
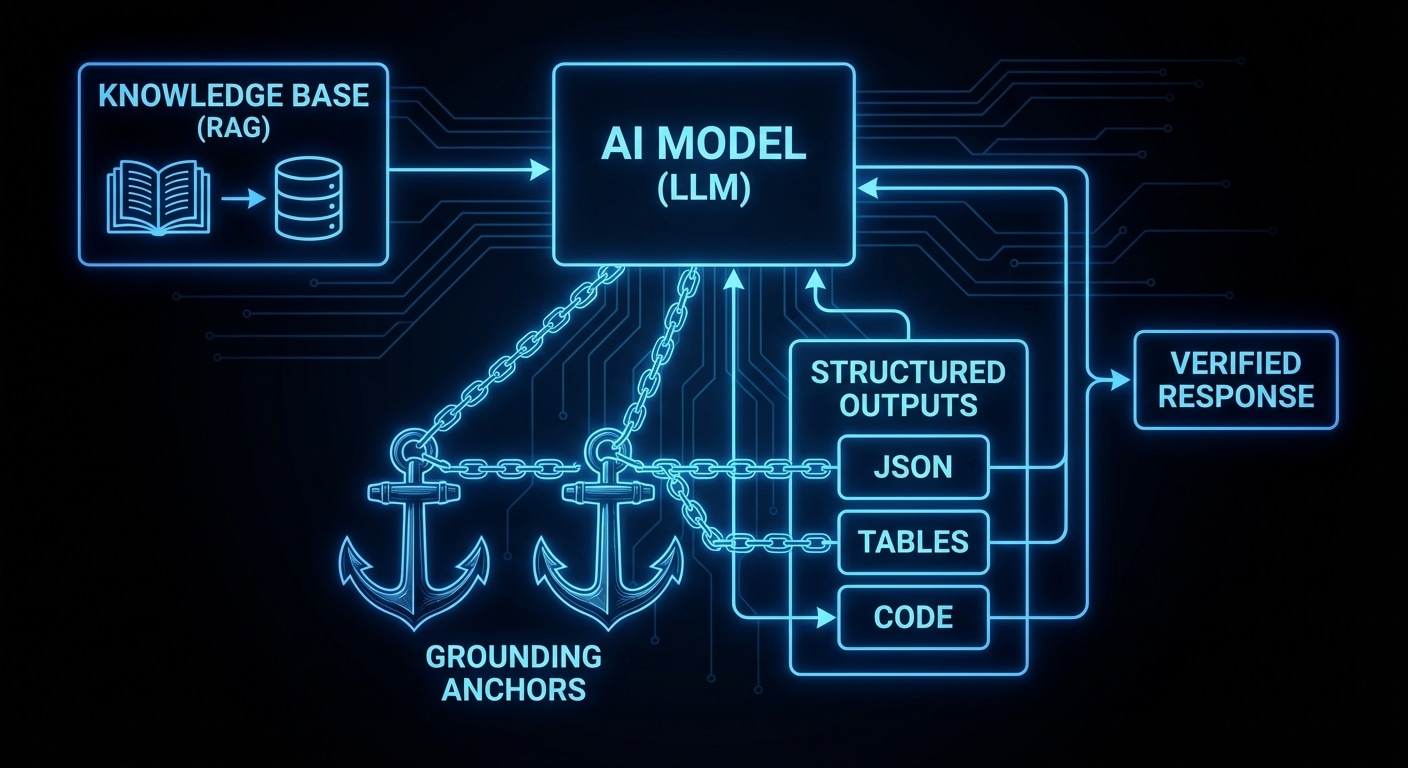
Grounding means tying the model’s output to something external: retrieved documents, tool results, or a strict schema. RAG (retrieval-augmented generation) is the most common: you have a corpus (docs, code, KB), you run a query (user question or embedding), you retrieve the top-k chunks, and you put them in the prompt. The model is then “grounded” in those chunks — it’s supposed to answer from them rather than from memory. It still can hallucinate (e.g. mix chunks or add detail), but the ceiling is lower.
Structured outputs force the model to fill a schema (e.g. JSON with fields like “answer”, “confidence”, “sources”). That doesn’t guarantee truth, but it makes parsing and downstream checks possible. You can require a “sources” array and then validate that each source exists. You can run the answer through a checker (e.g. a query against a DB) before showing it to the user.
Tool use is another form of grounding: instead of the model “remembering” or inventing a fact, it calls a tool (search, API, DB) and you inject the result. The model reasons over the result but doesn’t invent the result itself. So grounding strategies are: (1) put real data in context (RAG), (2) constrain the form of the answer (structured output), (3) get data via tools and let the model interpret it. Often you combine them.
The tradeoff is cost and latency: RAG and tools add retrieval and API calls; structured output can require more tokens or multiple turns. But for any application where correctness matters, grounding is the only reliable path. Unconstrained generation is for draft and exploration; grounding is for production.
Expect more tooling around RAG quality (better retrieval, chunking, and attribution) and tighter integration of tools and structured output in APIs.
nJoy 😉