
GPT: Inside Large Language Models
GPT (Generative Pre-trained Transformer) uses a decoder-only architecture to generate text token by token. Understanding its internals reveals how modern AI achieves remarkable language capabilities through elegant architectural choices.
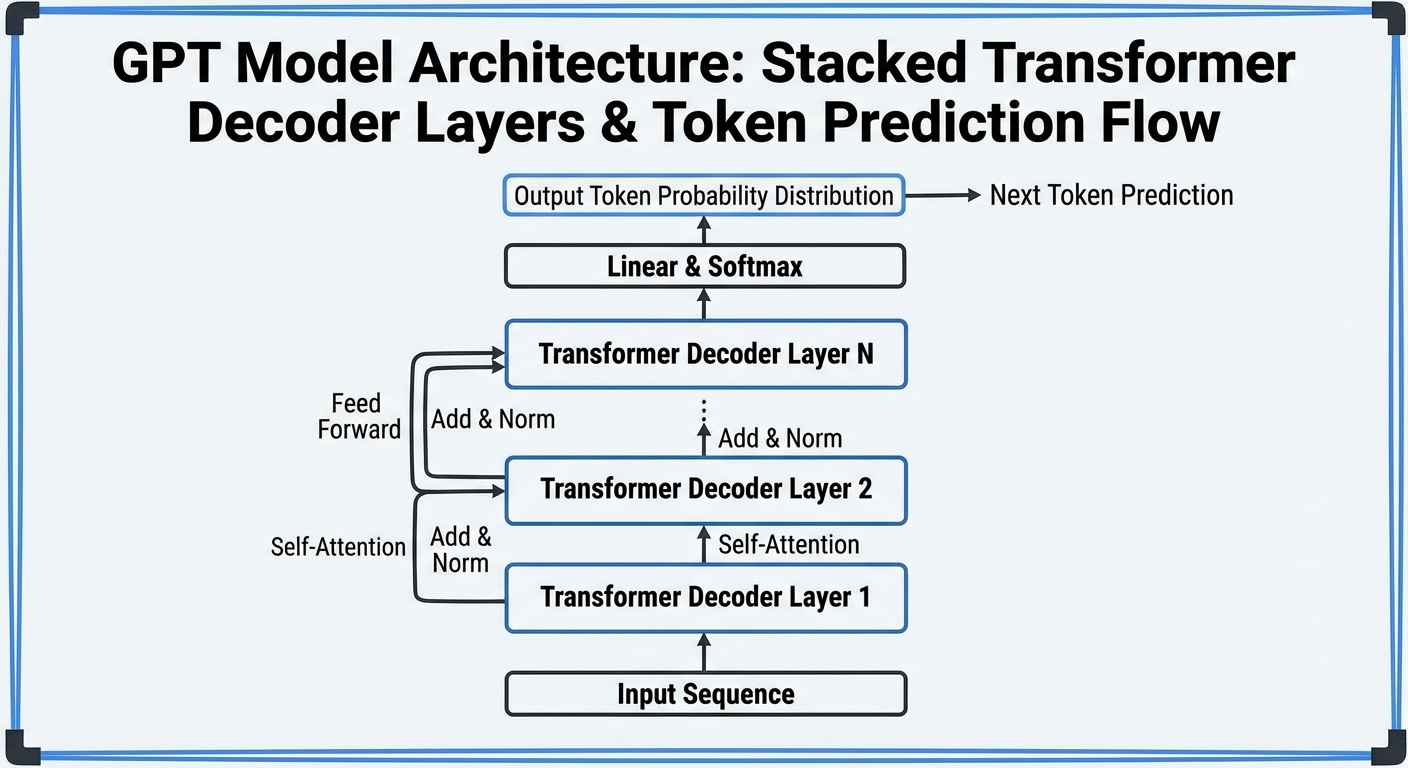
Each token receives embedding plus positional encoding, then passes through stacked Transformer blocks. Each block contains masked self-attention (can only attend to previous tokens) and feed-forward networks. This autoregressive structure enables coherent text generation.
Scale proves critical for emergent capabilities. GPT-2 had 1.5B parameters, GPT-3 scaled to 175B, and GPT-4 reportedly exceeds a trillion. With scale comes surprising abilities: few-shot learning, reasoning, and code generation that emerge without explicit training.
Generation works by processing input tokens through all layers, predicting probability distribution over vocabulary for the next token, sampling from that distribution, appending the result, and repeating. Temperature and top-p sampling control creativity versus coherence.