Redis is one of those tools you adopt on a Monday and depend on completely by Thursday. It’s fast, it’s simple, and its data structures make your brain feel big. But buried inside Redis is a feature that has been silently causing production incidents for years: multiple logical databases within a single instance. You’ve probably used it. You might be using it right now. And there’s a very good chance it’s going to bite you at the worst possible moment.
What Redis Databases Actually Are
Redis ships with 16 databases numbered 0 through 15. You switch between them using the SELECT command. Each database has its own keyspace, which means keys named user:1 in database 0 are completely separate from user:1 in database 5. On the surface this looks like proper isolation. It is not.
The Redis documentation itself is blunt about this. From the official docs on SELECT:
“Redis databases should not be used as a way to separate different application data. The proper way to do this is to use separate Redis instances.” — Redis documentation, SELECT command
This isn’t buried in a footnote. It’s right there in the command reference. And yet, multiple databases are everywhere in production. Why? Because they’re convenient. Running one Redis process is simpler than running three. And the keyspace separation looks exactly like the isolation you actually need.
# This looks clean and organised
redis-cli SELECT 0 # application sessions
redis-cli SELECT 5 # background pipeline processing
redis-cli SELECT 10 # lightweight caching
# What you think you have: three isolated stores
# What you actually have: three buckets in one leaking tankThe Shared Resource Problem: What Actually Goes Wrong
Every Redis database within a single instance shares the same server process. That means one pool of memory, one CPU thread (Redis is single-threaded for commands), one network socket, one set of configuration limits. When you SELECT a different database number, you’re not switching to a different process. You’re just telling Redis to look in a different keyspace. The underlying machinery is identical.
Kleppmann in Designing Data-Intensive Applications explains why this matters at a systems level: shared resources without isolation boundaries mean a fault in one subsystem propagates to all others. He’s talking about distributed systems broadly, but the principle applies here with brutal precision. Your databases are not subsystems. They are namespaces sharing a single subsystem.
Here is what that looks like in practice.
Case 1: Memory Eviction Wipes Your Cache
You configure a single Redis instance with maxmemory 4gb and maxmemory-policy allkeys-lru. You use database 5 for pipeline job queues and database 10 for caching API responses. Your pipeline goes through a burst period and starts writing thousands of large job payloads into database 5.
# redis.conf
maxmemory 4gb
maxmemory-policy allkeys-lru
# Your pipeline flooding database 5
import redis
r = redis.Redis(db=5)
for job in burst_of_10k_jobs:
r.set(f"job:{job.id}", job.payload, ex=3600) # big payloads
# Meanwhile in your web app...
cache = redis.Redis(db=10)
result = cache.get("api:products:page:1") # returns None — evicted
# Cache miss. Your DB gets hammered.When Redis hits the memory limit it runs LRU eviction across all keys in all databases. It doesn’t know or care that database 10’s cache keys are serving live user traffic. It just evicts whatever is least recently used. Your carefully populated cache gets gutted to make room for the pipeline. Cache hit rate goes from 85% to 12%. Your database gets hammered. Everyone’s pager goes off at 2am.
This is not a hypothetical. It’s a well-documented operational failure mode.
Case 2: FLUSHDB Takes Down More Than You Planned
You’re cleaning up stale test data. You connect to what you think is the test database and run FLUSHDB. Redis flushes database 0. Your sessions are in database 0. Your production users are now all logged out simultaneously.
# Developer runs this thinking they're on the test DB
redis-cli -n 0 FLUSHDB
# But your sessions were also on DB 0
# Every logged-in user just got kicked out
# Support tickets: manyWith separate instances, this failure mode is impossible. You’d have to explicitly connect to the production instance and deliberately flush it. The separate instance is an actual boundary. The database number is just a label.
Case 3: FLUSHALL Is Always a Disaster
Someone runs FLUSHALL to clean up a database. FLUSHALL wipes every database in the instance. It doesn’t ask which one. If all your databases are in one Redis instance, this single command takes out everything: your sessions, your pipeline queues, your caches, your temporary data. Everything. Simultaneously.
