
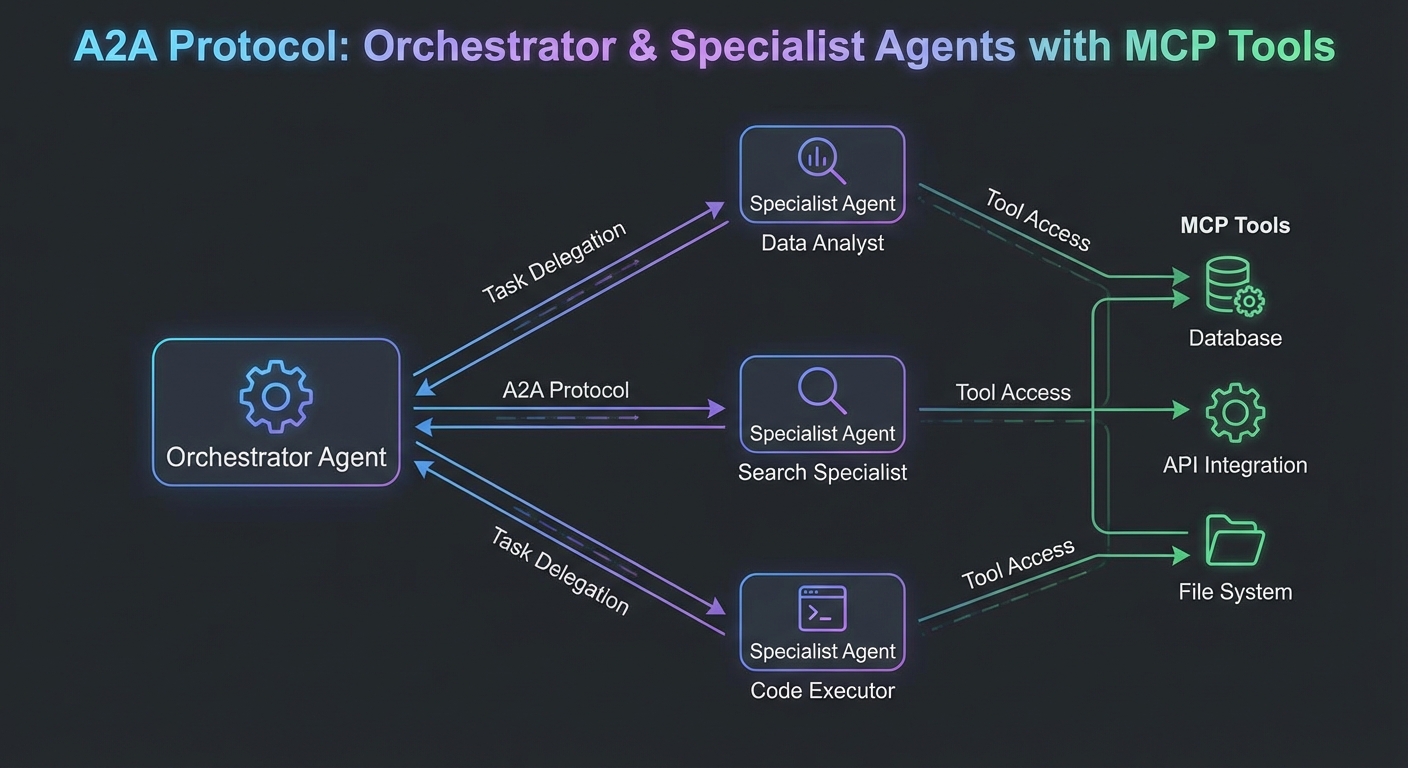
As MCP deployments grow, individual agents become components in larger multi-agent systems. An orchestrator agent decomposes a task; specialist agents execute subtasks; results are combined. The Agent-to-Agent (A2A) protocol, proposed by Google alongside MCP, formalizes how agents delegate work to other agents over HTTP. This lesson covers A2A’s task delegation model, how it complements MCP, and the practical patterns for building multi-agent architectures where each agent exposes both an MCP server interface (for tools) and an A2A interface (for task delegation).
MCP vs A2A: The Complementary Split
| Aspect | MCP | A2A |
|---|---|---|
| Primary purpose | Connect agents to tools, data, and prompts | Delegate entire tasks to other agents |
| Who initiates | LLM host (via client) | Orchestrator agent |
| Response type | Immediate tool result | Async task with streaming updates |
| Capability discovery | tools/list, resources/list, prompts/list | Agent Card (JSON metadata at /.well-known/agent.json) |
| Transport | stdio or Streamable HTTP | HTTP with SSE for streaming |
This split matters because it mirrors how real engineering teams organize: each agent owns its domain tools via MCP, while A2A handles the delegation contract between agents. Confusing the two layers leads to agents that are tightly coupled, hard to test individually, and fragile when one service changes.
