
LLM Architecture Series – Lesson 16 of 20. A single transformer block is powerful, but modern LLMs use many of them in sequence.
Each additional layer can capture longer range patterns and refine the representations produced by earlier layers.
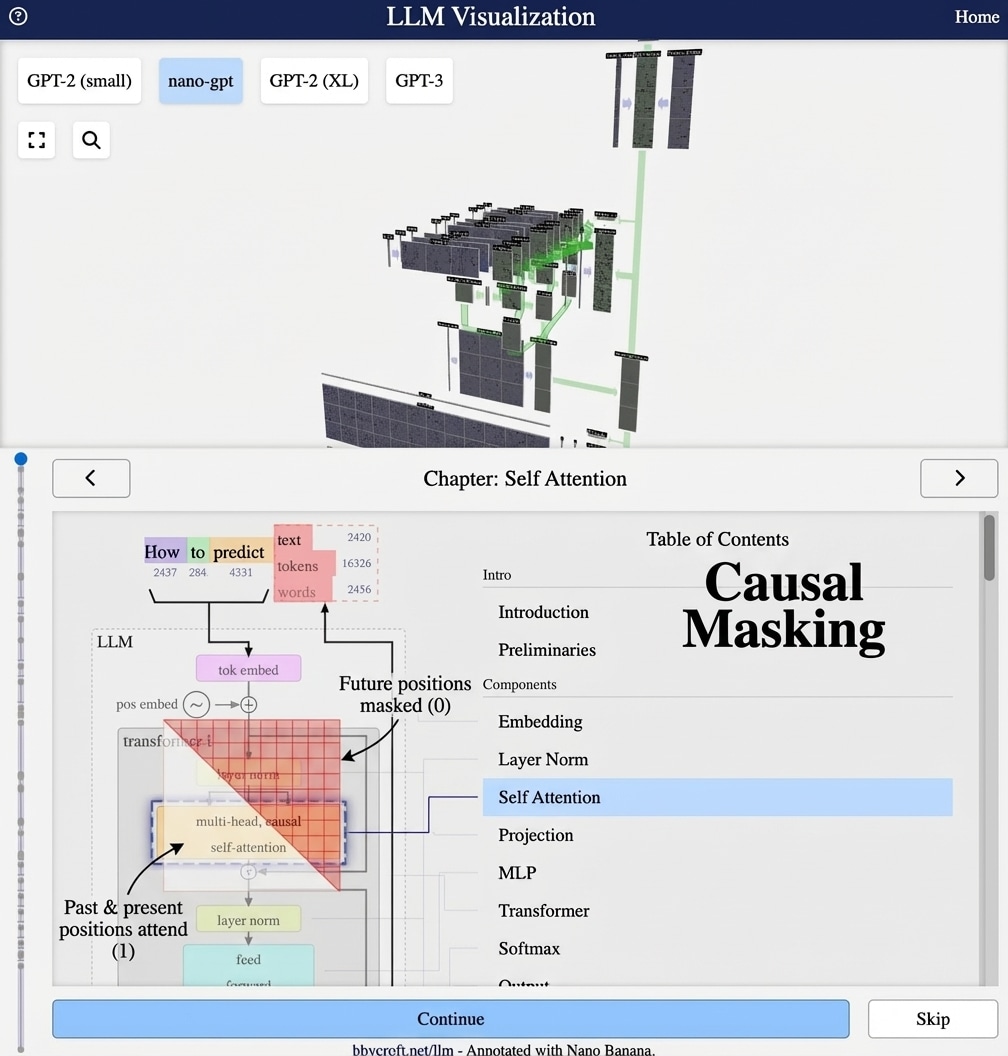
Visualization from bbycroft.net/llm augmented by Nano Banana.
