
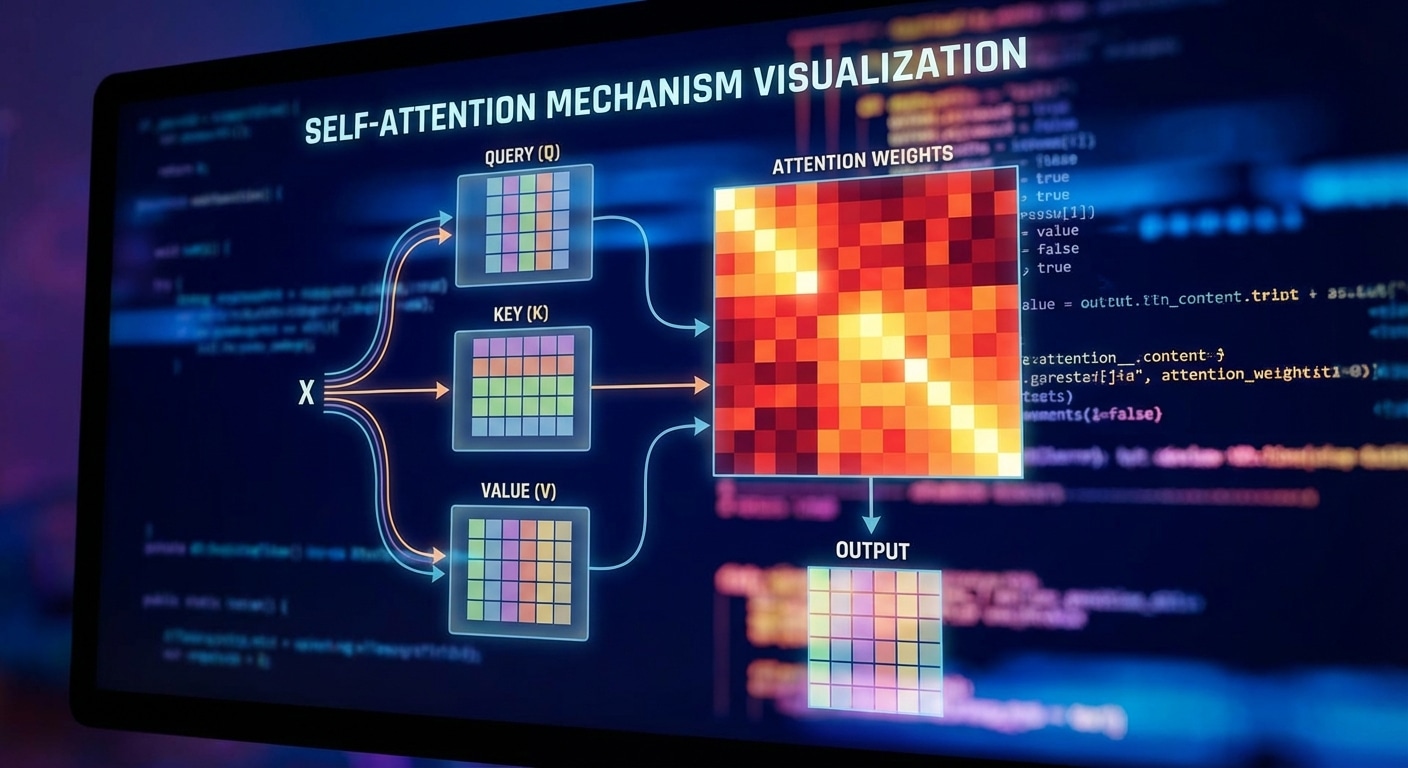
Self-Attention: The Core of Transformers
Self-attention allows each element in a sequence to attend to all other elements, capturing relationships regardless of distance. This mechanism revolutionized NLP by replacing recurrence with parallelizable attention operations that model long-range dependencies more effectively.
For each token, three vectors are computed: Query (what am I looking for), Key (what do I contain), and Value (what information do I provide). Attention weights come from the dot product of Query and Key, normalized by softmax. These weights determine how much each token contributes to the output.
Multi-head attention runs multiple attention mechanisms in parallel, each learning to focus on different relationship types. One head might capture syntactic dependencies while another focuses on semantic similarity. Concatenating and projecting results combines these perspectives.
The attention mechanism enables remarkable capabilities in language models. A model can understand that a pronoun refers to a noun mentioned paragraphs earlier, or that a technical term definition from the context applies throughout. This contextual understanding underpins modern LLM performance.