The Agent Card
A2A agents publish an Agent Card at /.well-known/agent.json. This is how orchestrators discover what a specialist agent can do:
// agent-card.json - served at GET /.well-known/agent.json
{
"name": "Research Agent",
"description": "Specializes in web research and document analysis",
"url": "https://research-agent.internal",
"version": "1.0.0",
"capabilities": {
"streaming": true,
"pushNotifications": false,
"stateTransitionHistory": true
},
"skills": [
{
"id": "web-research",
"name": "Web Research",
"description": "Search the web and synthesize findings into a report",
"inputModes": ["text"],
"outputModes": ["text"]
},
{
"id": "document-analysis",
"name": "Document Analysis",
"description": "Analyze PDFs, Word documents, and spreadsheets",
"inputModes": ["text", "file"],
"outputModes": ["text"]
}
],
"authentication": {
"schemes": ["bearer"]
}
}
A misconfigured Agent Card is the most common source of silent failures in A2A systems. If the skills array is missing or the descriptions are vague, the orchestrator will either skip the agent entirely or delegate the wrong tasks to it. Treat Agent Cards like API documentation: keep them accurate and version them alongside your code.
A2A Task Lifecycle
// A2A task states: submitted -> working -> completed | failed | canceled
// Orchestrator sends a task, specialist streams updates back
// Orchestrator: send a task to the research agent
async function delegateToResearchAgent(topic) {
const taskId = crypto.randomUUID();
const response = await fetch('https://research-agent.internal/tasks/send', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': `Bearer ${await tokenManager.getToken()}`,
},
body: JSON.stringify({
id: taskId,
message: {
role: 'user',
parts: [{ type: 'text', text: `Research the following topic: ${topic}` }],
},
}),
});
// Stream task updates via SSE
const stream = response.body.pipeThrough(new TextDecoderStream());
let finalResult = null;
for await (const chunk of stream) {
const lines = chunk.split('\n').filter(l => l.startsWith('data:'));
for (const line of lines) {
const event = JSON.parse(line.slice(5));
if (event.result?.status?.state === 'completed') {
finalResult = event.result;
}
}
}
return finalResult?.artifacts?.[0]?.parts?.[0]?.text;
}
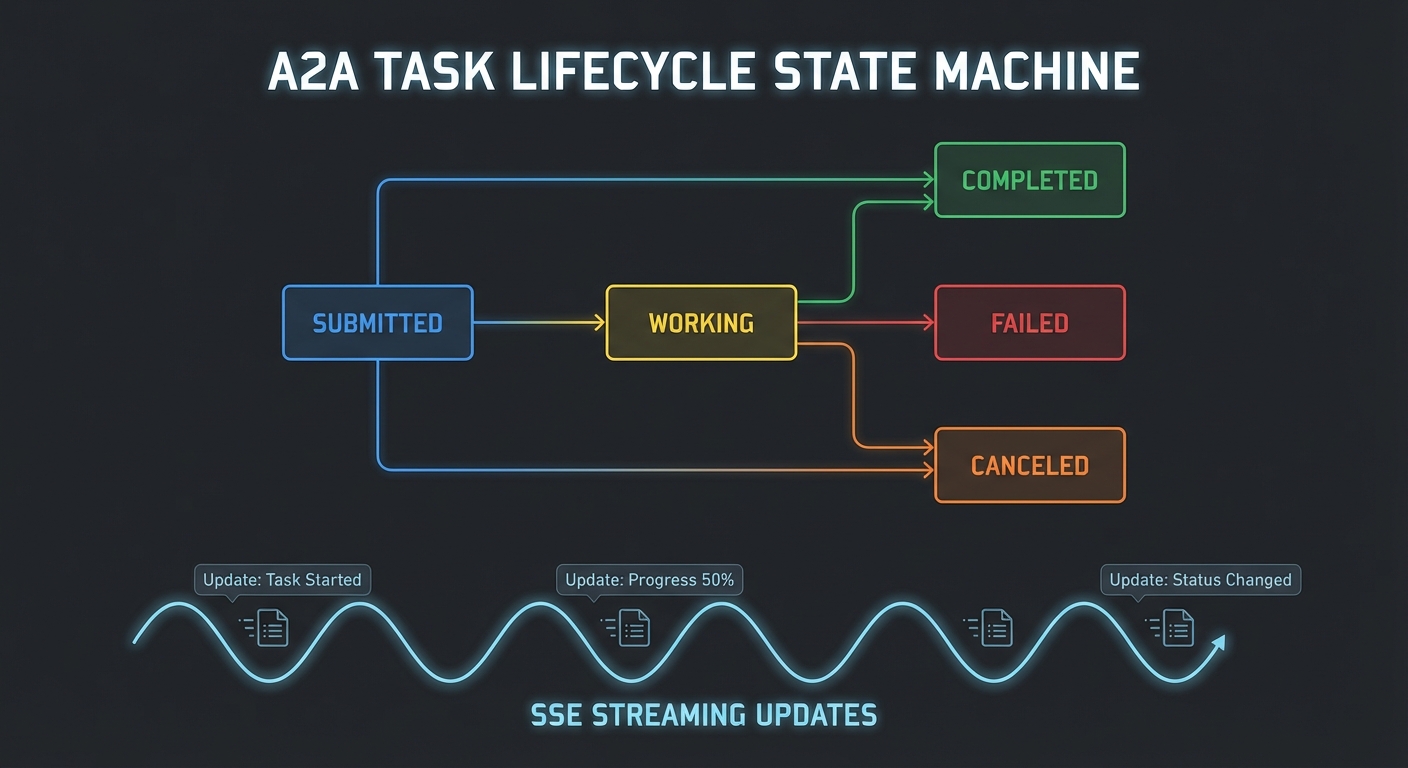
With the task lifecycle understood, the next step is seeing how a single agent can wear both hats: exposing MCP tools for its own LLM to use, and exposing an A2A endpoint so orchestrators can delegate tasks to it. This dual-interface pattern is the standard architecture in production multi-agent deployments.
