
Claude 3.7 Sonnet introduced extended thinking – a mode where the model spends additional compute on internal reasoning before producing its response. When combined with MCP tools, extended thinking transforms how the model approaches complex multi-step tasks: instead of immediately deciding to call a tool, Claude reasons through what it knows, what it needs, which tools would help, and what order to call them in. The result is dramatically fewer redundant tool calls and significantly better decisions on ambiguous tasks.
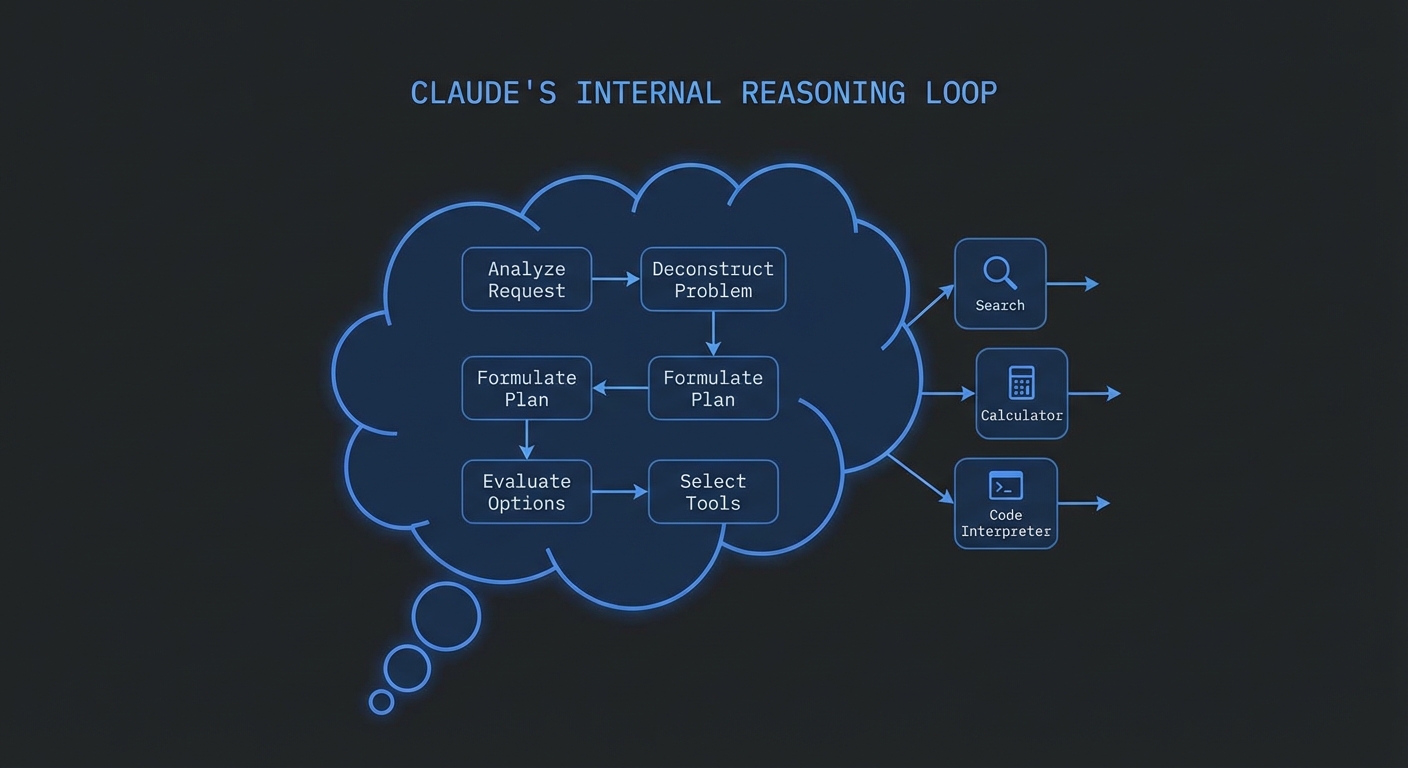
Enabling Extended Thinking
Extended thinking is enabled by adding the thinking block to the API request. You control the “budget” – the maximum number of tokens Claude can use for internal reasoning. A higher budget allows deeper reasoning but adds latency and cost.
