
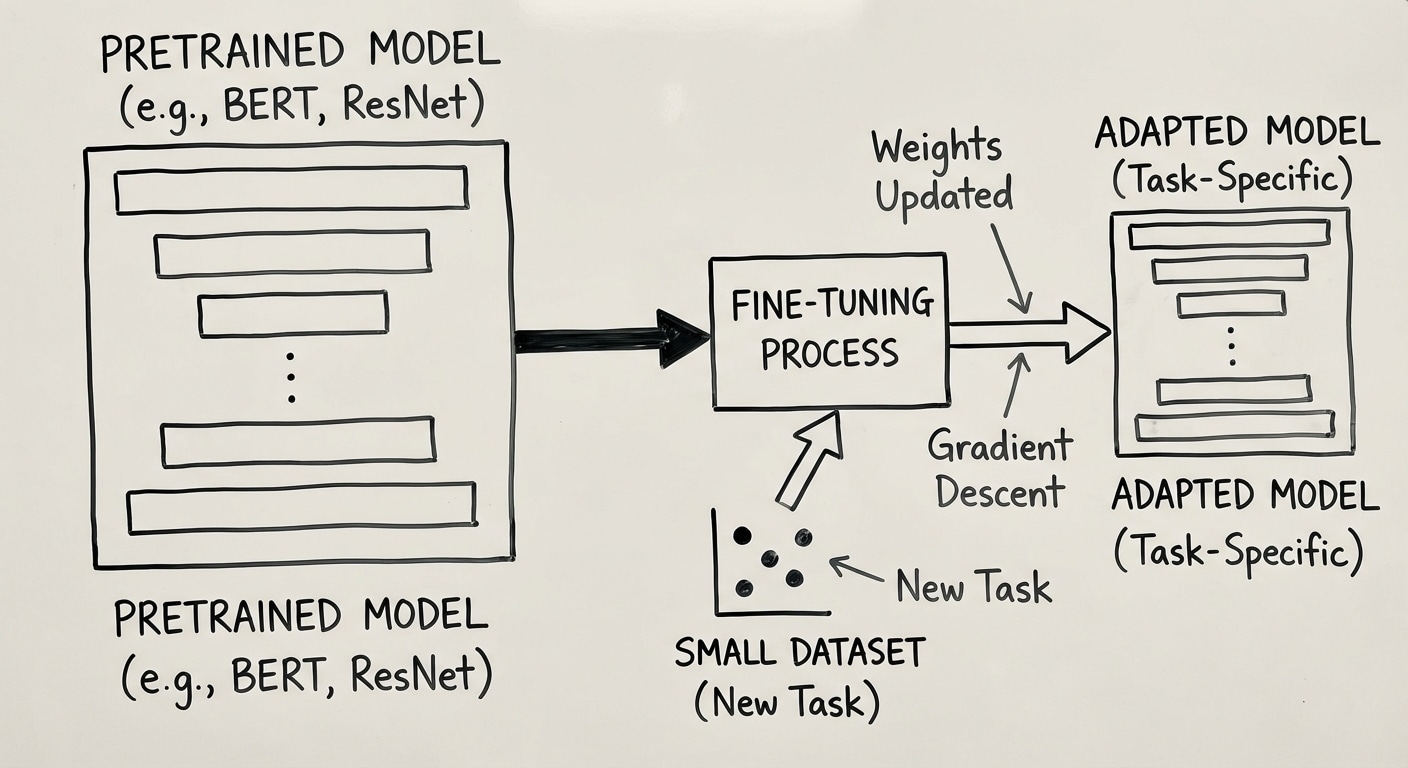
Fine-Tuning: Adapting Pre-trained Models
Fine-tuning transfers knowledge from large pre-trained models to specific tasks with limited data. This paradigm revolutionized AI by making powerful models accessible without requiring massive datasets or compute budgets for each new application.
The process involves taking a model pre-trained on massive general data, then continuing training on task-specific data with a lower learning rate. The pre-trained weights provide excellent initialization, and fine-tuning adapts them to the new domain.
Different strategies trade off between performance and efficiency. Full fine-tuning updates all parameters for best results but requires significant compute. LoRA adds small trainable matrices alongside frozen weights, achieving 90%+ of full fine-tuning performance with a fraction of parameters.
Best practices include using lower learning rates than pre-training, employing warmup steps, monitoring validation loss for early stopping, and considering gradual unfreezing where deeper layers train first before unfreezing earlier layers.