The loudest take on Moonshot’s Kimi K3 is that open weights just “crushed” every closed frontier model. That is marketing gravity, not the lab’s own claim. Treat K3 as what it is: a 2.8-trillion-parameter open 3T-class model with a 1M-token window, native vision, and long-horizon agent strength, that still trails the tip of the closed pack on overall performance, whilst beating it on enough specialised suites that a single-model default is now the expensive mistake.
What K3 actually is
Open 3T-class · 1M context · native vision · long-horizon coding

Moonshot’s launch post is unusually honest for a frontier drop. K3 is built on Kimi Delta Attention (KDA) and Attention Residuals (AttnRes), activates 16 of 896 experts under Stable LatentMoE, and is framed for long-horizon coding, knowledge work, and reasoning. Full weights were scheduled for 27 July 2026. Official API pricing at launch: $0.30/MTok cache-hit input, $3.00/MTok cache-miss input, $15.00/MTok output, with Moonshot claiming above 90% cache hit rates on coding workloads.
“While its overall performance still trails the most powerful proprietary models, Claude Fable 5 and GPT 5.6 Sol, Kimi K3 demonstrated frontier-level performance across our evaluation suite, consistently outperforming other tested models.” – Moonshot AI, Kimi K3 tech blog
Hold that sentence against the social-media version. Trails the tip. Outperforms the rest of the tested field. Specialist leaderboards (frontend arenas, terminal suites, legal-agent sets) can still put an open model first without rewriting the overall ranking. If your strategy needs “open crushed closed forever”, you will over-commit. If your strategy needs “open is finally good enough that routing becomes the product”, K3 is the proof point.
Merits of the argument. The open 3T-class framing and the long-horizon coding demos (kernel work, compiler construction, vision-in-the-loop frontend) are load-bearing and primary-sourced. The geopolitics story and the “first open model to dominate every closed model” story are not. Prefer the lab’s caveat over the thumbnail.
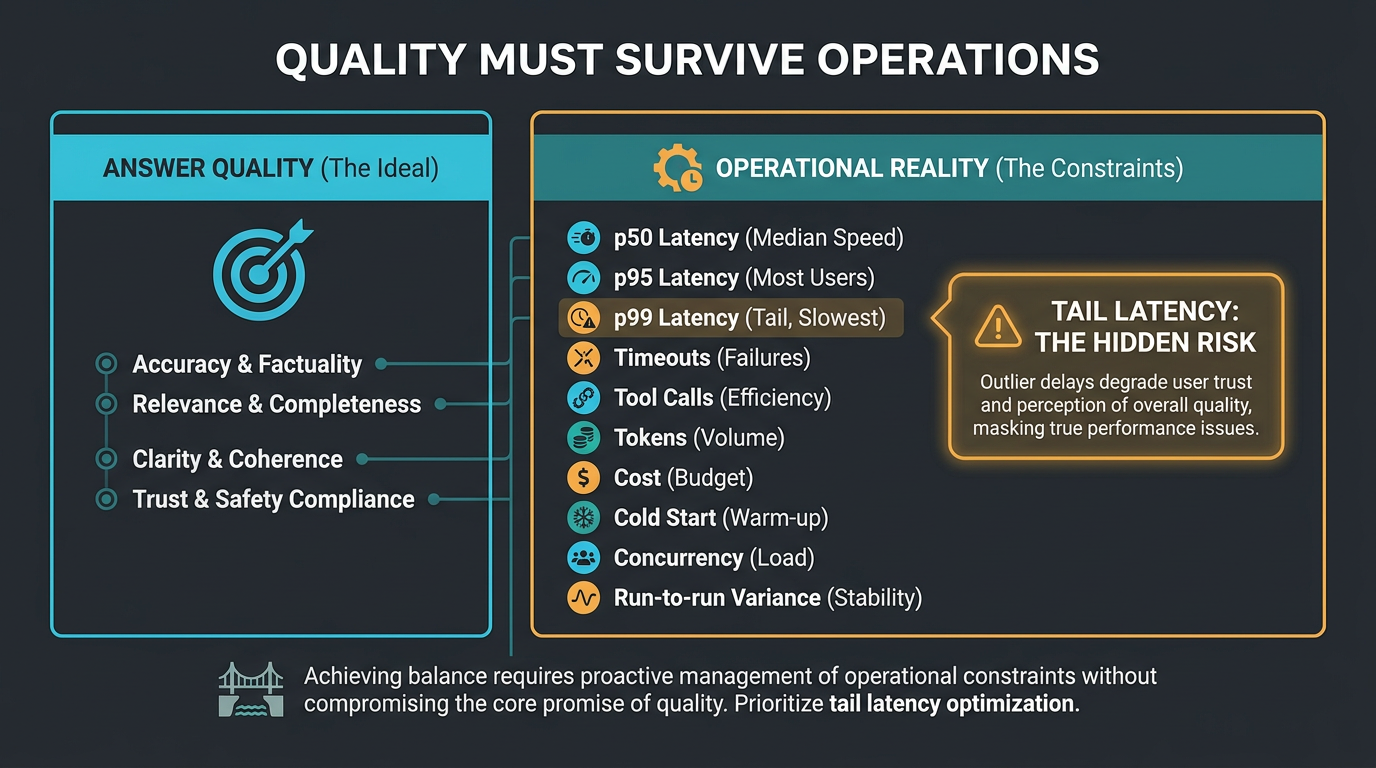
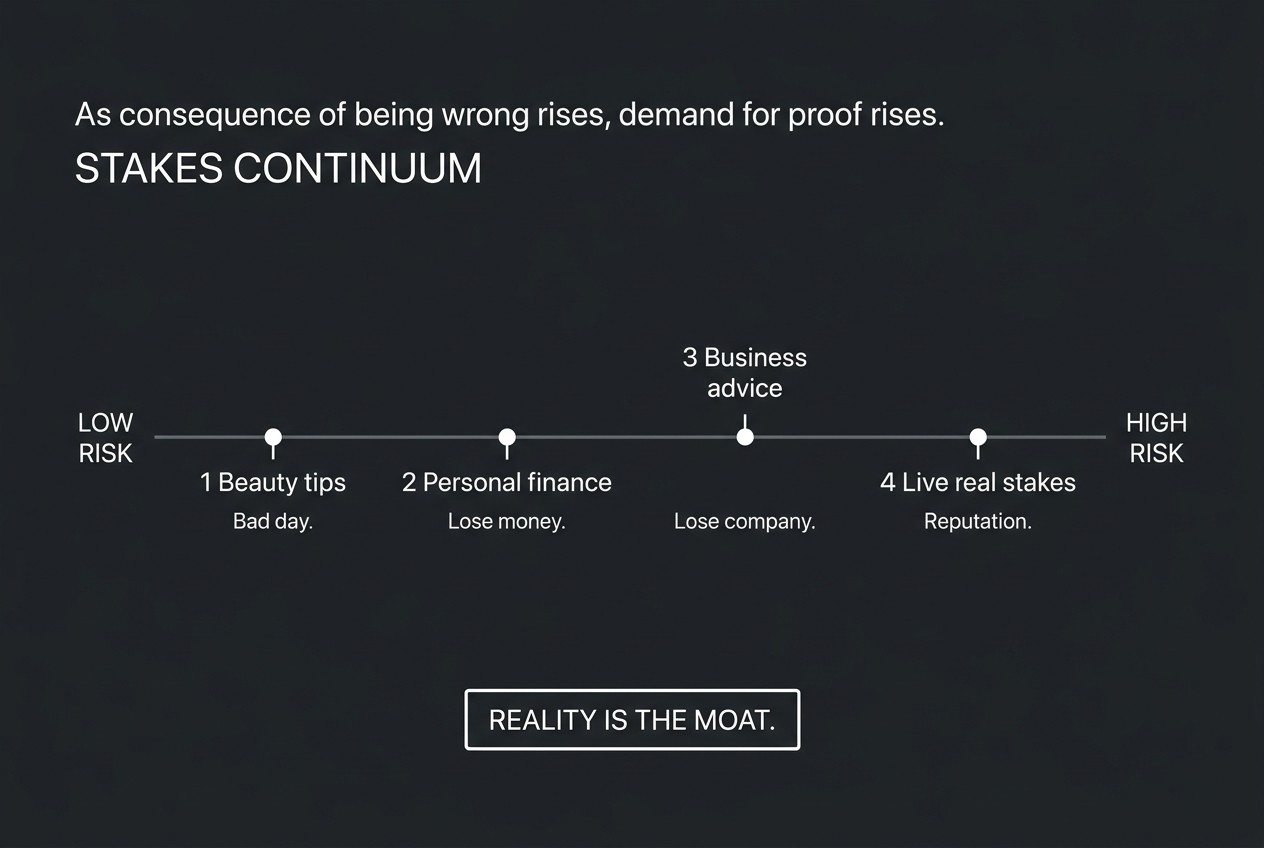
Sticker price is a trap; cost per task is the metric
Cache hits · turns · tokens · wall-clock
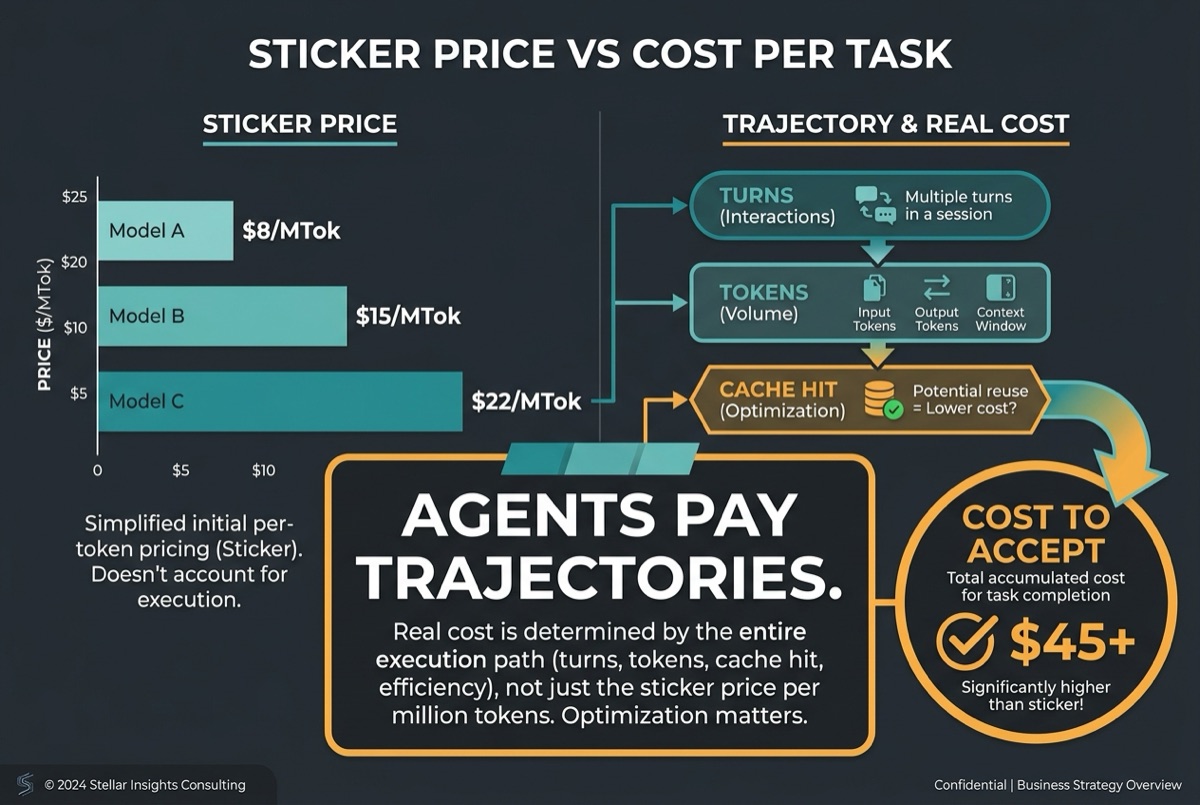