import Anthropic from '@anthropic-ai/sdk';
import { Client } from '@modelcontextprotocol/sdk/client/index.js';
import { StdioClientTransport } from '@modelcontextprotocol/sdk/client/stdio.js';
const anthropic = new Anthropic({ apiKey: process.env.ANTHROPIC_API_KEY });
const mcpClient = new Client({ name: 'thinking-host', version: '1.0.0' }, { capabilities: {} });
await mcpClient.connect(new StdioClientTransport({ command: 'node', args: ['server.js'] }));
const { tools: mcpTools } = await mcpClient.listTools();
const claudeTools = mcpTools.map(t => ({ name: t.name, description: t.description, input_schema: t.inputSchema }));
async function runWithExtendedThinking(userMessage, thinkingBudget = 8000) {
const messages = [{ role: 'user', content: userMessage }];
while (true) {
const response = await anthropic.messages.create({
model: 'claude-3-7-sonnet-20250219',
max_tokens: 16000, // Must be > thinking budget
thinking: {
type: 'enabled',
budget_tokens: thinkingBudget, // Min: 1024, no hard max
},
tools: claudeTools,
messages,
});
// Response may contain thinking blocks - they appear before text/tool_use
const thinkingBlocks = response.content.filter(b => b.type === 'thinking');
const textBlocks = response.content.filter(b => b.type === 'text');
const toolUseBlocks = response.content.filter(b => b.type === 'tool_use');
if (process.env.SHOW_THINKING) {
for (const tb of thinkingBlocks) {
console.error('\n[thinking]', tb.thinking.slice(0, 500) + '...');
}
}
messages.push({ role: 'assistant', content: response.content });
if (response.stop_reason === 'tool_use') {
const toolResults = await Promise.all(
toolUseBlocks.map(async (toolUse) => {
const result = await mcpClient.callTool({
name: toolUse.name,
arguments: toolUse.input,
});
return { type: 'tool_result', tool_use_id: toolUse.id, content: result.content };
})
);
messages.push({ role: 'user', content: toolResults });
} else {
return textBlocks.map(b => b.text).join('');
}
}
}
// Complex task: extended thinking shines here
const result = await runWithExtendedThinking(
`I need to buy a laptop for machine learning research.
My budget is $2000. I prefer AMD GPUs but would consider NVIDIA.
It must have at least 32GB RAM expandable to 64GB,
and I work across Windows and Linux so driver support matters.
Research and recommend the top 3 options.`,
12000 // Higher budget for complex task
);
console.log(result);
await mcpClient.close();
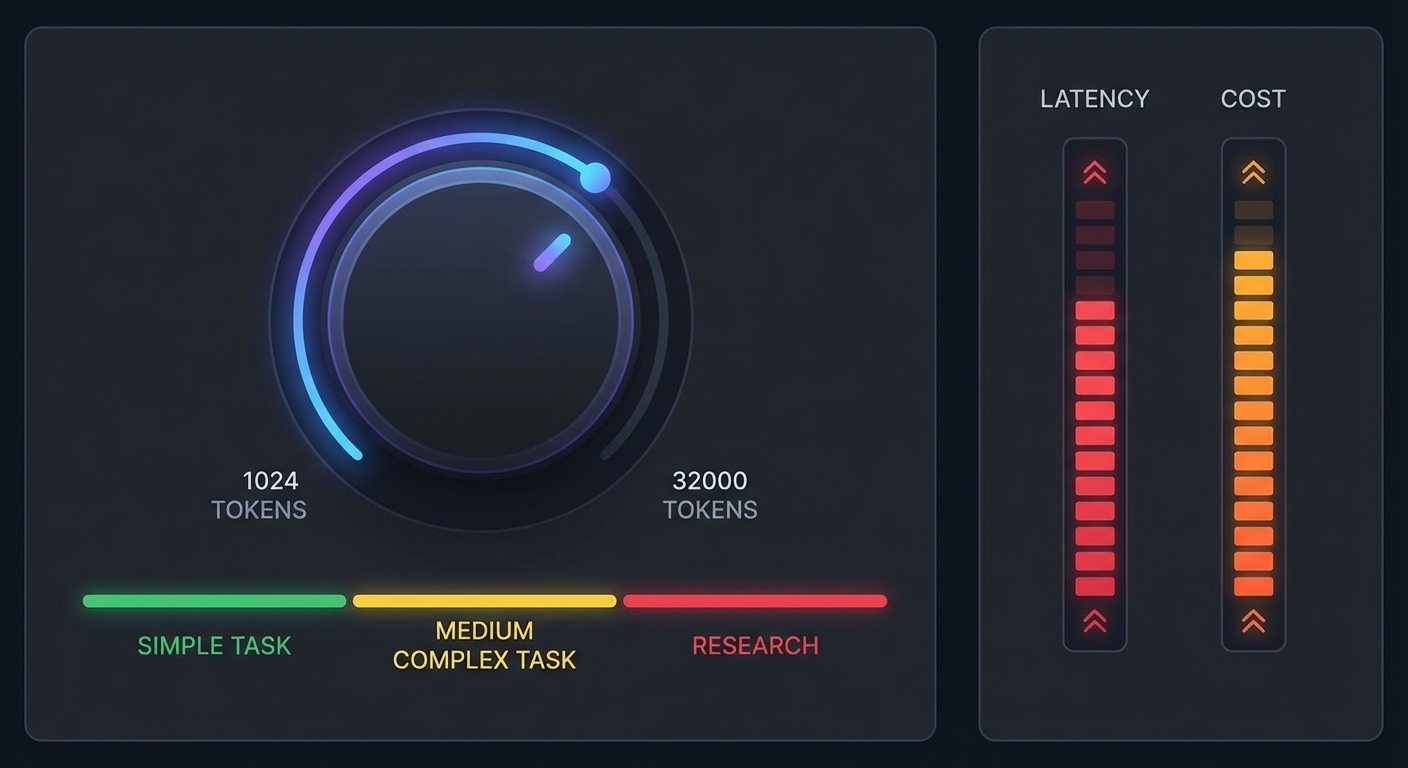
When to Use Extended Thinking with MCP
Extended thinking is not free – it adds significant latency (often 10-30 seconds for high budgets) and substantial token cost. Use it selectively:
- Use it for: complex research requiring 5+ tool calls, tasks requiring careful tradeoff analysis, situations where tool call order significantly affects outcome quality
