
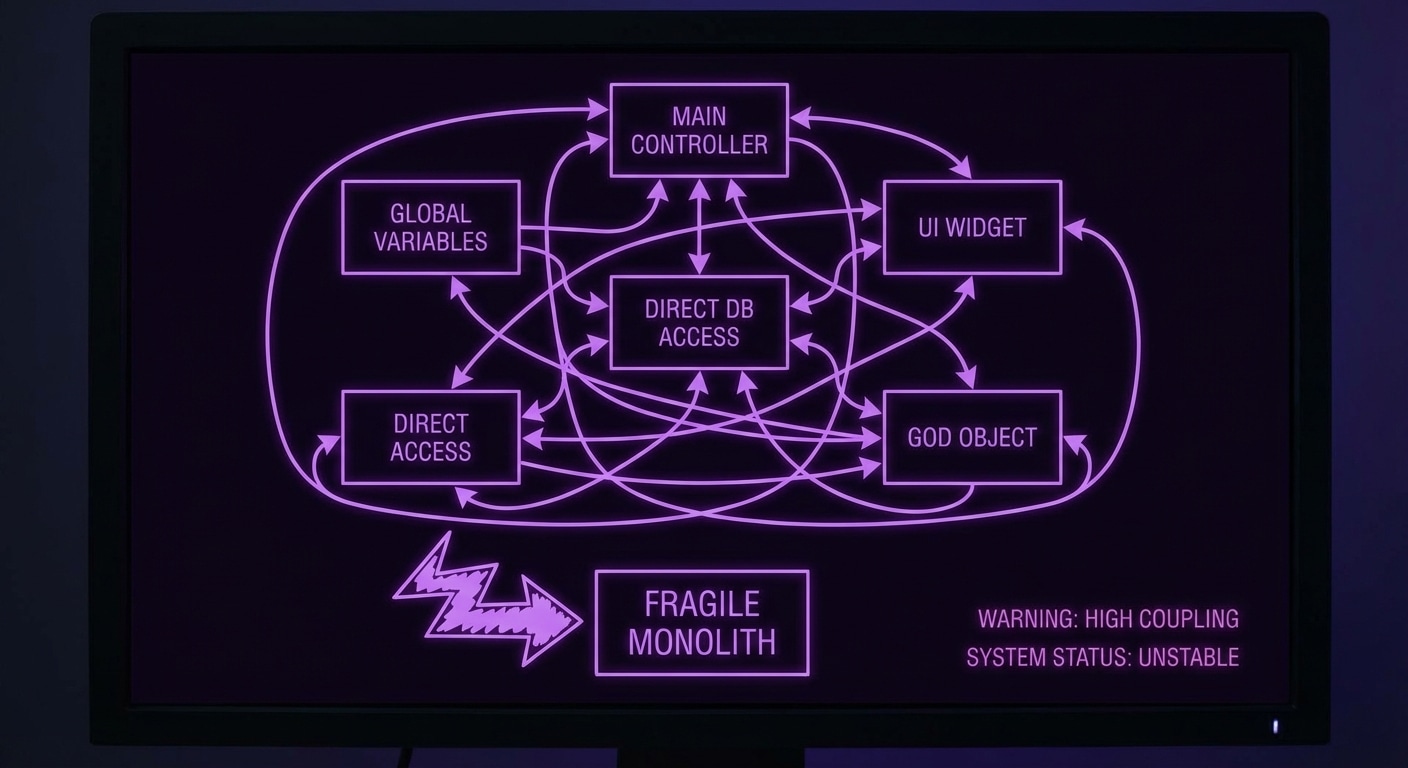
The slop problem is when the model produces code that is technically correct — it compiles, it runs in your test — but is architecturally wrong. It might duplicate logic that already exists elsewhere. It might add a new path that bypasses the intended state machine. It might use a quick fix (a new flag, a special case) instead of fitting into the existing design. So the code “works” but the system gets messier, and the next change is harder. That’s slop: low-quality integration that passes a quick check but fails a design review.
Why it happens: the model doesn’t have a full picture of the codebase or the architecture. It sees the file you opened and maybe a few others. It doesn’t know “we already have a retry helper” or “all state changes go through this function.” So it does the local minimum: solve the immediate request in the narrowest way. The result is correct in the small and wrong in the large.
Mitigations: give the model more context (whole modules, architecture docs), or narrow its role (only suggest edits that fit a pattern you specify). Review for structure, not just behavior: “does this fit how we do things?” Refactor slop when you see it; don’t let it pile up. Some teams use the model only for greenfield or isolated modules and keep core logic and architecture human-written.
The slop problem is a reminder that “it works” is not “it’s right.” Tests verify behavior; they don’t verify design. So the fix is process: architectural review, clear patterns, and a willingness to reject or rewrite model output that doesn’t fit.
Expect more tooling that understands codebase structure and suggests edits that fit the existing architecture, and more patterns for “guardrails” that keep generated code in bounds.
nJoy 😉