Everyone quotes input and output rates. Agents do not pay rates; they pay trajectories. A mid-tier model that needs three retries, fifty tool turns, and a bloated context can outspend a flagship that finishes in one disciplined loop. Fireworks’ K3-versus-Fable study makes this concrete: on SWE-style work, K3 often burned far more turns and tokens than Fable, yet still landed cheaper once prompt caching kicked in; on long terminal tasks the spiral flipped and Fable was the one that timed out expensive.
Operational rule: instrument cost per accepted task (and turns-to-accept), not only blended $/MTok. Design prompts and tools so the long prefix is stable enough to hit Moonshot’s automatic context cache (their docs note a previous request must exceed 256 prompt tokens before a later request can hit cache). A 10× token read at $0.30 cache-hit can beat a “cheaper” model that never caches.
Merits of the argument. Cost-per-task is the right unit for agent economics; Kleppmann-style systems thinking applies: measure the path, not the component. Weak point: vendor cache-hit rates are workload-specific. Re-measure on your harness before you rewrite finance slides.
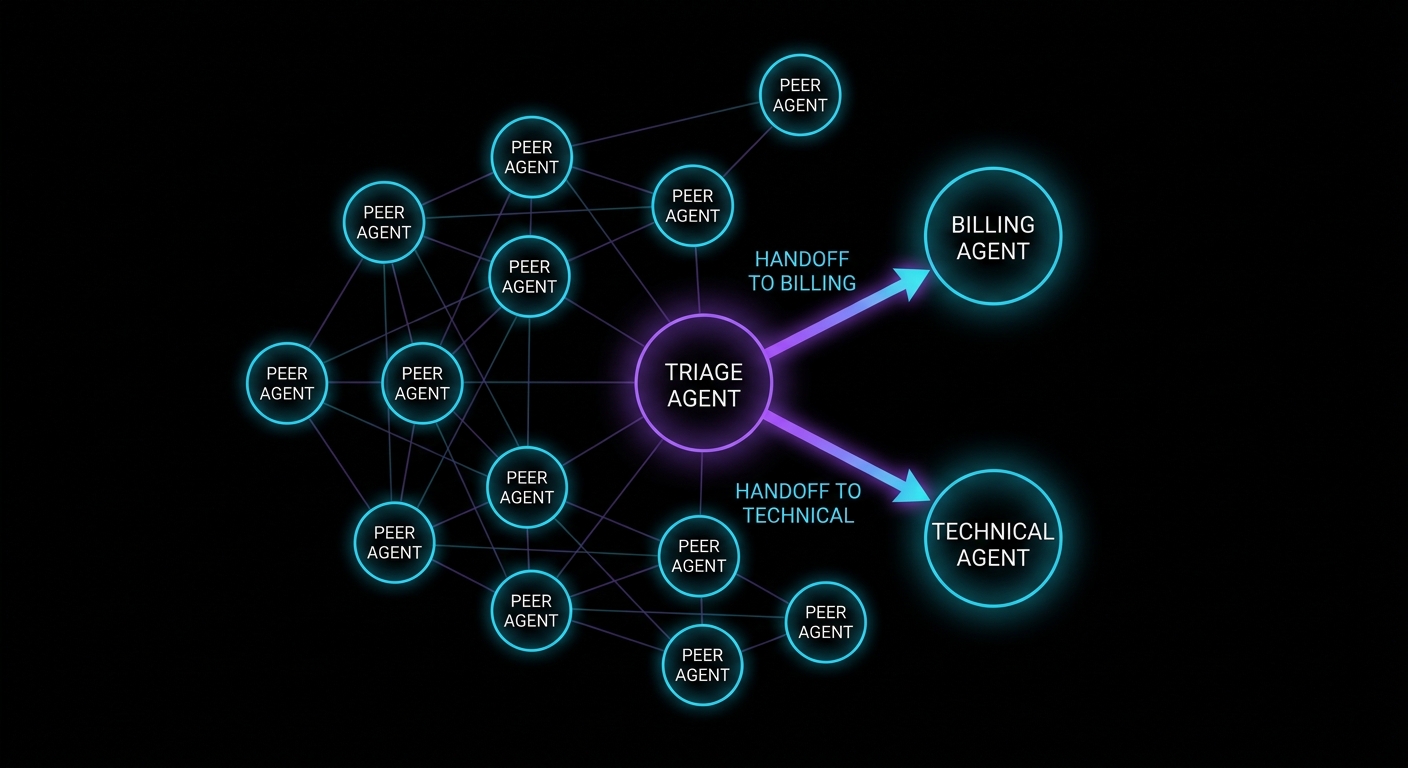
Do not pick a model; route
Specialists · oracle ceiling · production router
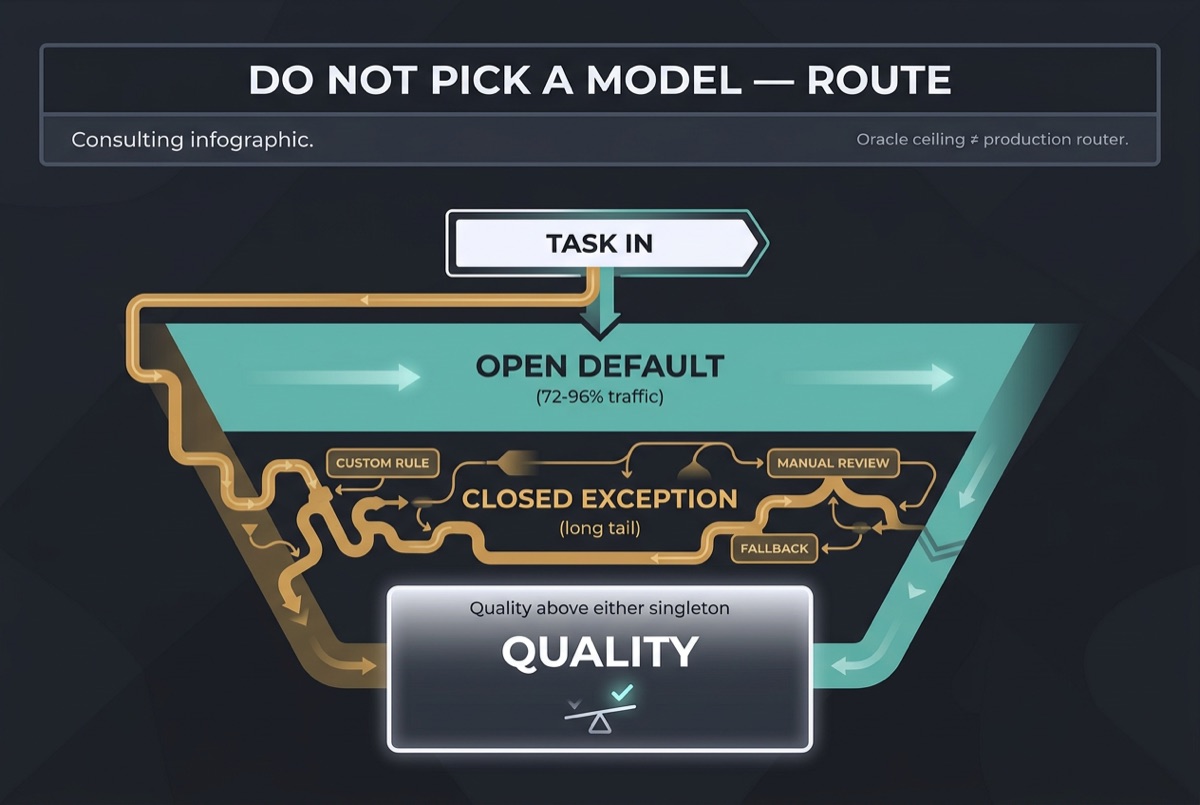
Fireworks ran Kimi K3 and Claude Fable 5 through the same agent harness on about 1,030 tasks across SWE, terminal, algorithmic, multi-language, and legal families. Top-line solve rates looked near-tied. Under the hood they specialised: K3 took more of the security, crypto, and long terminal cluster; Fable kept breadth on multi-language and web/data-visualisation slices. Per-task routing beat either model alone.
“We achieved 93% accuracy with routing between K3 and Fable.” – Fireworks AI, Kimi K3 vs Fable study
Read the fine print they published in the same post. Their headline routing figure is driven by oracle routing: run both models, keep the cheapest correct answer. That is a performance ceiling, not a shipped classifier. Oracle traffic still sent 72-96% of tasks to K3 depending on family, which is the strategic signal: open as the default lane, closed as the long-tail exception. Fireworks also sells inference, so treat the cost multiples as directional and rebuild the router on your own eval set (the same discipline we argued in Stop Sending Every Prompt to Your Flagship Model).
Merits of the argument. Specialist complementarity is real and more useful than fan wars. The 93% figure is not a production SLA until you have a router that predicts without double-running. Build that router; do not cosplay it.
