
The previous lesson established the differences between OpenAI, Claude, and Gemini. This lesson turns those differences into a Node.js abstraction layer that makes the provider transparent to the rest of your application. You write tool logic once, define a routing policy, and the layer handles schema conversion, message format, retry, and result normalization automatically. This is the architecture that makes multi-provider MCP applications maintainable at scale.
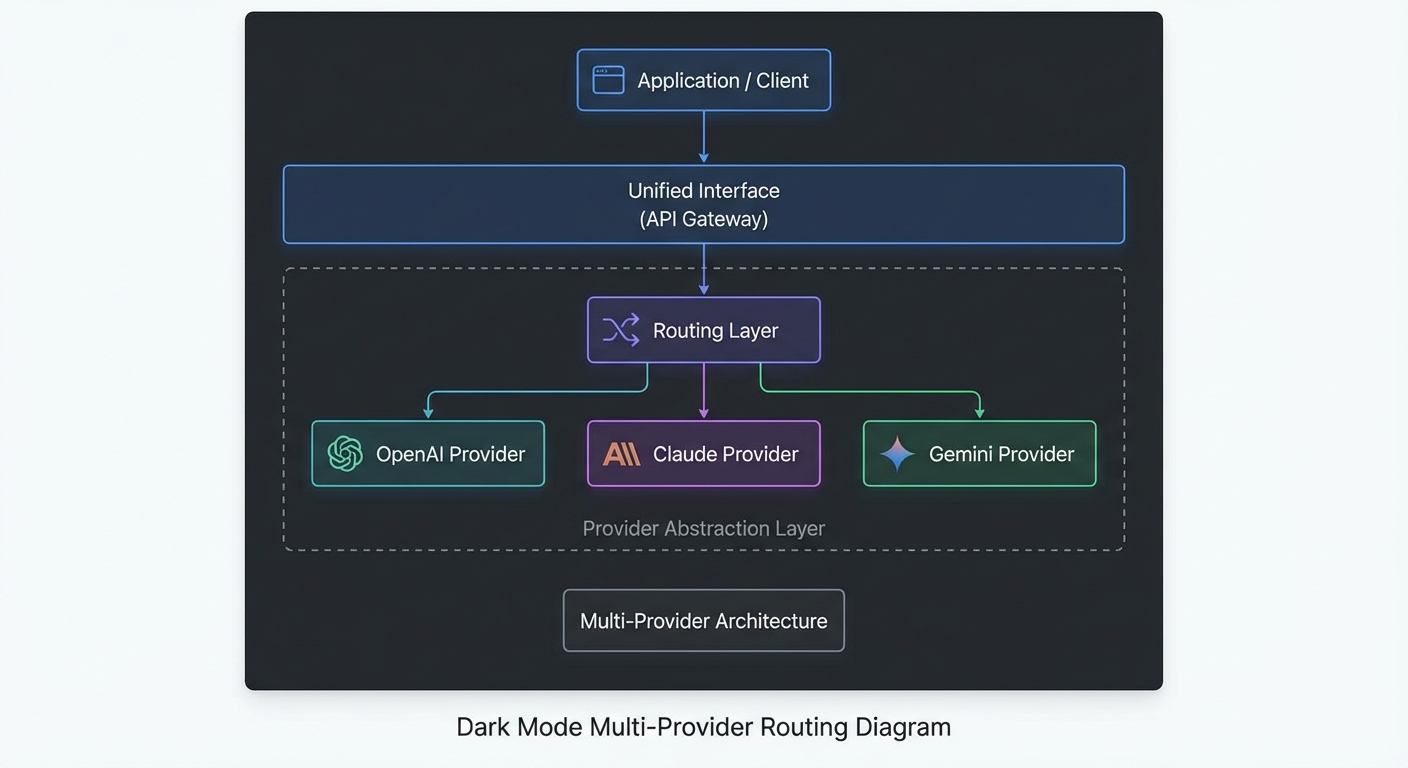
The Core Interface
Define a common interface first. Every provider adapter must implement run(messages, tools) and return a normalized result:
// lib/providers/base.js
/**
* @typedef {Object} ProviderResult
* @property {string} text - The model's final text response
* @property {number} inputTokens - Tokens consumed in input
* @property {number} outputTokens - Tokens consumed in output
* @property {number} turns - Number of tool-calling turns
*/
/**
* Base class for LLM provider adapters.
* Subclasses implement #callModel(messages, tools) and #extractToolCalls(response).