- Skip it for: simple lookups, single-tool tasks, time-sensitive queries, high-volume low-latency applications
// Adaptive thinking budget based on task complexity
function getThinkingBudget(task) {
const wordCount = task.split(/\s+/).length;
const hasComparisons = /compare|vs|versus|between|best|recommend/.test(task.toLowerCase());
const hasMultipleRequirements = task.split(/and|also|additionally|plus/).length > 2;
if (hasComparisons && hasMultipleRequirements) return 10000;
if (hasComparisons || hasMultipleRequirements) return 5000;
if (wordCount > 50) return 3000;
return 0; // No thinking for simple tasks
}
const budget = getThinkingBudget(userInput);
if (budget > 0) {
return runWithExtendedThinking(userInput, budget);
} else {
return runWithClaude(userInput); // Standard tool calling
}
“Extended thinking causes Claude to reason more thoroughly about tasks before responding, which can substantially improve performance on complex tasks. Thinking tokens are not cached and must be included in the context window when continuing a conversation.” – Anthropic Documentation, Extended Thinking
Failure Modes with Extended Thinking
Case 1: Setting max_tokens Less Than Thinking Budget
// WRONG: max_tokens must exceed budget_tokens
const response = await anthropic.messages.create({
max_tokens: 4096,
thinking: { type: 'enabled', budget_tokens: 8000 }, // 8000 > 4096 - API error!
});
// CORRECT: max_tokens must be greater than budget_tokens
const response = await anthropic.messages.create({
max_tokens: 16000,
thinking: { type: 'enabled', budget_tokens: 8000 }, // Valid: 16000 > 8000
});
Case 2: Not Passing Thinking Blocks Back in Continuation
// When continuing a conversation with extended thinking enabled,
// thinking blocks from previous turns MUST be included in the messages array.
// The SDK handles this automatically if you push the full response.content.
messages.push({ role: 'assistant', content: response.content }); // Include ALL blocks including thinking
What to Check Right Now
- Test with SHOW_THINKING=1 – run your agent with thinking visible. Reading the thinking output reveals what the model understood about the task and why it chose each tool.
- Measure latency impact – log response time with and without extended thinking on the same tasks. Quantify the tradeoff for your use case before deploying at scale.
- Start with budget 4000-8000 – this range gives substantially improved reasoning for most tasks without the extreme latency of budgets above 15,000.
- Use claude-3-5-sonnet for anything where speed > accuracy – 3.5 Sonnet without thinking is typically faster and cheaper for tasks where the tradeoff makes sense.
nJoy 😉