Architecture that matters (and claims that do not)
KDA · AttnRes · MoE sparsity · what not to quote
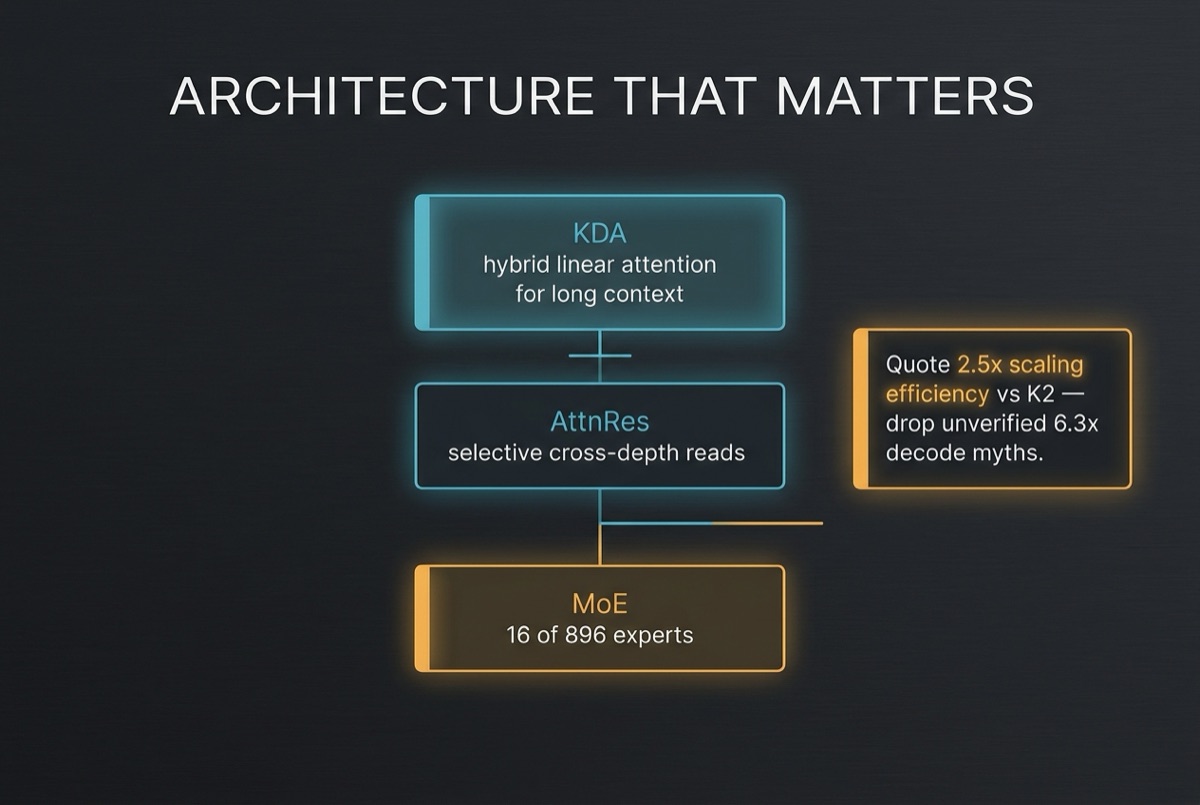
Two mechanisms are primary-sourced for K3. KDA is Moonshot’s hybrid linear-attention path for long sequences. AttnRes lets deeper layers attend selectively to earlier layer states instead of drowning every insight in one shared residual soup. Combined with aggressive MoE sparsity (16 active of 896), Moonshot reports roughly 2.5× overall scaling efficiency versus Kimi K2. That is the quoteable engineering story.
What does not survive a source check: a precise “6.3× faster decode at 1M tokens because of KDA” line circulating in explainers. Moonshot’s K3 post does not state that figure. A separate ~5-6× throughput claim appears around Kimi Code’s HighSpeed tier on the K2.7 coding stack, which is a product speed tier, not a K3 architecture footnote. Likewise, tidy “plus 25% effective compute for under 2% latency” AttnRes soundbites need a paper citation before they become lecture truth; stick to the published 2.5× scaling-efficiency claim until the technical report lands.
Merits of the argument. Architecture explainers help operators decide when long context and overnight agent loops are the point. Invented multipliers destroy trust. If you cannot grep it on the lab page, paraphrase or cut.
