
Every team building MCP applications eventually faces the same question: which model should we use for this task? The wrong answer is “the most capable one” — that is how teams burn through their budget on GPT-4o for queries that GPT-4o mini could answer just as well. This lesson builds a systematic decision framework: a set of questions and criteria that map task characteristics to optimal model choices, plus the infrastructure to implement dynamic routing in production.
The Five Dimensions of Model Selection
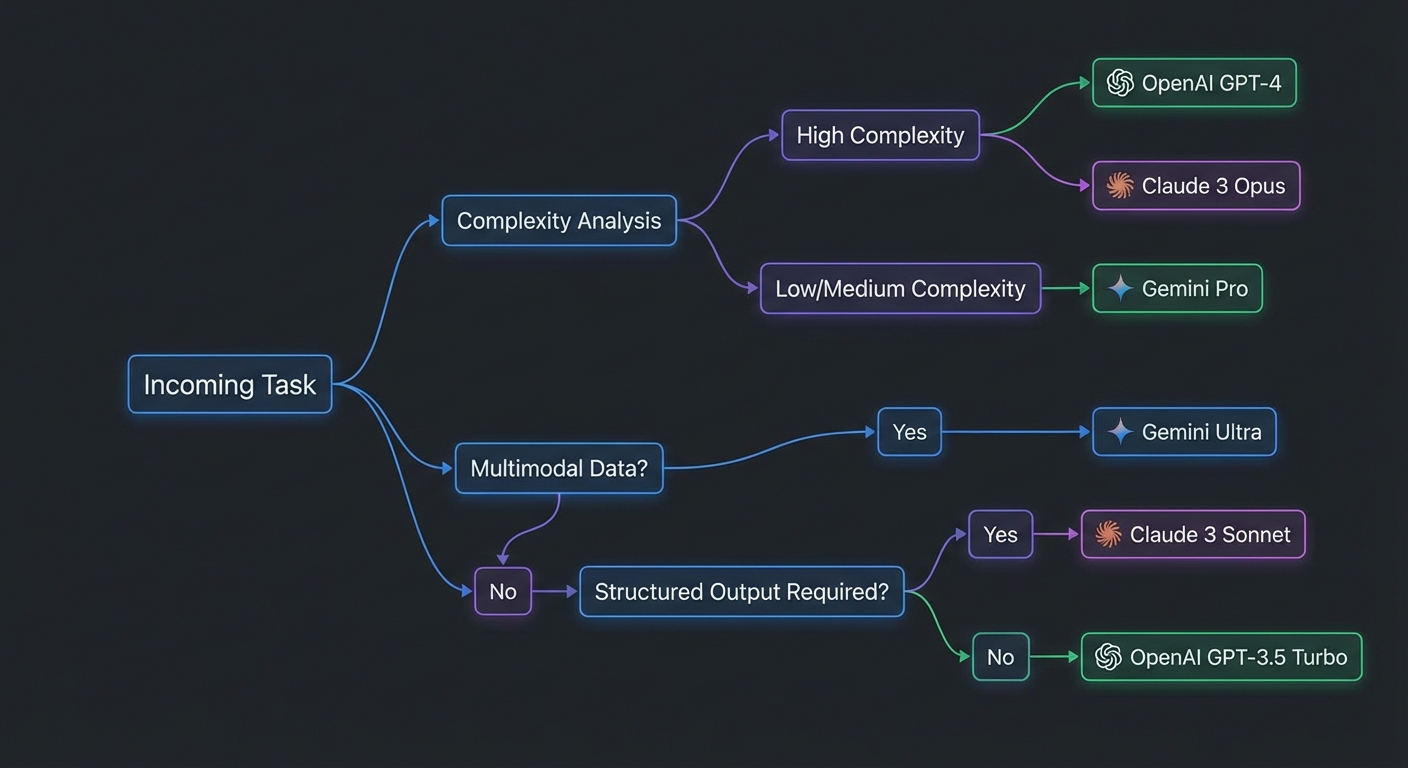
Five dimensions determine the optimal model choice for an MCP task:
- Reasoning depth: Is the task multi-step, requires planning, or involves complex logic? Use Claude 3.7 or o3. Is it a simple lookup or classification? Use a mini/flash model.
- Context length: Does the task involve large documents, entire codebases, or long conversation history? Gemini 2.5 Pro (1M tokens) or Claude 3.7 (200K). For standard tasks, 128K is sufficient.
- Input modality: Does the task involve images, PDFs, or audio? Use Gemini (strongest multimodal support). Text only – any provider works.
- Output format: Does the task require guaranteed JSON schema output? Use OpenAI with
zodResponseFormat. Free-form prose or code? Any provider. - Volume and cost: Is this a high-throughput task called thousands of times per hour? Use Gemini 2.0 Flash ($0.075/1M input) or GPT-4o mini ($0.15/1M input) before considering more expensive models.
These five dimensions are not equally weighted for every application. A customer-facing chatbot cares most about latency and cost. An internal compliance tool cares most about reasoning depth and output format. Before writing routing rules, rank these dimensions for your specific use case.