# Looks like it's cleaning just one thing
redis-cli FLUSHALL # deletes EVERY database (0 through 15)
# Equivalent damage: one wrong command vaporises
# db 0: sessions → all users logged out
# db 5: pipeline → all queued jobs lost
# db 10: cache → cache cold, DB under full loadCase 4: A Slow Operation Blocks Everything
Redis is single-threaded for command execution. A slow operation in one database blocks commands in all other databases. You’re running a large KEYS * scan in database 5 during maintenance (yes, you know not to do this, but someone does it anyway). It takes 800ms. For 800ms, every GET in database 10 queues up. Your cache layer is unresponsive. Your application timeout counters tick.
# Someone runs this on db 5 "just to debug something"
redis-cli -n 5 KEYS "*pipeline*"
# Returns after 800ms
# During those 800ms, database 10 clients are blocked:
cache.get("user:session:abc123") # waiting... waiting...
# Your app's 500ms timeout fires
# HTTP 504 responses hit your usersWith separate instances, a blocked db 5 instance doesn’t touch db 10’s instance. The processes are independent.
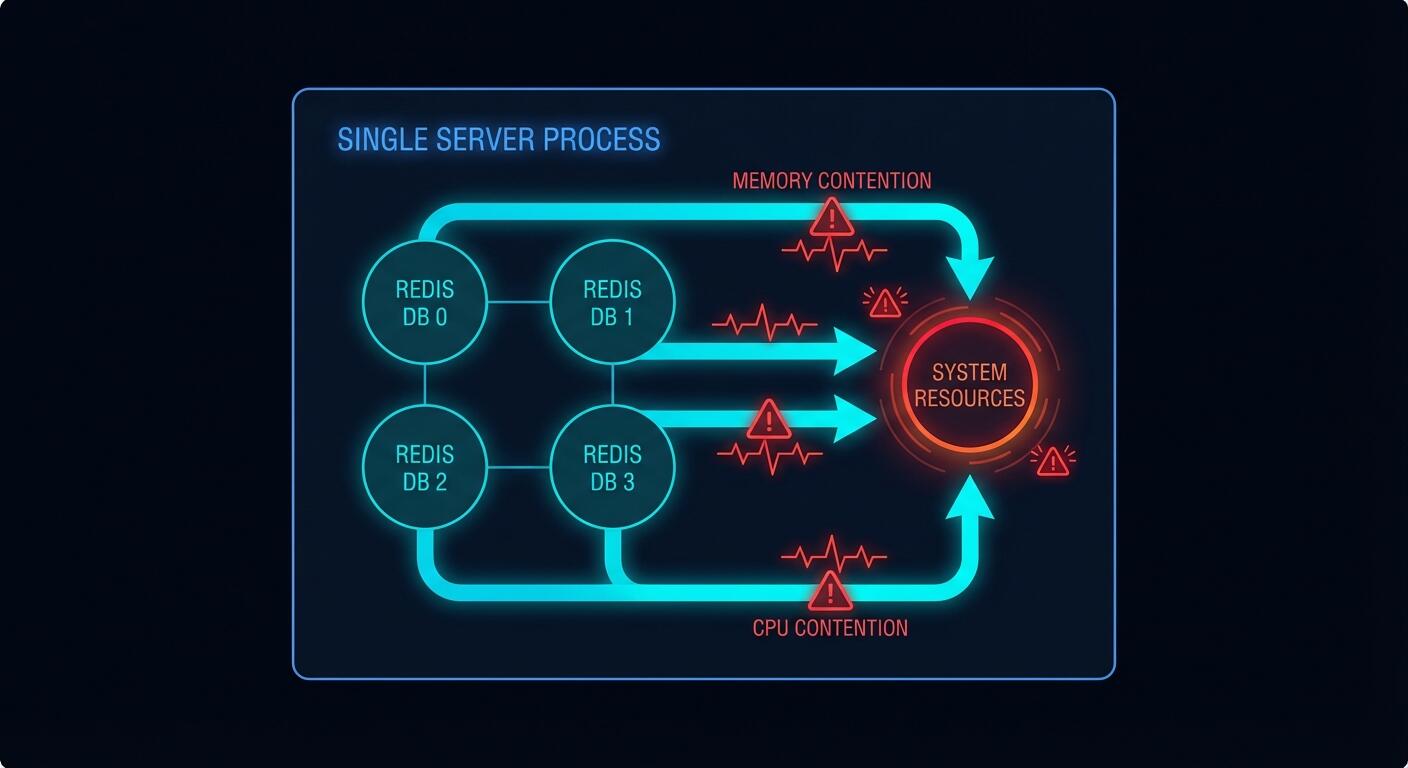
The Redis Cluster Problem: A Hard Wall
Here’s a constraint that isn’t optional or configurable. Redis Cluster, which is the standard approach for horizontal scaling and high availability in production, only supports database 0.
