
The previous three Gemini lessons gave you the building blocks: function calling, multimodal inputs, and Vertex AI deployment. This lesson assembles them into a production-grade client library you can drop into any Node.js MCP application. It covers the patterns that only show up after your agent has processed its first ten thousand requests: token budget management, graceful quota handling, automatic retry with jitter, structured response parsing, and observability hooks.
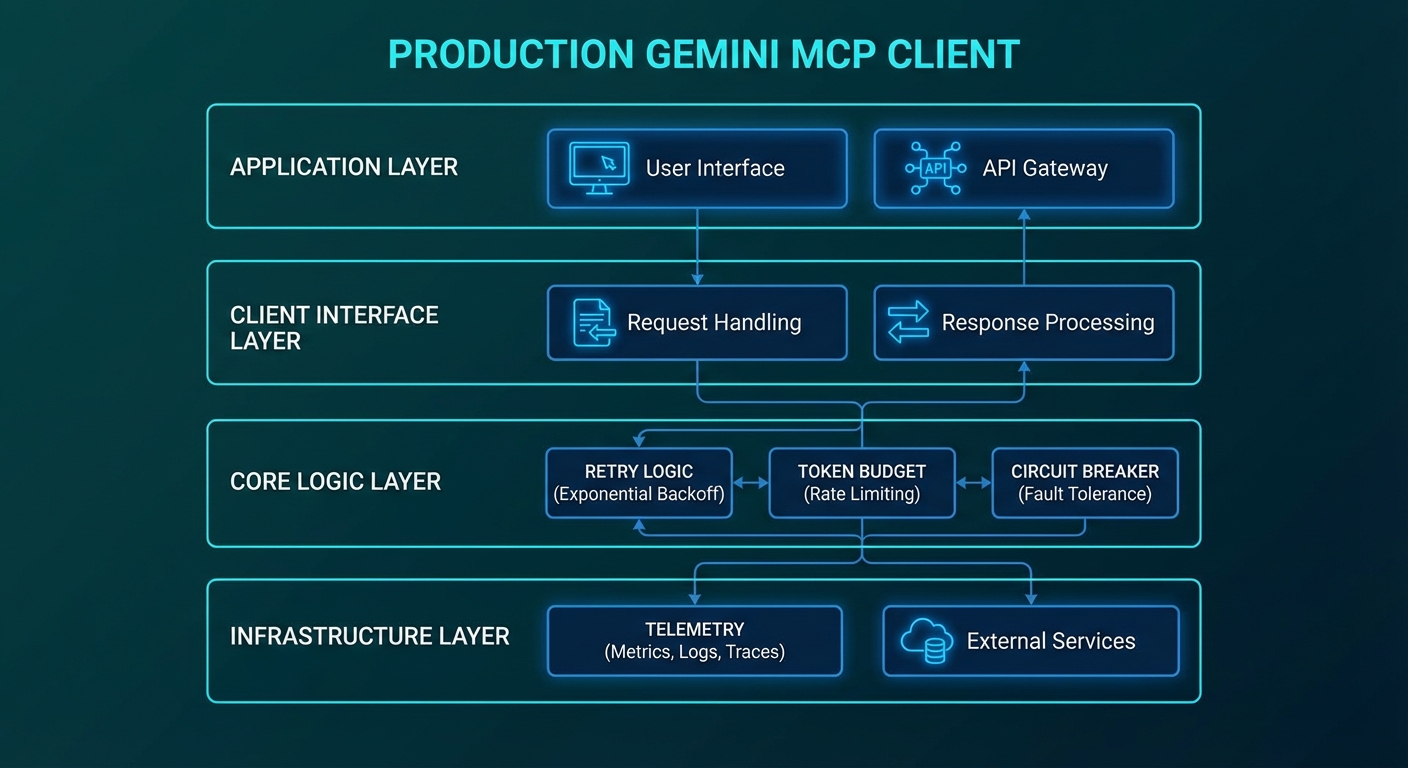
The Base Client Class
// gemini-mcp-client.js
import { GoogleGenerativeAI } from '@google/generative-ai';
import { Client } from '@modelcontextprotocol/sdk/client/index.js';
import { StdioClientTransport } from '@modelcontextprotocol/sdk/client/stdio.js';
export class GeminiMcpClient {
#genai;
#mcp;
#model;
#geminiTools;
#config;
constructor(config = {}) {
this.#config = {
model: config.model ?? 'gemini-2.0-flash',
maxTokens: config.maxTokens ?? 8192,
maxTurns: config.maxTurns ?? 10,
maxRetries: config.maxRetries ?? 3,
tokenBudget: config.tokenBudget ?? 100_000,
onTokenUsage: config.onTokenUsage ?? null,
onToolCall: config.onToolCall ?? null,
...config,
};
this.#genai = new GoogleGenerativeAI(process.env.GEMINI_API_KEY);
this.#mcp = new Client({ name: 'gemini-prod-host', version: '1.0.0' });
}
async connect(serverCommand, serverArgs = []) {
const transport = new StdioClientTransport({ command: serverCommand, args: serverArgs });
await this.#mcp.connect(transport);
const { tools } = await this.#mcp.listTools();
this.#geminiTools = [{
functionDeclarations: tools.map(t => ({
name: t.name,
description: t.description,
parameters: t.inputSchema,
})),
}];
this.#model = this.#genai.getGenerativeModel({
model: this.#config.model,
tools: this.#geminiTools,
generationConfig: { maxOutputTokens: this.#config.maxTokens },
});
}
async run(userMessage) {
const chat = this.#model.startChat();
return this.#runLoop(chat, userMessage);
}
async close() {
await this.#mcp.close();
}
}
Wrapping the Gemini SDK and MCP client into a single class gives you a single place to enforce all production concerns: retries, budgets, timeouts, and telemetry. Without this, those concerns leak across your entire codebase and become impossible to test or change consistently.