The Decision Framework
// Task routing decision table
// Use this as a starting point for your routing config
const ROUTING_RULES = [
// Rule order matters - first match wins
{
name: 'multimodal',
condition: (task) => task.hasImages || task.hasPDF || task.hasAudio,
provider: 'gemini', model: 'gemini-2.0-flash',
reason: 'Native multimodal support, cheapest multimodal option',
},
{
name: 'large-context',
condition: (task) => task.estimatedInputTokens > 100_000,
provider: 'gemini', model: 'gemini-2.5-pro-preview-03-25',
reason: '1M token context window, best for whole-document/codebase analysis',
},
{
name: 'deep-reasoning',
condition: (task) => task.requiresPlanning || task.complexity === 'high',
provider: 'claude', model: 'claude-3-7-sonnet-20250219',
reason: 'Extended thinking mode, best instruction following',
},
{
name: 'structured-output',
condition: (task) => task.requiresStrictJSON,
provider: 'openai', model: 'gpt-4o',
reason: 'zodResponseFormat guarantees JSON schema adherence',
},
{
name: 'high-volume-simple',
condition: (task) => task.volume > 1000 && task.complexity === 'low',
provider: 'gemini', model: 'gemini-2.0-flash',
reason: 'Cheapest per-token, sufficient for simple tasks at scale',
},
{
name: 'default',
condition: () => true,
provider: 'openai', model: 'gpt-4o-mini',
reason: 'Good balance of capability and cost for general tasks',
},
];
export function selectModel(task) {
const rule = ROUTING_RULES.find(r => r.condition(task));
return { provider: rule.provider, model: rule.model, reason: rule.reason };
}
Rule order is critical in this table: the first matching rule wins. If you put the default rule at the top, every request would route to GPT-4o mini regardless of complexity. When debugging unexpected routing, check rule ordering before anything else.
Estimating Task Complexity
// Simple heuristics for runtime complexity estimation
export function classifyTask(userMessage, context = {}) {
const words = userMessage.split(/\s+/).length;
const hasAnalyze = /analyz|evaluate|compare|assess|plan|strategy/i.test(userMessage);
const hasSimple = /list|find|get|show|what is|how many/i.test(userMessage);
return {
complexity: hasAnalyze ? 'high' : (hasSimple ? 'low' : 'medium'),
estimatedInputTokens: Math.ceil(words * 1.3) + (context.historyTokens ?? 0),
hasImages: context.hasImages ?? false,
hasPDF: context.hasPDF ?? false,
hasAudio: context.hasAudio ?? false,
requiresStrictJSON: context.requiresStrictJSON ?? false,
requiresPlanning: hasAnalyze,
volume: context.requestsPerHour ?? 0,
};
}
These heuristics are a starting point, not a final solution. Keyword matching will misclassify some tasks – a user asking “analyze this simple list” triggers the complexity flag unnecessarily. Over time, replace these rules with a lightweight classifier trained on your actual query logs and quality ratings.
Cascading Fallback Strategy
// Try primary, fall back on quota or severe errors
export async function runWithFallback(task, providers) {
const { provider: primaryKey, model } = selectModel(task);
const fallbackKey = primaryKey === 'gemini' ? 'openai' : 'gemini';
for (const key of [primaryKey, fallbackKey]) {
const provider = providers[key];
if (!provider) continue;
try {
return await provider.run(task.message, task.mcpClient);
} catch (err) {
const isQuota = err.status === 429 || err.message?.includes('RESOURCE_EXHAUSTED');
if (!isQuota) throw err;
console.error(`[router] ${key} quota hit, trying fallback`);
}
}
throw new Error('All providers exhausted');
}
Fallback routing adds resilience but also introduces behavioral inconsistency. If your primary provider is Claude (optimized for reasoning) and your fallback is Gemini (optimized for speed), the quality of responses will shift when fallback activates. Log which provider handled each request so you can detect when fallback is firing too often.
Building a Cost Dashboard
// Track cost per provider, per task type, per hour
class CostTracker {
#records = [];
record({ provider, model, inputTokens, outputTokens, taskType }) {
const costs = {
'gpt-4o': { input: 2.5, output: 10 },
'gpt-4o-mini': { input: 0.15, output: 0.60 },
'claude-3-7-sonnet-20250219': { input: 3.0, output: 15 },
'claude-3-5-haiku-20241022': { input: 0.80, output: 4 },
'gemini-2.0-flash': { input: 0.075, output: 0.30 },
'gemini-2.5-pro-preview-03-25': { input: 1.25, output: 10 },
};
const c = costs[model] ?? { input: 0, output: 0 };
const cost = (inputTokens * c.input + outputTokens * c.output) / 1_000_000;
this.#records.push({ provider, model, taskType, cost, ts: Date.now() });
}
summary() {
return this.#records.reduce((acc, r) => {
const key = `${r.provider}/${r.model}`;
acc[key] = (acc[key] ?? 0) + r.cost;
return acc;
}, {});
}
}
Even a simple cost tracker like this one reveals patterns that are invisible without data. You might discover that 80% of your spend comes from 5% of your queries, or that a particular task type routes to an expensive model when a cheaper one would suffice. Data-driven routing decisions consistently outperform intuition.
Common Routing Mistakes
- Always routing to the most capable model: GPT-4o for every query is 16x more expensive than GPT-4o mini for tasks where both work equally well. Benchmark first, then route based on evidence.
- Not accounting for caching: OpenAI’s automatic caching and Claude’s explicit
cache_controlcan change the effective cost dramatically for repeated queries with the same prefix. Factor this into your cost model. - Routing on task type without measuring quality: A routing decision is only valid if you have measured that the cheaper model produces acceptable results for the task type. Build eval sets per task type and validate routing assumptions.
- Ignoring latency: Cost is not the only dimension. GPT-4o mini has much lower latency than GPT-4o. Gemini 2.0 Flash is faster still. For user-facing real-time features, latency matters as much as cost.
What to Build Next
- Run 20 real queries from your application through the framework above. Log provider, model, task complexity, cost, and a quality score (manual review). Use this data to refine the routing rules.
- Set up a cost alert: if hourly spend exceeds a threshold, log a warning and automatically down-route to cheaper models.
nJoy 😉