
The gap between “demo that calls a tool” and “production client that handles 10,000 daily users” is everything we have not talked about yet: connection pooling, retry logic, cost control, token budget management, error classification, telemetry, and graceful degradation. This lesson builds a production-grade OpenAI MCP client library from scratch – the kind you would actually deploy in a company. Every pattern here comes from real production failure modes.
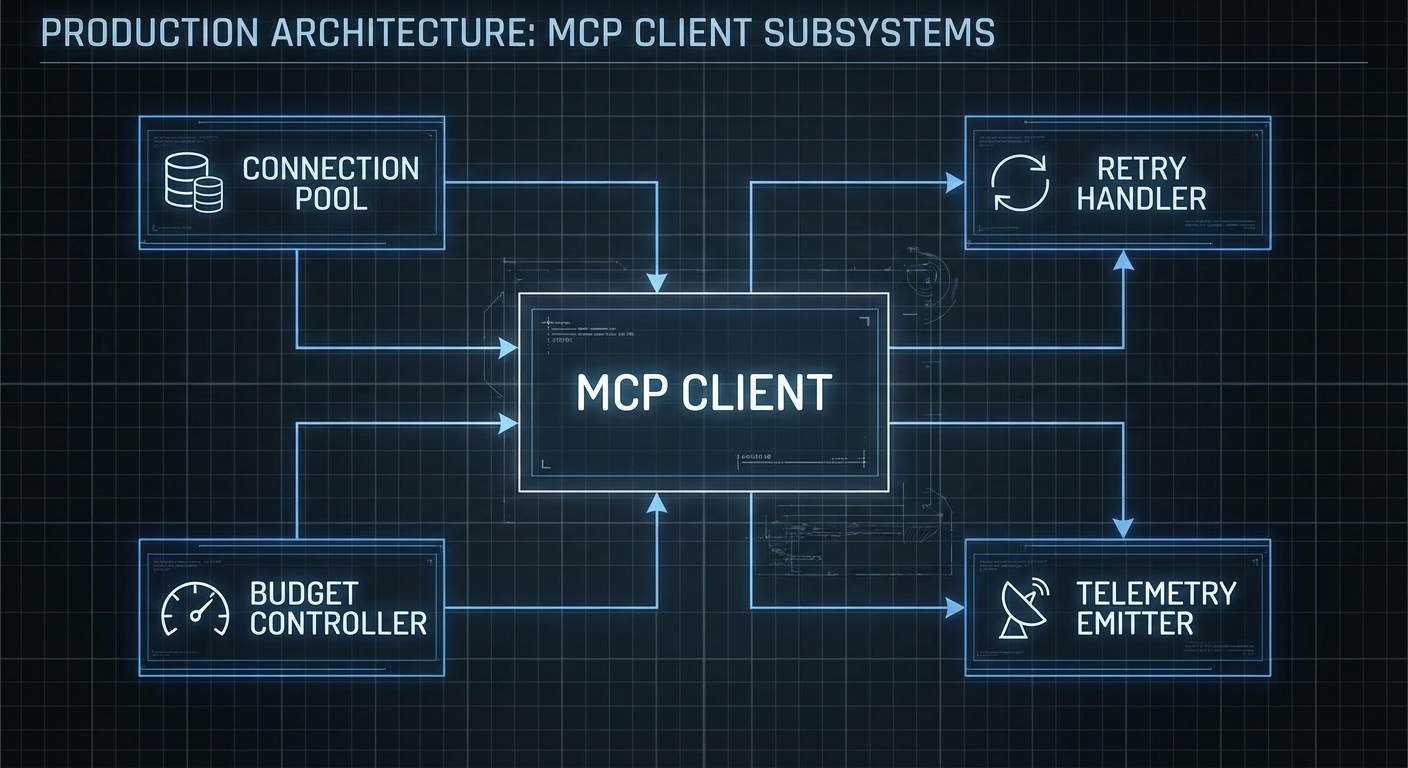
The Production Client Library
// mcp-openai-client.js - Production-grade MCP + OpenAI client
import OpenAI from 'openai';
import { Client } from '@modelcontextprotocol/sdk/client/index.js';
import { StdioClientTransport } from '@modelcontextprotocol/sdk/client/stdio.js';
const DEFAULT_CONFIG = {
model: 'gpt-4o',
maxTokens: 4096,
maxIterations: 15,
temperature: 0.1,
retries: 3,
retryDelay: 1000, // ms
budgetUSD: 0.50, // Max cost per conversation
timeoutMs: 120_000, // 2 minute timeout per conversation
};
// Token cost estimates (USD per 1M tokens, approximate)
const MODEL_COSTS = {
'gpt-4o': { input: 2.50, output: 10.00 },
'gpt-4o-mini': { input: 0.15, output: 0.60 },
'o3': { input: 15.00, output: 60.00 },
'o3-mini': { input: 1.10, output: 4.40 },
};
export class McpOpenAIClient {
constructor(mcpServerConfig, options = {}) {
this.config = { ...DEFAULT_CONFIG, ...options };
this.openai = new OpenAI({ apiKey: options.apiKey || process.env.OPENAI_API_KEY });
this.mcpServerConfig = mcpServerConfig;
this.mcpClient = null;
this.tools = [];
this.totalCostUSD = 0;
}
async connect() {
this.mcpClient = new Client(
{ name: 'production-host', version: '1.0.0' },
{ capabilities: {} }
);
const transport = new StdioClientTransport(this.mcpServerConfig);
await this.mcpClient.connect(transport);
const { tools } = await this.mcpClient.listTools();
this.tools = tools.map(t => ({
type: 'function',
function: { name: t.name, description: t.description, parameters: t.inputSchema },
}));
console.error(`[mcp] Connected - ${this.tools.length} tools available`);
}
async disconnect() {
await this.mcpClient?.close();
}
estimateCostUSD(inputTokens, outputTokens, model) {
const costs = MODEL_COSTS[model] || MODEL_COSTS['gpt-4o'];
return (inputTokens / 1_000_000) * costs.input + (outputTokens / 1_000_000) * costs.output;
}
async executeWithRetry(fn, maxRetries = this.config.retries) {
let lastError;
for (let attempt = 1; attempt <= maxRetries; attempt++) {
try {
return await fn();
} catch (err) {
lastError = err;
const isRetryable = err.status === 429 || err.status === 500 || err.status === 503;
if (!isRetryable || attempt === maxRetries) throw err;
const delay = this.config.retryDelay * Math.pow(2, attempt - 1); // Exponential backoff
console.error(`[openai] Attempt ${attempt} failed: ${err.message}. Retrying in ${delay}ms`);
await new Promise(r => setTimeout(r, delay));
}
}
throw lastError;
}
async run(userMessage, systemPrompt = null) {
const startTime = Date.now();
const messages = [];
if (systemPrompt) messages.push({ role: 'system', content: systemPrompt });
messages.push({ role: 'user', content: userMessage });
let iteration = 0;
let totalInputTokens = 0;
let totalOutputTokens = 0;
while (true) {
if (++iteration > this.config.maxIterations) {
throw new Error(`Exceeded max iterations (${this.config.maxIterations})`);
}
if (Date.now() - startTime > this.config.timeoutMs) {
throw new Error(`Conversation timeout after ${this.config.timeoutMs}ms`);
}
if (this.totalCostUSD > this.config.budgetUSD) {
throw new Error(`Budget exceeded: $${this.totalCostUSD.toFixed(4)} > $${this.config.budgetUSD}`);
}
const response = await this.executeWithRetry(() =>
this.openai.chat.completions.create({
model: this.config.model,
