
LLM Architecture Series – Lesson 9 of 20. Multi head attention relies on three sets of vectors called queries, keys, and values.
These vectors control how positions compare to each other and how information flows across the sequence.
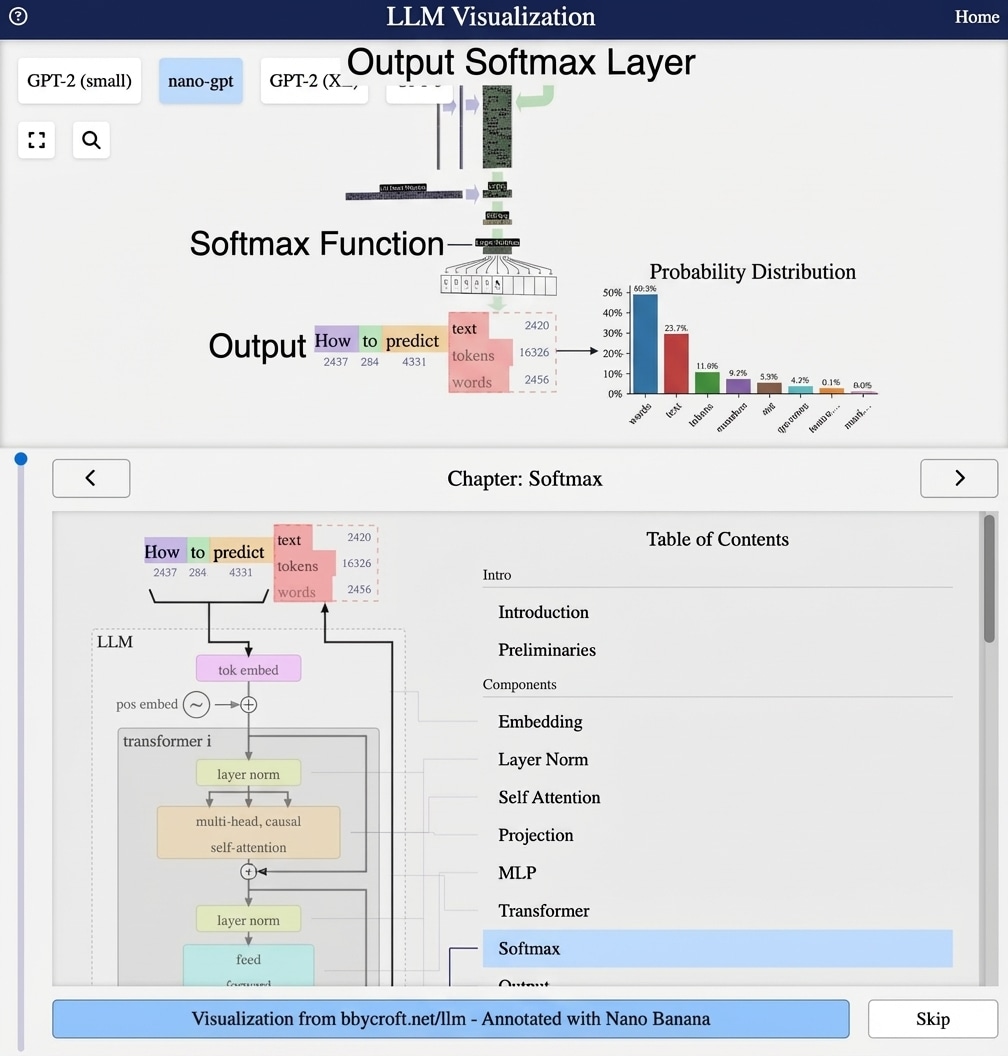
Visualization from bbycroft.net/llm augmented by Nano Banana.

Visualization from bbycroft.net/llm
The QKV Framework
The Query-Key-Value framework is borrowed from information retrieval. Think of it like a database lookup:
- Query: Your search term
- Key: Index entries in the database
- Value: The actual content to retrieve
Linear Projections
Each of Q, K, V is created by multiplying the input by a learned weight matrix:
Q = XWQ ∈ Rn×dk
K = XWK ∈ Rn×dk
V = XWV ∈ Rn×dv
The Attention Computation
The complete scaled dot-product attention:
Attention(Q, K, V) = softmax(QKT / √dk)V
- QKT: Compute all pairwise similarities
- / √dk: Scale to prevent extreme values
- softmax: Convert to probability distribution
- × V: Weighted sum of values
Why Separate Q, K, V?
Having separate projections allows:
- Asymmetric relationships (A attends to B differently than B to A)
- Flexible feature extraction for different purposes
- Richer representational capacity
Series Navigation
Previous: Multi-Head Attention
Next: Causal Masking – Preventing Future Leakage
This article is part of the LLM Architecture Series. Interactive visualizations from bbycroft.net/llm.
Analogy and intuition
You can think of keys as entries in a library catalog, queries as search requests, and values as the actual book contents that are returned.
By adjusting queries and keys, the model can learn very flexible rules about which words should interact strongly in each context.
Looking ahead
Next we introduce causal masking, which prevents the model from looking into the future when it predicts the next token.