*/
export class BaseProvider {
constructor(config = {}) {
this.config = {
maxTurns: config.maxTurns ?? 10,
maxRetries: config.maxRetries ?? 3,
...config,
};
}
/**
* Run a complete tool-calling loop.
* @param {string} userMessage
* @param {import('@modelcontextprotocol/sdk').Client} mcpClient
* @returns {Promise<ProviderResult>}
*/
async run(userMessage, mcpClient) {
const { tools: mcpTools } = await mcpClient.listTools();
const providerTools = this.convertTools(mcpTools);
return this._runLoop(userMessage, mcpClient, providerTools);
}
// Subclasses override these
convertTools(mcpTools) { throw new Error('Not implemented'); }
async callModel(messages, tools) { throw new Error('Not implemented'); }
extractToolCalls(response) { throw new Error('Not implemented'); }
extractText(response) { throw new Error('Not implemented'); }
extractUsage(response) { return { inputTokens: 0, outputTokens: 0 }; }
buildToolResultMessage(toolCallId, name, result) { throw new Error('Not implemented'); }
}
This base class defines the contract that every provider adapter must honor. By making convertTools, callModel, and extractToolCalls abstract methods, you guarantee that adding a new provider (like Mistral or Cohere) requires implementing a fixed set of behaviors rather than threading new logic through your entire application.
OpenAI Adapter
// lib/providers/openai.js
import OpenAI from 'openai';
import { BaseProvider } from './base.js';
export class OpenAIProvider extends BaseProvider {
#client;
constructor(config = {}) {
super(config);
this.#client = new OpenAI();
this.model = config.model ?? 'gpt-4o';
}
convertTools(mcpTools) {
return mcpTools.map(t => ({
type: 'function',
function: { name: t.name, description: t.description, parameters: t.inputSchema, strict: true },
}));
}
async callModel(messages, tools) {
return this.#client.chat.completions.create({
model: this.model, messages, tools, tool_choice: 'auto',
});
}
extractToolCalls(response) {
const msg = response.choices[0].message;
if (msg.finish_reason !== 'tool_calls') return [];
return msg.tool_calls.map(tc => ({
id: tc.id, name: tc.function.name,
args: JSON.parse(tc.function.arguments),
}));
}
extractText(response) {
return response.choices[0].message.content ?? '';
}
extractUsage(response) {
return { inputTokens: response.usage.prompt_tokens, outputTokens: response.usage.completion_tokens };
}
buildAssistantMessage(response) {
return response.choices[0].message;
}
buildToolResultMessage(toolCallId, name, result) {
return { role: 'tool', tool_call_id: toolCallId, content: result };
}
async _runLoop(userMessage, mcpClient, tools) {
const messages = [{ role: 'user', content: userMessage }];
let totalInput = 0, totalOutput = 0, turns = 0;
while (true) {
const response = await this.callModel(messages, tools);
const usage = this.extractUsage(response);
totalInput += usage.inputTokens; totalOutput += usage.outputTokens;
const toolCalls = this.extractToolCalls(response);
if (toolCalls.length === 0) {
return { text: this.extractText(response), inputTokens: totalInput, outputTokens: totalOutput, turns };
}
if (++turns > this.config.maxTurns) throw new Error('Max turns exceeded');