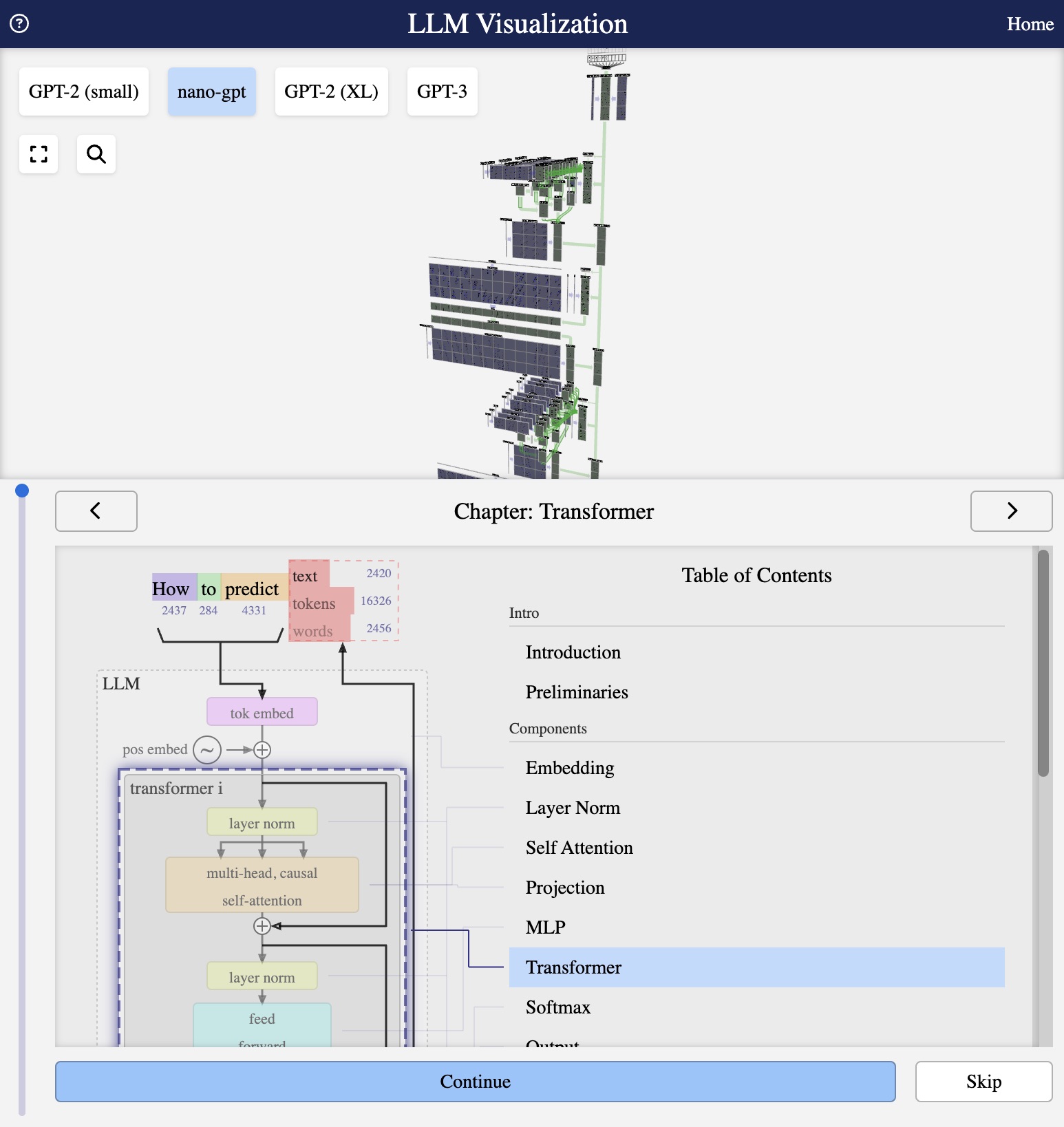
Visualization from bbycroft.net/llm
Depth Creates Power
A single transformer block is useful, but the real power comes from stacking multiple blocks. Each layer refines the representation, building increasingly abstract features.
Layer Numbers
| Model | Layers | Parameters |
|---|---|---|
| nano-gpt | 3 | 85K |
| GPT-2 Small | 12 | 117M |
| GPT-2 XL | 48 | 1.5B |
| GPT-3 | 96 | 175B |
What Happens at Each Layer?
Research has shown different layers learn different things:
- Early layers: Syntax, local patterns, basic grammar
- Middle layers: Semantic meaning, entity relationships
- Later layers: Task-specific features, high-level reasoning
Information Flow
The input flows through all layers sequentially:
embed → block1 → block2 → … → blockN → output
Emergent Abilities
Interestingly, some capabilities only emerge with sufficient depth and scale – things like:
- Multi-step reasoning
- In-context learning
- Following complex instructions
Series Navigation
Previous: Complete Transformer Block
Next: The Output Layer and Language Model Head
This article is part of the LLM Architecture Series. Interactive visualizations from bbycroft.net/llm.
Analogy and intuition
Stacking layers is like rereading the same paragraph several times, each time catching deeper patterns and connections.
Lower layers may focus on local structure such as spelling and syntax, while higher layers capture global meaning and long range dependencies.
Looking ahead
Next we will focus on the output layer that takes the final hidden representation and maps it to vocabulary logits.