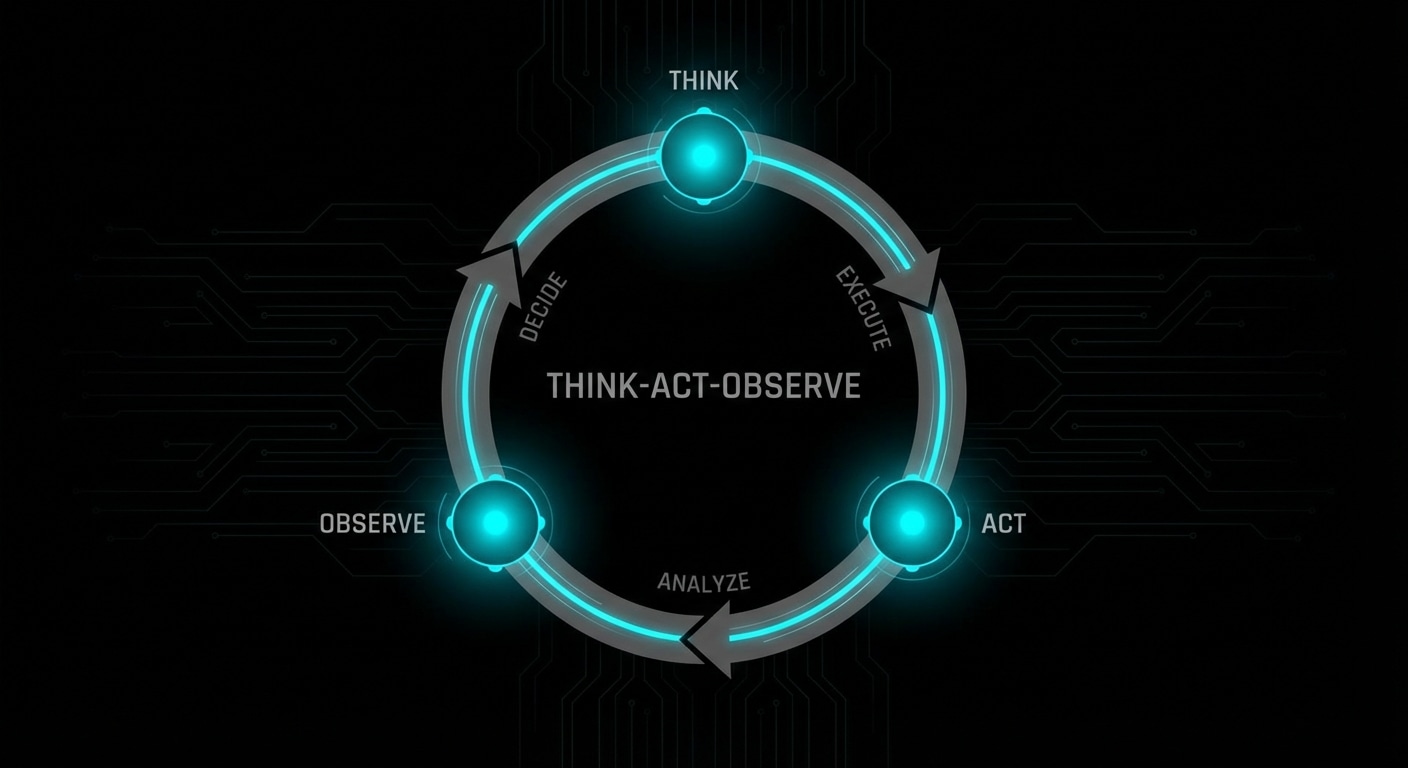
ReAct stands for Reason, Act, Observe. It’s a pattern for getting LLMs to use tools in a structured way: the model outputs a thought (reasoning), then an action (e.g. call this tool with these args), then you run the action and feed the result back as the observation. The model then reasons again and either takes another action or gives a final answer. That alternation of reasoning and acting reduces the chance the model “hallucinates” a tool result or skips a step.
In practice you prompt the model with a format like “Thought: … Action: tool_name(args). Observation: …” and parse the output to extract the action. You execute the action (API call, code run, search), append “Observation: <result>” to the conversation, and send it back. The model’s next turn is another Thought and possibly another Action. You keep going until the model outputs “Final Answer: …” or you hit a step limit.
ReAct doesn’t require special training, it’s a prompting and parsing discipline. Many agent frameworks (LangChain, AutoGPT-style setups, and custom loops) implement something like it. The key is that the model “sees” the result of each action before deciding the next one, so it can recover from mistakes and chain multiple tools.
The downside is token cost: every thought and action is in the context, so long tasks can blow up context length. You often summarise or truncate old steps. Also, the model can still output malformed actions or infinite loops, so you need timeouts and retries.
ReAct is one of the main patterns that make agents practical today. Expect it to evolve into more structured formats (e.g. JSON actions) and tighter integration with function-calling APIs.
nJoy 😉