“Redis Cluster supports a single database, and the SELECT command is not allowed.” — Redis Cluster specification
If you’ve built your application around multiple database numbers and you later need to scale horizontally with Redis Cluster, you’re stuck. You have to refactor your data access layer, migrate your keys, and retest everything. The cost of the “convenient” multi-database approach arrives as a large refactoring bill exactly when you can least afford it: when your traffic is growing.
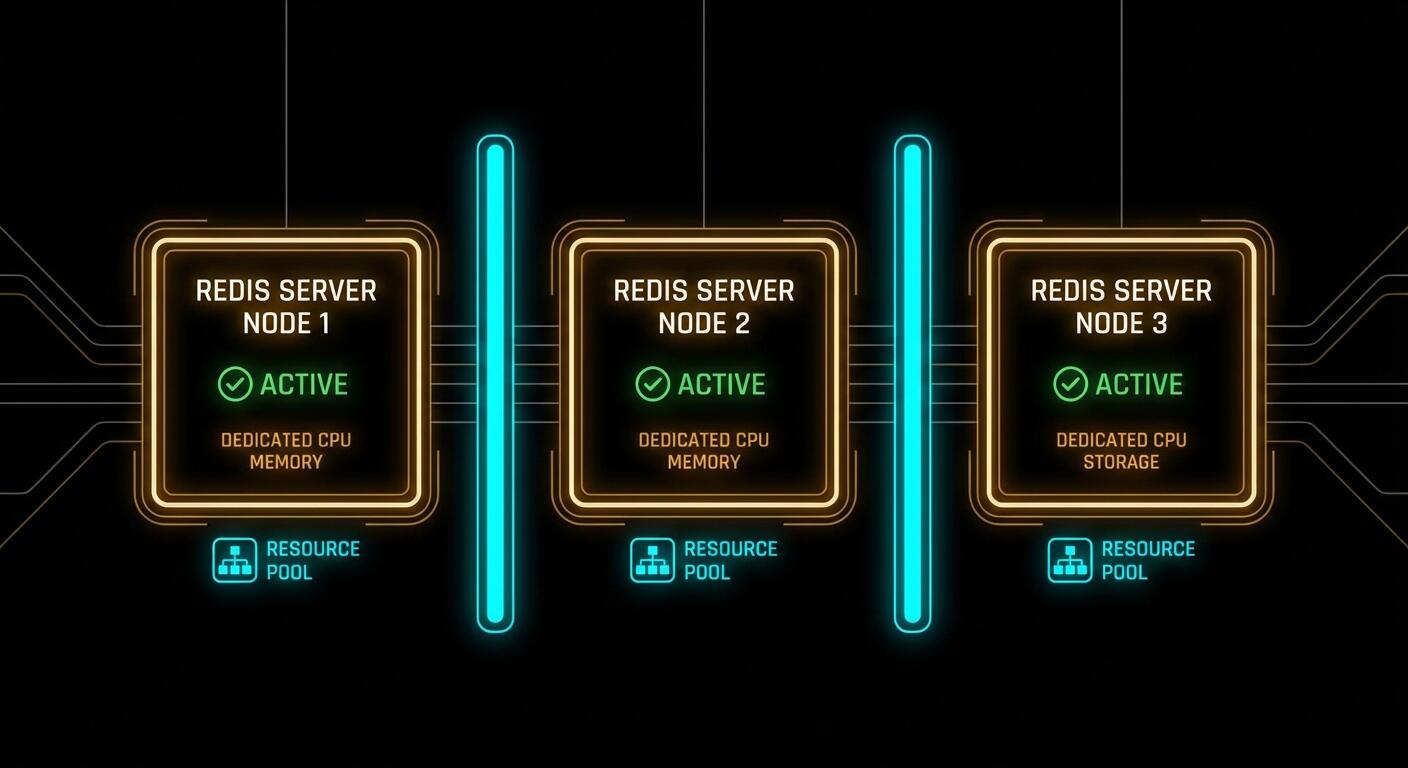
The Proper Pattern: Separate Instances
The correct approach is to run a separate Redis instance for each logical use case. This is not complicated. Redis has a tiny footprint. Running three instances uses almost no additional overhead compared to running one with three databases.