Building an Agent That Uses Both MCP and A2A
// A specialist agent that:
// 1. Exposes MCP tools (for the LLM it runs on)
// 2. Exposes an A2A task endpoint (for orchestrators)
// 3. Uses other MCP servers internally (tools for its own LLM)
import express from 'express';
import { McpServer } from '@modelcontextprotocol/sdk/server/mcp.js';
import { GeminiMcpClient } from './gemini-mcp-client.js';
const app = express();
app.use(express.json());
// Serve the Agent Card
app.get('/.well-known/agent.json', (req, res) => {
res.json(AGENT_CARD);
});
// A2A task endpoint
app.post('/tasks/send', async (req, res) => {
const { id: taskId, message } = req.body;
const userText = message.parts.find(p => p.type === 'text')?.text;
// Set up SSE streaming
res.setHeader('Content-Type', 'text/event-stream');
res.setHeader('Cache-Control', 'no-cache');
const sendEvent = (data) => res.write(`data: ${JSON.stringify(data)}\n\n`);
sendEvent({ id: taskId, result: { status: { state: 'working' } } });
try {
// Use Gemini + MCP to complete the task
const geminiClient = new GeminiMcpClient({ model: 'gemini-2.0-flash' });
await geminiClient.connect('node', ['./tools/search-server.js']);
const result = await geminiClient.run(userText);
sendEvent({
id: taskId,
result: {
status: { state: 'completed' },
artifacts: [{ parts: [{ type: 'text', text: result }] }],
},
});
await geminiClient.close();
} catch (err) {
sendEvent({ id: taskId, result: { status: { state: 'failed', message: err.message } } });
}
res.end();
});
app.listen(3001, () => console.log('Research agent listening on :3001'));
In practice, most production agents start as pure MCP servers, and the A2A endpoint is added later when orchestration needs arise. This incremental approach lets you test each agent in isolation with MCP tools before wiring it into a larger multi-agent graph.
Orchestrator Pattern: Decompose and Delegate
// Top-level orchestrator using OpenAI to decompose tasks
// and A2A to delegate to specialist agents
import OpenAI from 'openai';
const openai = new OpenAI();
async function orchestrate(userRequest) {
// Step 1: Use OpenAI to decompose the task
const decomposition = await openai.chat.completions.create({
model: 'gpt-4o',
messages: [
{ role: 'system', content: 'Decompose the user request into subtasks for specialist agents. Respond with JSON: { subtasks: [{ agent: "research|analysis|writing", task: "..." }] }' },
{ role: 'user', content: userRequest },
],
response_format: { type: 'json_object' },
});
const { subtasks } = JSON.parse(decomposition.choices[0].message.content);
// Step 2: Execute subtasks (sequential or parallel based on dependencies)
const results = await Promise.all(subtasks.map(async (subtask) => {
const agentUrl = AGENT_REGISTRY[subtask.agent];
const result = await delegateTask(agentUrl, subtask.task);
return { agent: subtask.agent, result };
}));
// Step 3: Synthesize results
const synthesis = await openai.chat.completions.create({
model: 'gpt-4o',
messages: [
{ role: 'system', content: 'Synthesize the specialist agent results into a final response.' },
{ role: 'user', content: JSON.stringify(results) },
],
});
return synthesis.choices[0].message.content;
}
The orchestrator pattern is powerful, but parallelizing subtasks with Promise.all can be deceptive. If any specialist agent hangs or returns malformed data, the entire batch stalls or produces corrupted results. Always wrap delegated calls with timeouts and validate each agent’s response before passing it to the synthesis step.
Multi-Agent Failure Modes
- Cascading timeouts: If agent A calls agent B which calls agent C, a single slow agent can cascade. Set aggressive timeouts at each hop and implement circuit breakers.
- Context drift: Each agent runs in its own context. Information from agent A does not automatically appear in agent B’s context. The orchestrator must explicitly pass relevant context between agents.
- Credential propagation: When delegating tasks between agents, the downstream agent should use its own credentials for tool calls, not the upstream agent’s token. Never forward bearer tokens to downstream services.
- Infinite delegation loops: Agent A delegates to B which delegates back to A. Implement a
X-Agent-Traceheader with a list of agents in the call chain and reject circular delegations.
nJoy 😉