messages,
tools: this.tools.length > 0 ? this.tools : undefined,
max_tokens: this.config.maxTokens,
temperature: this.config.temperature,
})
);
const usage = response.usage;
totalInputTokens += usage?.prompt_tokens || 0;
totalOutputTokens += usage?.completion_tokens || 0;
const turnCost = this.estimateCostUSD(
usage?.prompt_tokens || 0,
usage?.completion_tokens || 0,
this.config.model
);
this.totalCostUSD += turnCost;
const choice = response.choices[0];
const message = choice.message;
messages.push(message);
if (choice.finish_reason !== 'tool_calls') {
const elapsedMs = Date.now() - startTime;
console.error(`[stats] iterations=${iteration} tokens=${totalInputTokens}+${totalOutputTokens} cost=$${this.totalCostUSD.toFixed(4)} elapsed=${elapsedMs}ms`);
return {
content: message.content,
iterations: iteration,
totalCostUSD: this.totalCostUSD,
tokens: { input: totalInputTokens, output: totalOutputTokens },
elapsedMs,
};
}
// Execute tool calls
const toolResults = await Promise.all(
message.tool_calls.map(async (tc) => {
let args;
try {
args = JSON.parse(tc.function.arguments);
} catch {
return { role: 'tool', tool_call_id: tc.id, content: 'Error: Invalid tool arguments JSON' };
}
try {
const result = await this.mcpClient.callTool({ name: tc.function.name, arguments: args });
const text = result.content.filter(c => c.type === 'text').map(c => c.text).join('\n');
const errorFlag = result.isError ? '[TOOL ERROR] ' : '';
return { role: 'tool', tool_call_id: tc.id, content: errorFlag + text };
} catch (err) {
console.error(`[tool] ${tc.function.name} error: ${err.message}`);
return { role: 'tool', tool_call_id: tc.id, content: `Tool execution failed: ${err.message}` };
}
})
);
messages.push(...toolResults);
}
}
}
Usage Pattern
import { McpOpenAIClient } from './mcp-openai-client.js';
const client = new McpOpenAIClient(
{ command: 'node', args: ['server.js'] },
{
model: 'gpt-4o-mini',
budgetUSD: 0.10,
maxIterations: 8,
timeoutMs: 60_000,
}
);
await client.connect();
const result = await client.run(
'Find me a good Python book for beginners under $40',
'You are a helpful book recommendation assistant.'
);
console.log('Answer:', result.content);
console.log('Cost:', `$${result.totalCostUSD.toFixed(4)}`);
console.log('Iterations:', result.iterations);
await client.disconnect();
“For production deployments, implement exponential backoff for rate limit errors (429). The OpenAI API will return Retry-After headers for rate limits – respect these values.” – OpenAI Documentation, Error Codes
Failure Modes in Production
Case 1: No Budget Control
// A single misbehaving agent with no budget cap can cost hundreds of dollars
// Always set a budgetUSD limit per conversation
// Always set a maxIterations limit per conversation
// Log and alert when conversations exceed 80% of budget
Case 2: Catching All Errors and Retrying Blindly
// Some errors should NOT be retried - e.g. 400 Bad Request (invalid schema)
// 429 = retry (rate limit)
// 500/503 = retry (server error)
// 400 = do NOT retry (your code is wrong)
// 401/403 = do NOT retry (authentication issue)
What to Check Right Now
- Set per-conversation budgets – $0.10 is a reasonable starting point for most workflows. Adjust based on your model and expected tool call count.
- Implement exponential backoff – the pattern shown above (doubling delay on each retry) is the industry standard. Start at 1000ms, cap at 60000ms.
- Log every tool call – production debugging without tool call logs is nearly impossible. Log tool name, arguments, result length, and execution time for every call.
- Monitor iteration counts – if average iterations are above 8, your tool descriptions or system prompt may be unclear. Investigate and improve before scaling.
nJoy 😉