messages.push(this.buildAssistantMessage(response));
const results = await Promise.all(toolCalls.map(async tc => {
const result = await mcpClient.callTool({ name: tc.name, arguments: tc.args });
const text = result.content.filter(c => c.type === 'text').map(c => c.text).join('\n');
return this.buildToolResultMessage(tc.id, tc.name, text);
}));
messages.push(...results);
}
}
}
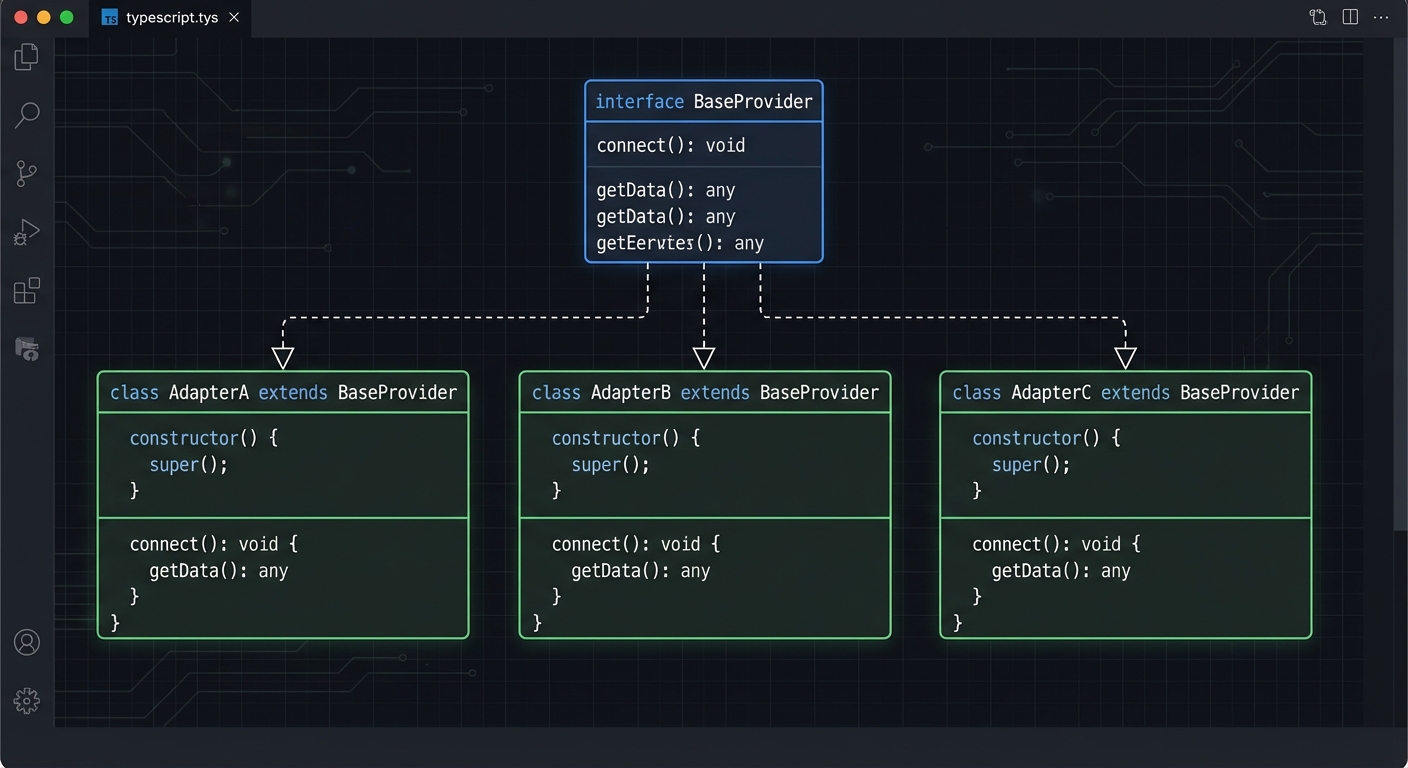
The OpenAI adapter is the most verbose of the three because OpenAI’s message format requires the most wrapping: tool calls live in tool_calls arrays, arguments arrive as JSON strings that need parsing, and results go back as separate role: 'tool' messages. The adapter absorbs all of this complexity so your application code stays clean.
Claude Adapter
// lib/providers/claude.js
import Anthropic from '@anthropic-ai/sdk';
import { BaseProvider } from './base.js';
export class ClaudeProvider extends BaseProvider {
#client;
constructor(config = {}) {
super(config);
this.#client = new Anthropic();
this.model = config.model ?? 'claude-3-5-sonnet-20241022';
}
convertTools(mcpTools) {
return mcpTools.map(t => ({ name: t.name, description: t.description, input_schema: t.inputSchema }));
}
async callModel(messages, tools) {
return this.#client.messages.create({
model: this.model, max_tokens: 4096, messages, tools,
});
}
extractToolCalls(response) {
if (response.stop_reason !== 'tool_use') return [];
return response.content
.filter(b => b.type === 'tool_use')
.map(b => ({ id: b.id, name: b.name, args: b.input }));
}
extractText(response) {
return response.content.filter(b => b.type === 'text').map(b => b.text).join('');
}
extractUsage(response) {
return { inputTokens: response.usage.input_tokens, outputTokens: response.usage.output_tokens };
}
async _runLoop(userMessage, mcpClient, tools) {
const messages = [{ role: 'user', content: userMessage }];
let totalInput = 0, totalOutput = 0, turns = 0;
while (true) {
const response = await this.callModel(messages, tools);
const usage = this.extractUsage(response);
totalInput += usage.inputTokens; totalOutput += usage.outputTokens;
const toolCalls = this.extractToolCalls(response);
if (toolCalls.length === 0) {
return { text: this.extractText(response), inputTokens: totalInput, outputTokens: totalOutput, turns };
}
if (++turns > this.config.maxTurns) throw new Error('Max turns exceeded');
messages.push({ role: 'assistant', content: response.content });
const results = await Promise.all(toolCalls.map(async tc => {
const result = await mcpClient.callTool({ name: tc.name, arguments: tc.args });
const text = result.content.filter(c => c.type === 'text').map(c => c.text).join('\n');
return { type: 'tool_result', tool_use_id: tc.id, content: text };
}));
messages.push({ role: 'user', content: results });
}
}
}
Compare the Claude adapter’s _runLoop to the OpenAI version above. The structure is nearly identical, but the message format differs in subtle ways: tool results nest inside a user message as content blocks rather than standing alone as tool role messages. These small differences are exactly what the abstraction layer exists to hide.