Retry Logic with Exponential Backoff and Jitter
// Inside GeminiMcpClient class
async #sendWithRetry(chat, content) {
const { maxRetries } = this.#config;
for (let attempt = 1; attempt <= maxRetries; attempt++) {
try {
return await chat.sendMessage(content);
} catch (err) {
const isQuota = err.status === 429 || err.message?.includes('RESOURCE_EXHAUSTED');
const isServer = err.status >= 500;
if ((!isQuota && !isServer) || attempt === maxRetries) throw err;
const base = isQuota ? 5000 : 1000;
const jitter = Math.random() * 1000;
const delay = Math.min(base * Math.pow(2, attempt - 1) + jitter, 60_000);
console.error(`[gemini] Attempt ${attempt} failed (${err.status ?? err.message}), retrying in ${Math.round(delay)}ms`);
await new Promise(r => setTimeout(r, delay));
}
}
}
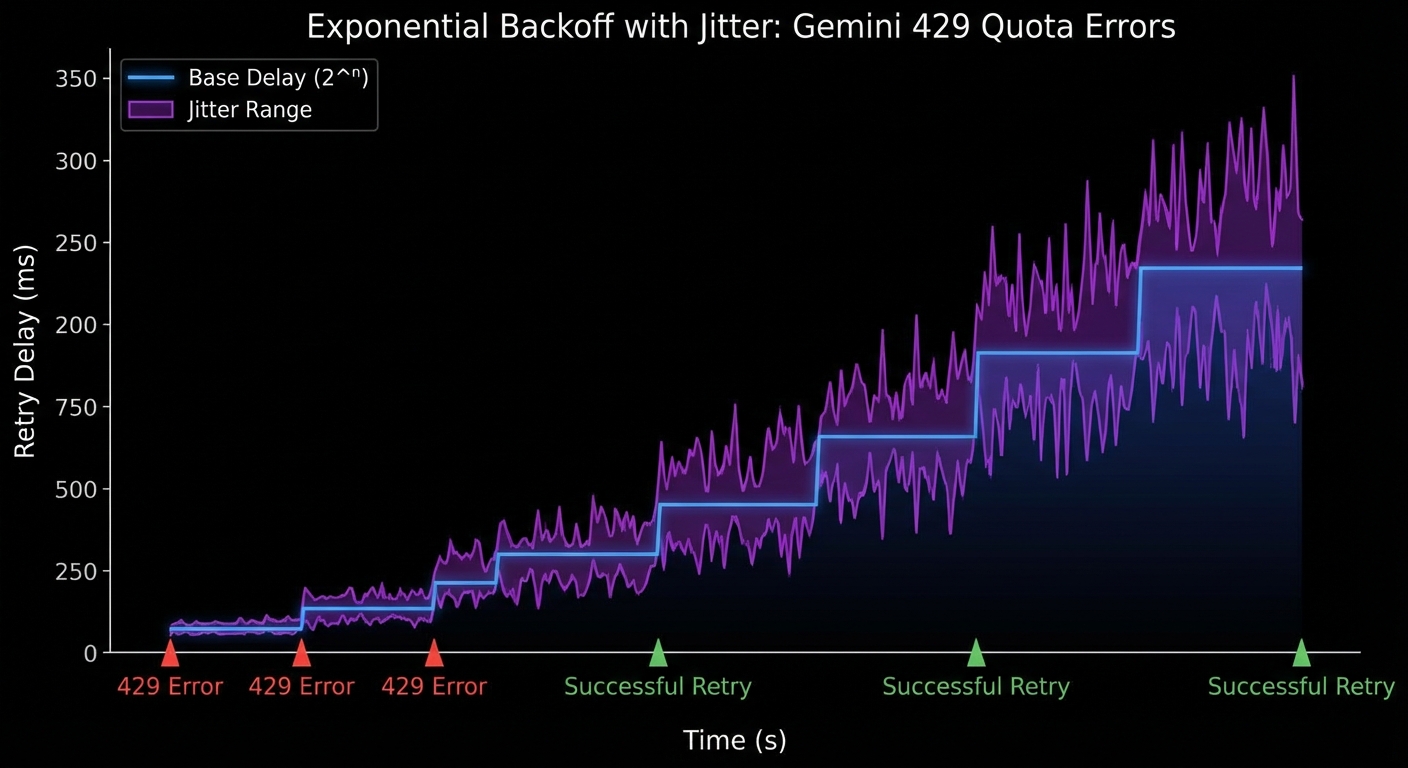
Retry logic is where most production Gemini integrations first break. Without jitter, multiple agent instances hitting quota limits at the same time will retry in lockstep, creating a thundering herd that keeps triggering 429 errors. The randomized delay breaks this cycle.
Token Budget Enforcement
#totalTokensUsed = 0;
#checkBudget(usage) {
if (!usage) return;
const total = usage.totalTokenCount ?? 0;
this.#totalTokensUsed += total;
if (this.#config.onTokenUsage) {
this.#config.onTokenUsage({ total, cumulative: this.#totalTokensUsed });
}
if (this.#totalTokensUsed > this.#config.tokenBudget) {
throw new Error(`Token budget exceeded: ${this.#totalTokensUsed} > ${this.#config.tokenBudget}`);
}
}
Token budgets prevent a common production failure: an agent enters a verbose loop, generates thousands of tokens per turn, and blows through your daily budget in minutes. Setting a per-request ceiling catches this early, before a single runaway conversation drains your account.
The Full Run Loop
async #runLoop(chat, userMessage) {
let response = await this.#sendWithRetry(chat, userMessage);
this.#checkBudget(response.response.usageMetadata);
let candidate = response.response.candidates[0];
let turns = 0;
while (candidate.content.parts.some(p => p.functionCall)) {
if (++turns > this.#config.maxTurns) {
throw new Error(`Max turns exceeded (${this.#config.maxTurns})`);
