
Transformers: The Architecture Behind Modern AI
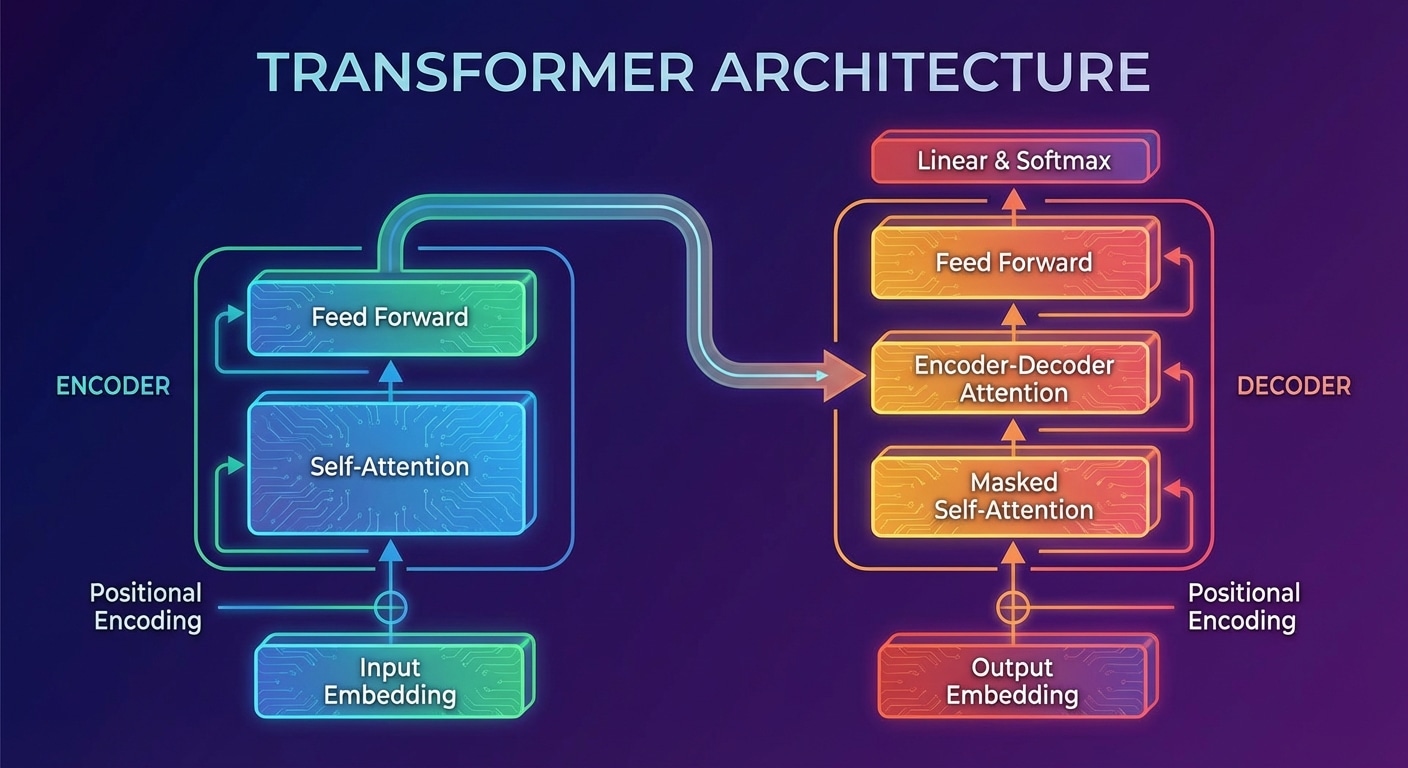
The Transformer architecture, introduced in the landmark 2017 paper Attention Is All You Need, revolutionized artificial intelligence. It powers GPT, BERT, and virtually every modern language model. Unlike previous sequential models, Transformers process entire sequences simultaneously, enabling unprecedented parallelization and long-range dependency modeling.
The key innovation is self-attention, allowing each element to attend to all others regardless of distance. Components include the encoder for understanding input and decoder for generating output. Multi-head attention runs multiple attention mechanisms in parallel, each learning different relationship types like syntax, semantics, and coreference.
Transformers win because they are highly parallelizable across GPUs, can model dependencies across thousands of tokens, and scale predictably with more data and parameters. This scaling behavior led to the emergence of capabilities in large language models that surprised even their creators.
Understanding Transformer architecture is essential for modern AI development. Whether fine-tuning pre-trained models or building custom solutions, knowing how attention mechanisms, positional encodings, and feed-forward layers interact enables effective model design and debugging.