The Provider Router
// lib/providers/router.js
import { OpenAIProvider } from './openai.js';
import { ClaudeProvider } from './claude.js';
import { GeminiProvider } from './gemini.js';
/**
* Route a task to the appropriate provider based on task type.
*/
export class ProviderRouter {
#providers;
#defaultProvider;
constructor(config = {}) {
this.#providers = {
openai: new OpenAIProvider(config.openai ?? {}),
claude: new ClaudeProvider(config.claude ?? {}),
gemini: new GeminiProvider(config.gemini ?? {}),
};
this.#defaultProvider = config.default ?? 'openai';
}
/**
* Route based on task type.
* @param {'reasoning' | 'multimodal' | 'highvolume' | 'default'} taskType
*/
getProvider(taskType = 'default') {
const routing = {
reasoning: 'claude', // Extended thinking, deep analysis
multimodal: 'gemini', // Images, PDFs, audio
highvolume: 'gemini', // Cheapest per-token option
structured: 'openai', // Strict JSON, Agents SDK
default: this.#defaultProvider,
};
const key = routing[taskType] ?? this.#defaultProvider;
return this.#providers[key];
}
async run(userMessage, mcpClient, taskType = 'default') {
const provider = this.getProvider(taskType);
return provider.run(userMessage, mcpClient);
}
}
The router’s task-type mapping is deliberately simple. In production, you might extend it with quality scores from an eval harness, latency percentiles from your monitoring stack, or dynamic cost thresholds that shift routing as budgets tighten. The important thing is that routing logic lives in one place, not scattered across your codebase.
Using the Router
import { ProviderRouter } from './lib/providers/router.js';
import { Client } from '@modelcontextprotocol/sdk/client/index.js';
import { StdioClientTransport } from '@modelcontextprotocol/sdk/client/stdio.js';
const router = new ProviderRouter({
default: 'openai',
openai: { model: 'gpt-4o-mini' },
claude: { model: 'claude-3-7-sonnet-20250219' },
gemini: { model: 'gemini-2.0-flash' },
});
const mcp = new Client({ name: 'multi-provider-host', version: '1.0.0' });
await mcp.connect(new StdioClientTransport({ command: 'node', args: ['./server.js'] }));
// Simple query -> cheapest OpenAI model
const r1 = await router.run('What products are low in stock?', mcp, 'default');
// Complex analysis -> Claude
const r2 = await router.run('Analyze our Q1 sales data and identify the top 3 growth opportunities', mcp, 'reasoning');
// Document analysis -> Gemini
const r3 = await router.run('Process the attached invoice PDF', mcp, 'multimodal');
console.log(r1.text);
console.log(`Tokens: ${r1.inputTokens} in / ${r1.outputTokens} out`);
await mcp.close();
Notice that the calling code never imports a provider SDK directly. It only knows about ProviderRouter and the MCP Client. This means you can swap providers, change models, or adjust routing rules without modifying any of your application’s business logic. That separation is what makes multi-provider systems maintainable over time.
Failure Modes in Multi-Provider Systems
- Leaky abstractions: Avoid leaking provider-specific features (like OpenAI’s
zodResponseFormator Claude’scache_control) through the abstraction layer. If you need them, expose them via provider-specific method extensions, not the base interface. - Tool schema compatibility: Not all JSON Schema features work equally across providers. Test your tool schemas against all target providers, especially nested objects,
anyOf, and enum arrays. - Cost accounting per provider: Log
result.inputTokensandresult.outputTokensper provider and task type. Without this, you cannot measure whether your routing policy is saving money.
What to Build Next
- Implement the Gemini adapter following the same pattern as the OpenAI and Claude adapters above.
- Add a
fallbackoption to the router: if the primary provider returns a 429, automatically retry on the fallback provider.
nJoy 😉