# redis-pipeline.conf
port 6380
maxmemory 1gb
maxmemory-policy noeviction # pipeline jobs must NOT be evicted
save 900 1 # persist pipeline jobs to disk
# redis-cache.conf
port 6381
maxmemory 2gb
maxmemory-policy allkeys-lru # cache should evict LRU freely
save "" # no persistence needed for cache
# redis-sessions.conf
port 6382
maxmemory 512mb
maxmemory-policy volatile-lru # only evict keys with TTL set
save 60 1000 # persist sessions more aggressivelyNotice what this gives you that you absolutely cannot have with multiple databases. Each instance has its own maxmemory and its own maxmemory-policy. Your pipeline instance uses noeviction because job loss is unacceptable. Your cache instance uses allkeys-lru because cache misses are fine. Your session instance uses volatile-lru and persists aggressively. These policies are mutually exclusive requirements. You cannot satisfy them with a single configuration file.
# Application connections — clean and explicit
import redis
pipeline_redis = redis.Redis(host='localhost', port=6380)
cache_redis = redis.Redis(host='localhost', port=6381)
session_redis = redis.Redis(host='localhost', port=6382)
# Now a pipeline burst doesn't evict cache entries
# A FLUSHDB on cache doesn't touch sessions
# A slow pipeline scan doesn't block session lookups
# Each can scale, replicate, and fail independentlyThe Pragmatic Programmer’s core principle of orthogonality applies perfectly here: components that have nothing to do with each other should not share internal state. Your pipeline and your cache are orthogonal concerns. Coupling them through a shared Redis process violates that principle, and you pay for the violation eventually.
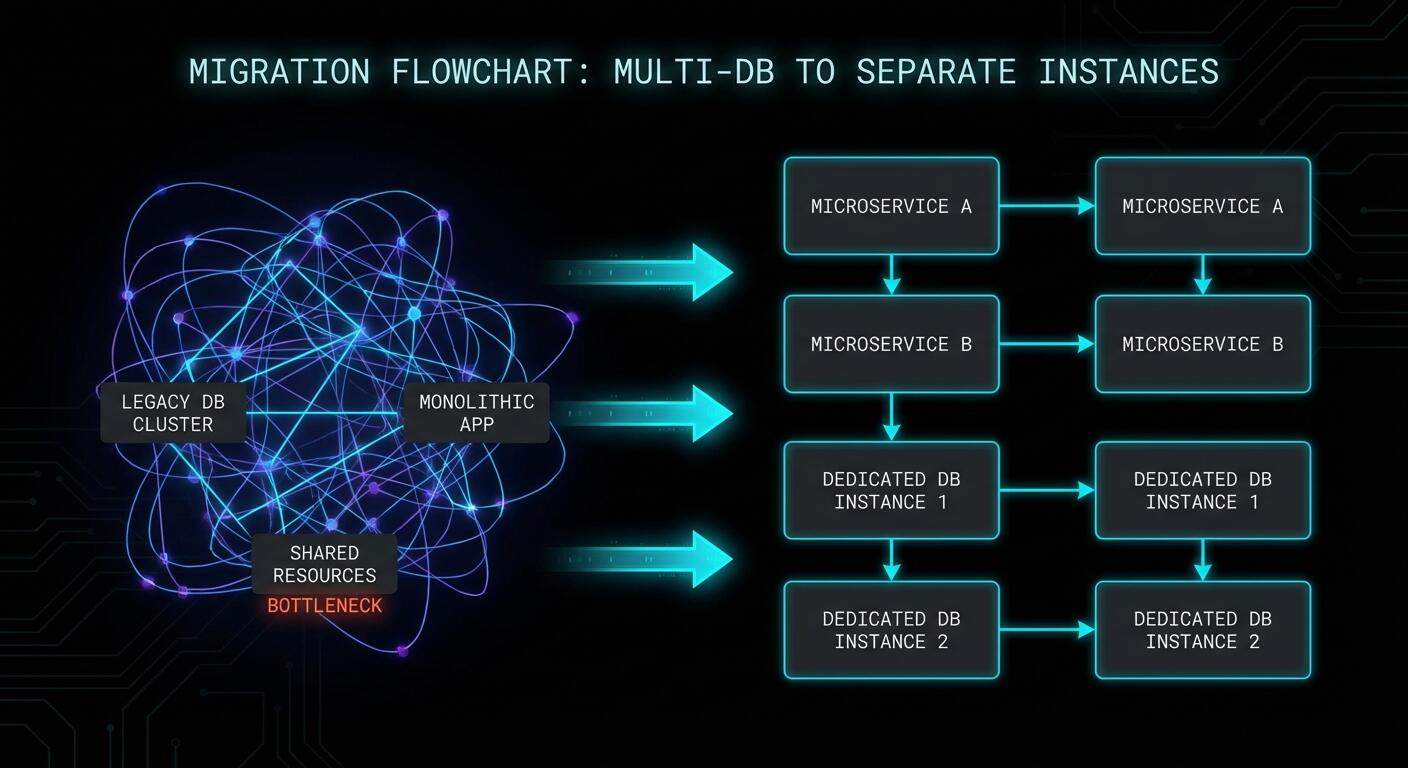
How to Migrate Away From Multiple Databases
If you’re already using multiple databases in production, the migration is straightforward but requires care. Here’s the logical path.
Step 1: Inventory your databases. Connect to your Redis instance and check what’s actually living in each database.
# Check key counts per database
redis-cli INFO keyspace
# Output shows something like:
# db0:keys=1240,expires=1100,avg_ttl=86300000
# db5:keys=340,expires=340,avg_ttl=3598000
# db10:keys=5820,expires=5820,avg_ttl=299000Step 2: Start new instances before touching the old one. Spin up your new Redis instances with appropriate configs for each use case. Don’t migrate anything yet.
Step 3: Dual-write during transition. Update your application to write to both the old database number and the new dedicated instance. Reads still come from the old instance. This gives you a warm new instance without a cold-start cache miss storm.