}
const calls = candidate.content.parts.filter(p => p.functionCall);
const results = await Promise.all(calls.map(part => this.#executeToolCall(part.functionCall)));
response = await this.#sendWithRetry(chat, results);
this.#checkBudget(response.response.usageMetadata);
candidate = response.response.candidates[0];
}
if (candidate.finishReason === 'SAFETY') {
throw new Error('Response blocked by safety filters');
}
return candidate.content.parts.filter(p => p.text).map(p => p.text).join('');
}
async #executeToolCall(fc) {
const start = Date.now();
if (this.#config.onToolCall) {
this.#config.onToolCall({ name: fc.name, args: fc.args, phase: 'start' });
}
try {
const result = await this.#mcp.callTool({ name: fc.name, arguments: fc.args });
const text = result.content.filter(c => c.type === 'text').map(c => c.text).join('\n');
if (this.#config.onToolCall) {
this.#config.onToolCall({ name: fc.name, durationMs: Date.now() - start, phase: 'done' });
}
return { functionResponse: { name: fc.name, response: { result: text } } };
} catch (err) {
if (this.#config.onToolCall) {
this.#config.onToolCall({ name: fc.name, error: err.message, phase: 'error' });
}
return { functionResponse: { name: fc.name, response: { error: err.message } } };
}
}
Using the Production Client
import { GeminiMcpClient } from './gemini-mcp-client.js';
const client = new GeminiMcpClient({
model: 'gemini-2.0-flash',
tokenBudget: 50_000,
maxTurns: 8,
onTokenUsage: ({ total, cumulative }) => {
console.error(`[tokens] +${total} total=${cumulative}`);
},
onToolCall: ({ name, durationMs, phase, error }) => {
if (phase === 'done') console.error(`[tool:${name}] ${durationMs}ms`);
if (phase === 'error') console.error(`[tool:${name}] ERROR: ${error}`);
},
});
await client.connect('node', ['./servers/analytics-server.js']);
const answer = await client.run('What were the top 5 products by revenue last month?');
console.log(answer);
await client.close();
The callback hooks (onTokenUsage, onToolCall) are the foundation of your observability stack. In production, you would pipe these events to a metrics service like Datadog or Cloud Monitoring rather than console.error, giving you dashboards for tool latency, token burn rate, and error frequency.
