
LLM Architecture Series – Lesson 12 of 20. The attention heads produce outputs that must be merged and projected back into the model hidden space.
This is done by a learned linear projection that mixes information from all heads into a single vector per position.
Visualization from bbycroft.net/llm augmented by Nano Banana.
Visualization from bbycroft.net/llm
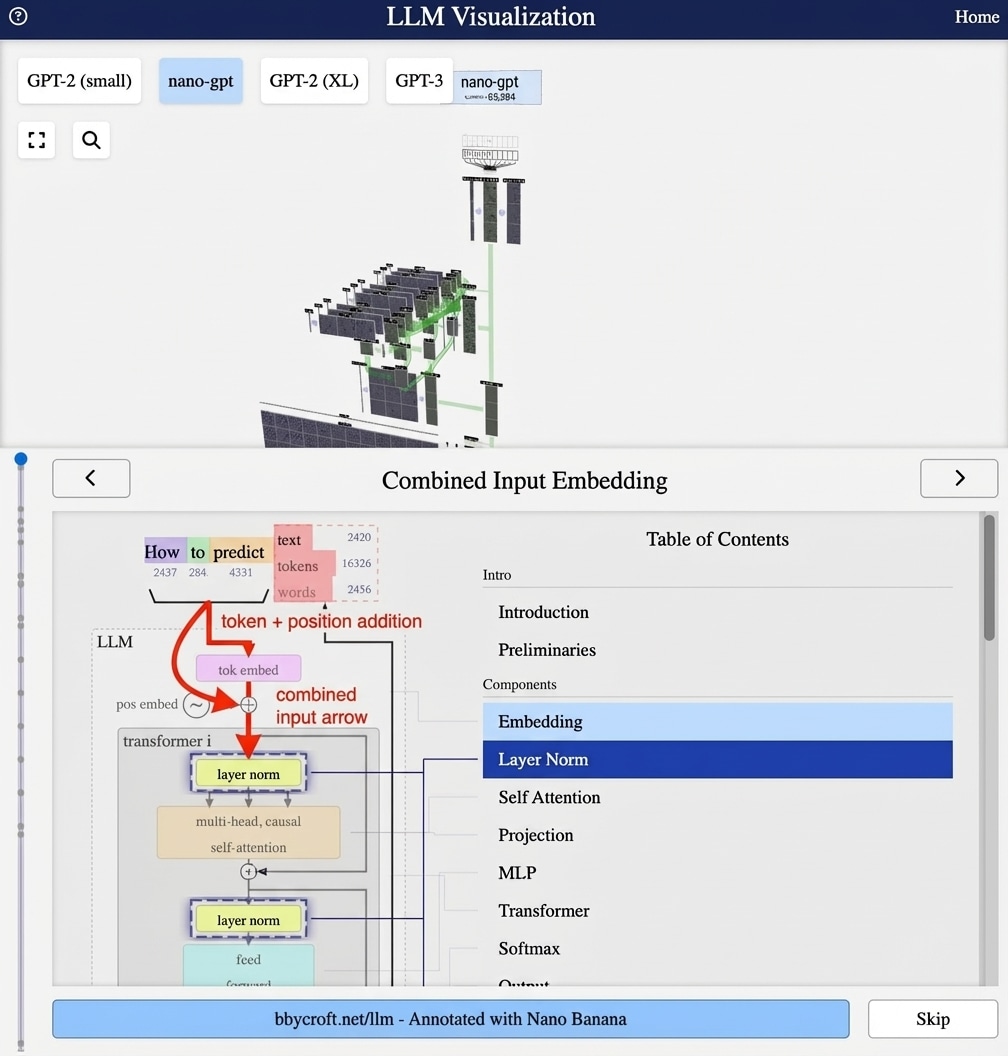
After Attention: The Output Projection
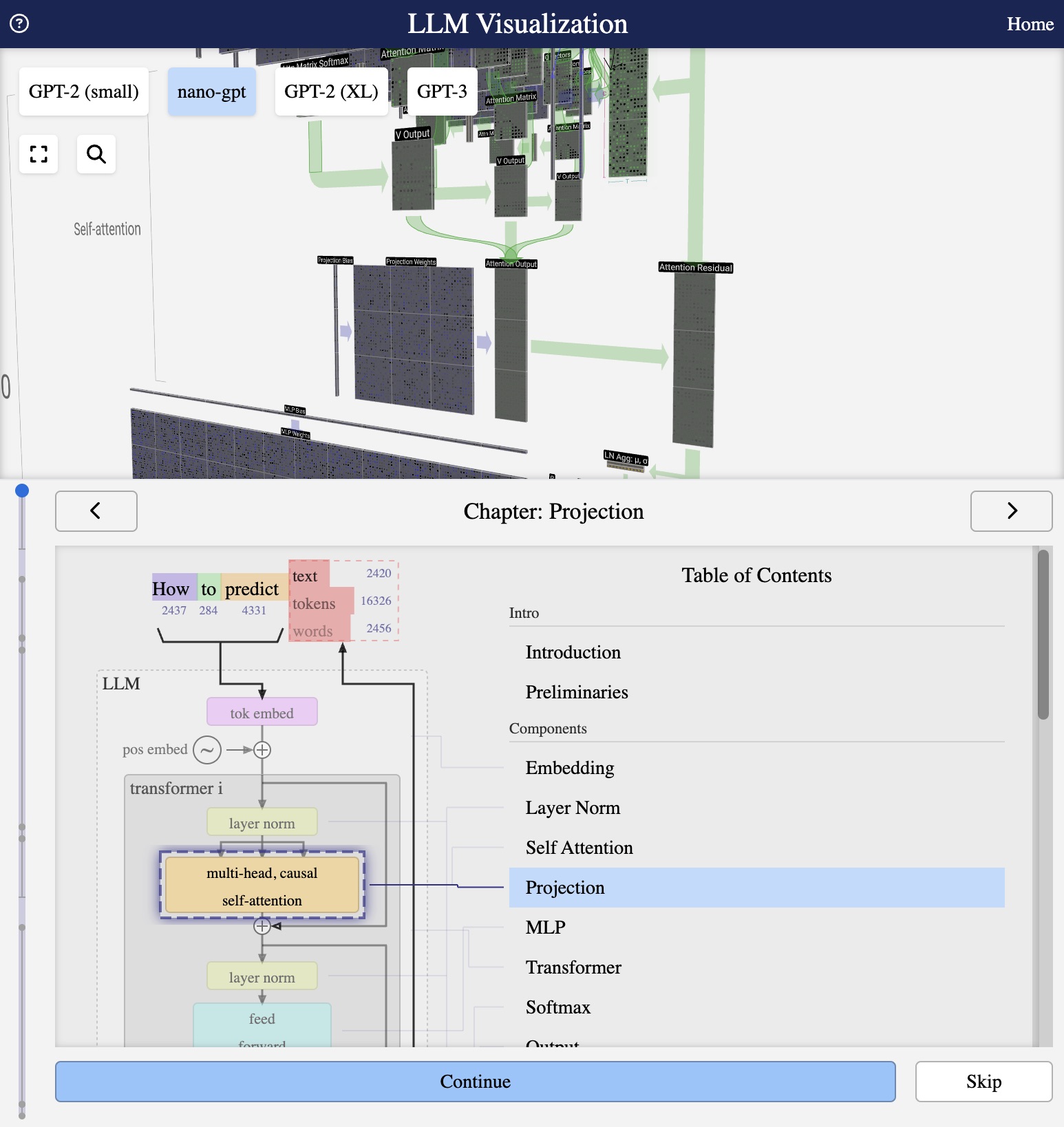
After multi-head attention computes its outputs, we need to combine the results from all heads back into a single representation. This is done by the projection layer.
Concatenate and Project
The multi-head attention output is formed by:
- Concatenate all head outputs along the feature dimension
- Project through a linear layer WO
Output = Concat(head1, …, headh) · WO
Dimension Flow
In nano-gpt with 3 heads and d=48:
- Each head output: 16 dimensions
- Concatenated: 48 dimensions
- After projection: 48 dimensions (same as input)
The Residual Connection
The projection output is added to the original input (residual connection):
output = input + Attention(LayerNorm(input))
This allows gradients to flow directly through the network and helps train very deep models.
In the Visualization
The green arrows show how attention output flows through the projection layer and combines with the residual path before entering the next component.
Series Navigation
Previous: Attention Softmax
Next: Feed-Forward Networks (MLP)
This article is part of the LLM Architecture Series. Interactive visualizations from bbycroft.net/llm.
Analogy and intuition
Think of the projection layer as a mixing desk that takes many specialist channels and blends them into a single track that the next stage can understand.
Although this step is mathematically simple, it is crucial because it decides how the different attention heads interact.
Looking ahead
Next we will explore the feed forward network, a small multilayer perceptron that adds non linear reasoning on top of attention.