# Transition period: write to both, read from old
def set_cache(key, value, ttl):
old_redis.select(10)
old_redis.setex(key, ttl, value)
new_cache_redis.setex(key, ttl, value) # warm the new instance
def get_cache(key):
return old_redis.get(key) # still reading from oldStep 4: Flip reads, then remove dual-write. Once the new instance has a reasonable warm state, flip reads to the new instance. Monitor cache hit rates. Once stable for a day or two, remove the dual-write to the old database number.
Step 5: Verify and clean up. After all traffic is on dedicated instances, verify the old database numbers are empty and decommission them.
When Multiple Databases Are Actually Fine
It would be unfair to say multiple databases are always wrong. There are genuine use cases:
- Local development and unit tests — when you want to isolate test data from dev data on a single machine without the overhead of multiple processes. Database 0 for your running dev server, database 1 for tests that get flushed between runs.
- Organisational separation within a single application — separating sessions, cache, and queues within one application that has identical resource requirements and tolerates the same eviction policy. This is the original intended use case.
- Very small applications with negligible traffic — where the Redis instance is nowhere near its limits and you simply want namespace separation without the operational overhead.
The moment you have meaningfully different workloads, different eviction requirements, or need horizontal scaling, multiple databases stop being an organisational convenience and start being a liability.
What to Check Right Now
- Run
INFO keyspace— if you see more than db0 in production with significant key counts, you have work to do. - Check your
maxmemory-policy— one policy cannot serve all use cases correctly. If you have both pipeline jobs and cache data, you need different policies. - Check for Redis Cluster in your roadmap — if it’s there, multiple databases will block you. Start planning the migration now, before you need to scale.
- Audit your
FLUSHDBandFLUSHALLusage — in scripts, Makefiles, CI pipelines, anywhere. Know exactly what would be affected if one of those runs in the wrong context. - Review slow query logs — check if slow commands in one database are causing latency spikes visible in your application metrics at the same timestamps.
Redis is an extraordinary tool. It earns its place in almost every production stack. But its database feature was designed for a simpler era when “run one Redis for everything” was the standard advice. The standard has moved on. Your architecture should too.
nJoy 😉