Streaming Responses for Long Outputs
// Add streaming support to the client
async runStream(userMessage, onChunk) {
const chat = this.#model.startChat();
const stream = await chat.sendMessageStream(userMessage);
for await (const chunk of stream.stream) {
const text = chunk.candidates?.[0]?.content?.parts
?.filter(p => p.text)
?.map(p => p.text)
?.join('') ?? '';
if (text && onChunk) onChunk(text);
}
const final = await stream.response;
this.#checkBudget(final.usageMetadata);
return final.candidates[0].content.parts.filter(p => p.text).map(p => p.text).join('');
}
Monitoring Quota Usage
// Track requests-per-minute to avoid hitting quota limits proactively
class RateLimiter {
#requests = [];
#windowMs;
#maxPerWindow;
constructor(maxPerMinute = 60) {
this.#windowMs = 60_000;
this.#maxPerWindow = maxPerMinute;
}
async throttle() {
const now = Date.now();
this.#requests = this.#requests.filter(t => t > now - this.#windowMs);
if (this.#requests.length >= this.#maxPerWindow) {
const oldest = this.#requests[0];
const wait = this.#windowMs - (now - oldest) + 100;
await new Promise(r => setTimeout(r, wait));
}
this.#requests.push(Date.now());
}
}
const limiter = new RateLimiter(55); // 55 RPM leaves headroom
await limiter.throttle();
const answer = await client.run(userMessage);
Gemini vs OpenAI vs Claude: Production Comparison
| Aspect | Gemini 2.0 Flash | GPT-4o | Claude 3.5 Sonnet |
|---|---|---|---|
| Parallel tool calls | Yes, aggressive | Yes, optional | Limited (beta) |
| Context window | 1M tokens (Flash/Pro) | 128K tokens | 200K tokens |
| Multimodal in same call | Yes (text, image, PDF, audio) | Yes (text, image) | Yes (text, image) |
| Prompt caching | Context caching (Vertex) | Automatic (>1K tokens) | Explicit cache_control |
| Schema conversion from MCP | Pass through (JSON Schema) | Wrap in function object | Pass through (JSON Schema) |
| Stateful session object | Chat object | Manual messages array or Responses API | Manual messages array |
This comparison is a snapshot in time. Provider capabilities and pricing shift quarterly. The production-safe approach is to log your actual usage data – tokens, latency, error rates, cost per task type – and revisit your model choices every few months based on real numbers rather than marketing materials.
Failure Modes to Harden Against
- RESOURCE_EXHAUSTED (429): Use a 5-second base delay with jitter. Gemini’s quota windows are per minute – log RPM metrics to catch spikes before they become errors.
- Infinite tool loops: Gemini can get into cycles where it calls the same tool repeatedly with slightly different args. The
maxTurnsguard is essential. Log the tool name + args on each call to detect cycles early. - Large context accumulation: Gemini’s Chat session adds every turn to history. For multi-hour agent sessions, this can balloon token costs. Implement a sliding window or summarization strategy at 50K tokens.
- Safety filter false positives: Check
finishReason === 'SAFETY'and handle it distinctly from other errors – do not silently return an empty string to the user.
What to Build Next
- Extract
GeminiMcpClientinto a reusable npm package with a clean API and write anode:testsuite against it using a mock MCP server. - Deploy it to Cloud Run with Vertex AI credentials, Gemini 2.0 Flash, and a Cloud Monitoring dashboard tracking token usage, tool call latency, and error rates.
nJoy 😉