Harness rules that silently break K3
Thinking history · reasoning effort · OpenAI-compatible API · approvals

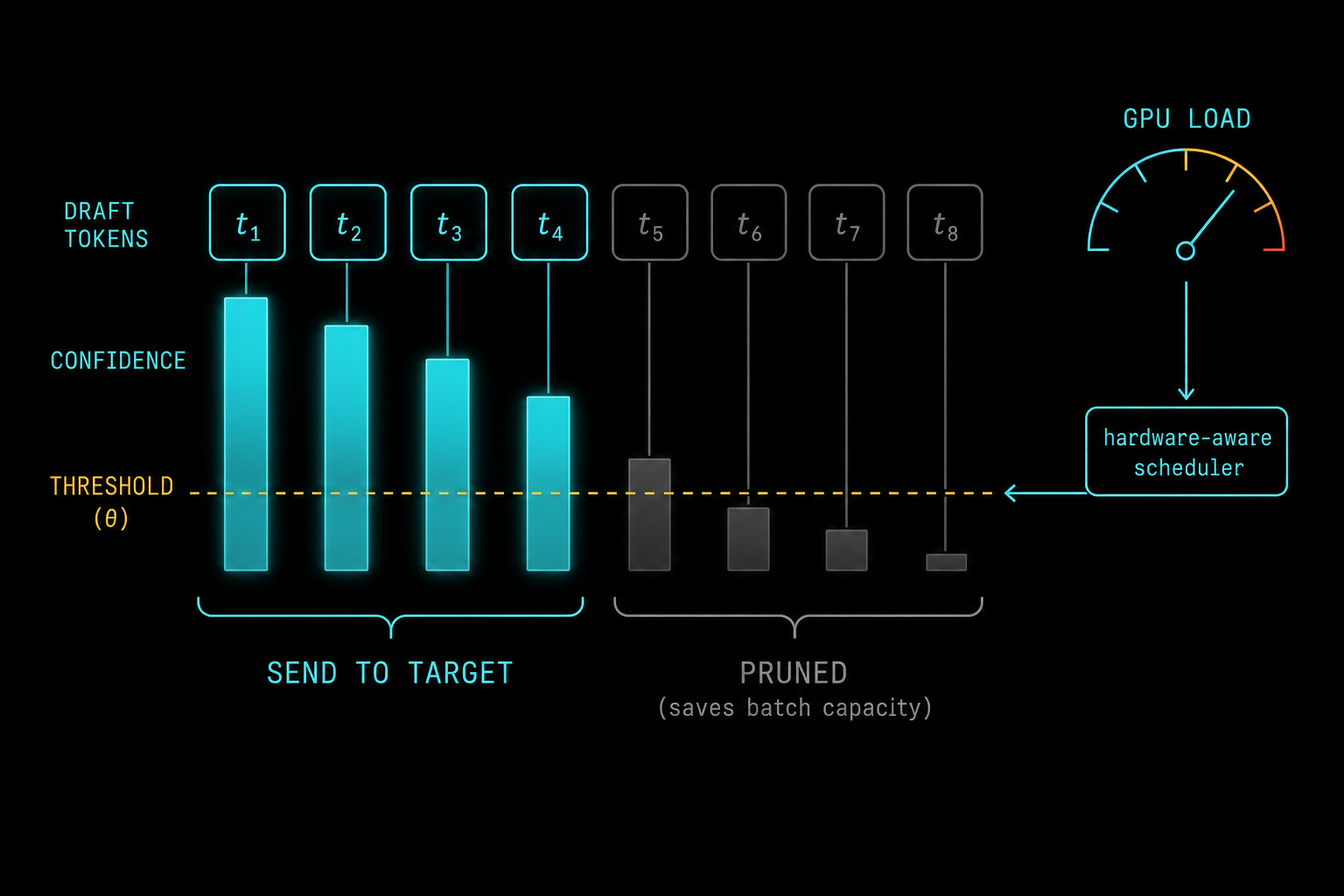
K3 is not a drop-in chatbot personality you can hot-swap mid-thread. Moonshot trained it with preserved thinking history. If your agent framework strips reasoning_content, truncates assistant messages, or switches into K3 halfway through a session started on another model, quality can collapse without a clean error.
“K3 was trained in the preserved thinking history mode. If the agent harness fails to pass back all the historical thinking content as required, or if an ongoing session with another model is switched over to K3, generation quality may become highly unstable.” – Moonshot AI, Kimi K3 limitations
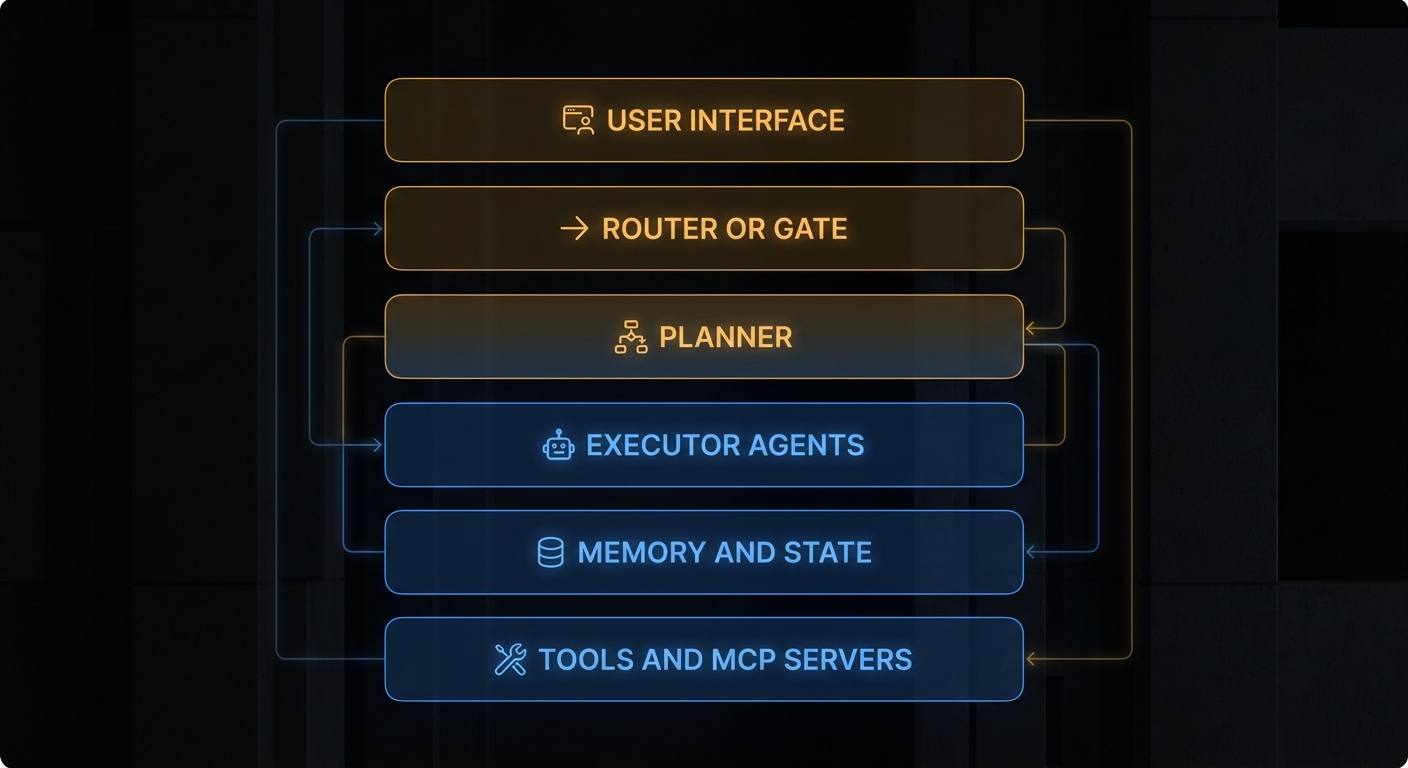
API reality check from the official quickstart: model id kimi-k3, OpenAI-compatible client against Moonshot’s base URL, thinking always on, reasoning_effort of low / high / max (default max at launch). Max effort on trivia is how you set money on fire. Low effort on a multi-hour repo migration is how you get confident wrongness. First-party Kimi Code is the compatibility reference; third-party harnesses (Claude Code, Codex, Pi, custom loops) need an explicit “full assistant message round-trip” test before you trust overnight runs. Pair that with the agent-ops hygiene from Talk to One Agent, Ship With a Crew: one captain surface, gated merges, no YOLO on production trees.
Moonshot also warns about excessive proactiveness: on ambiguous intent, K3 may invent a plan and execute it. That is a feature for long-horizon demos and a liability for regulated repos. Put behavioural fences in system prompts or AGENTS.md when the blast radius is real.
Case 1: Stripped thinking history
A proxy keeps only final content to “save tokens”. Multi-turn tool use drifts, then hallucinates file paths that never existed. Fix: persist and resend the complete assistant message, including reasoning fields, exactly as returned.
Case 2: Max effort for every prompt
Status updates, renames, and one-line shell questions run at max. Bills look like a research lab; latency feels like dial-up. Fix: default high or low for interactive crumbs; reserve max for planned agent jobs with a budget.
Case 3: Single-model religion
All traffic to K3 because the open narrative feels righteous, or all traffic to Fable because the brand feels safe. You pay the specialist tax either way. Fix: route by task family on a frozen eval set; keep a closed model for the long tail your open default fails.
Merits of the argument. The thinking-history constraint is an official footgun, not folklore. Effort knobs and approval gates are boring and they are what separate demos from operations.
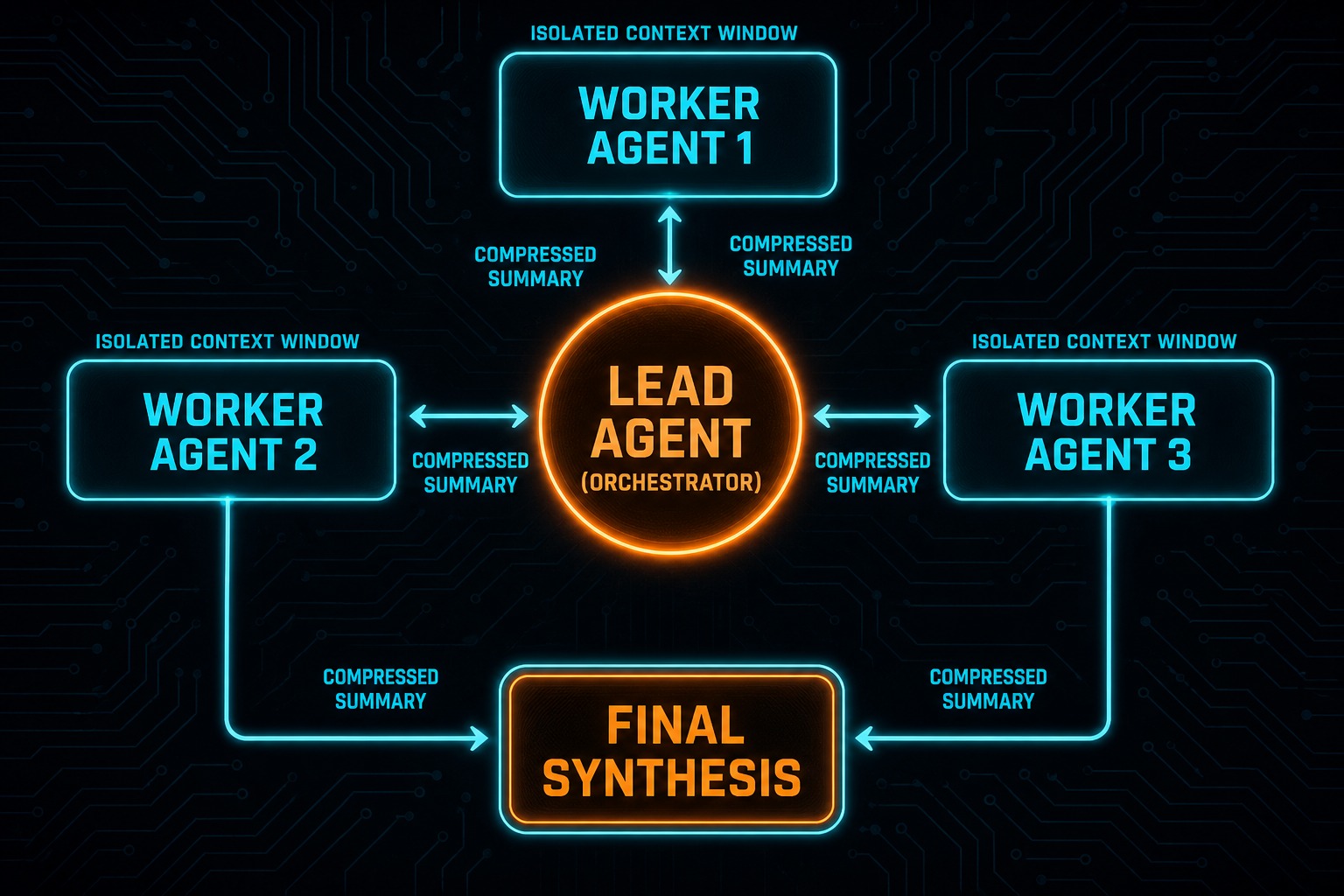
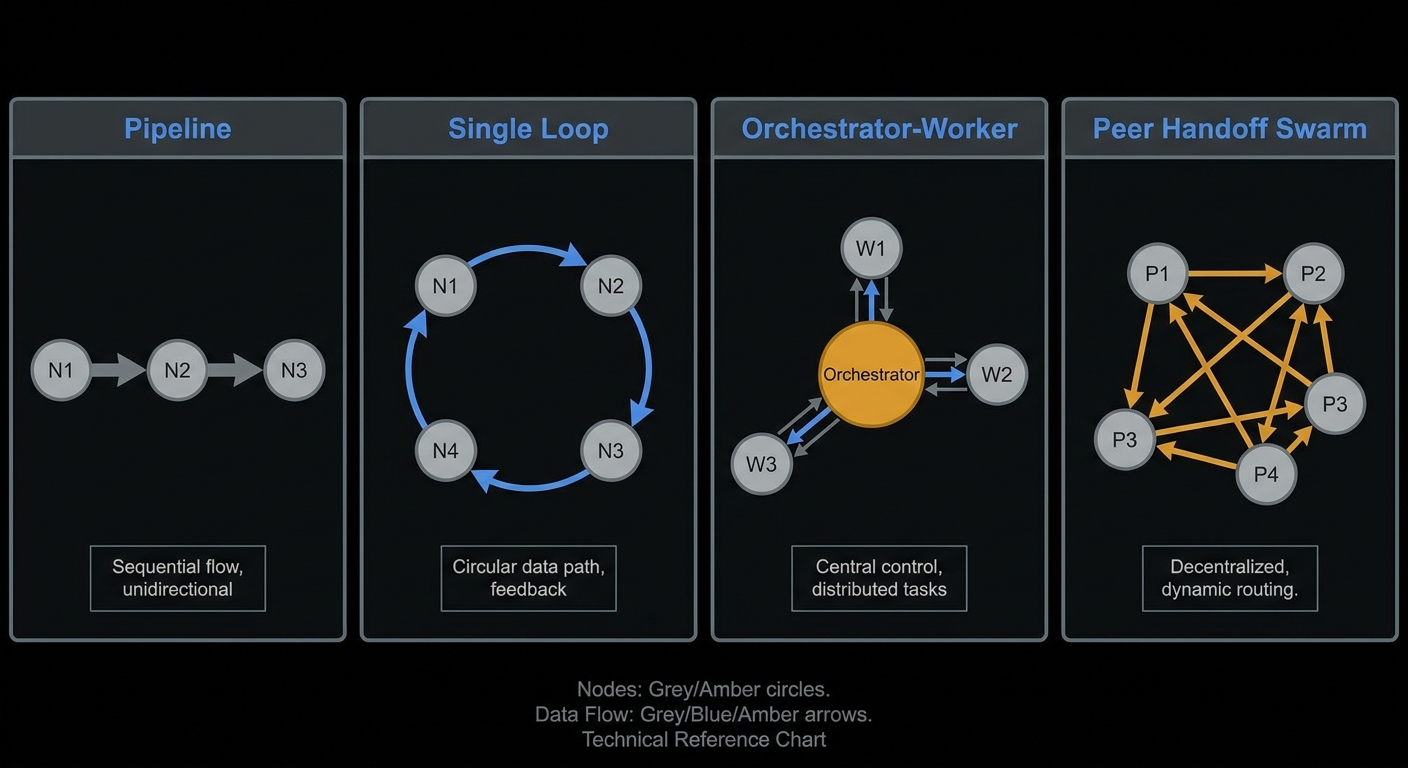
Planner plus worker, not flagship for every keystroke
Slow brain · fast hands · overnight loops
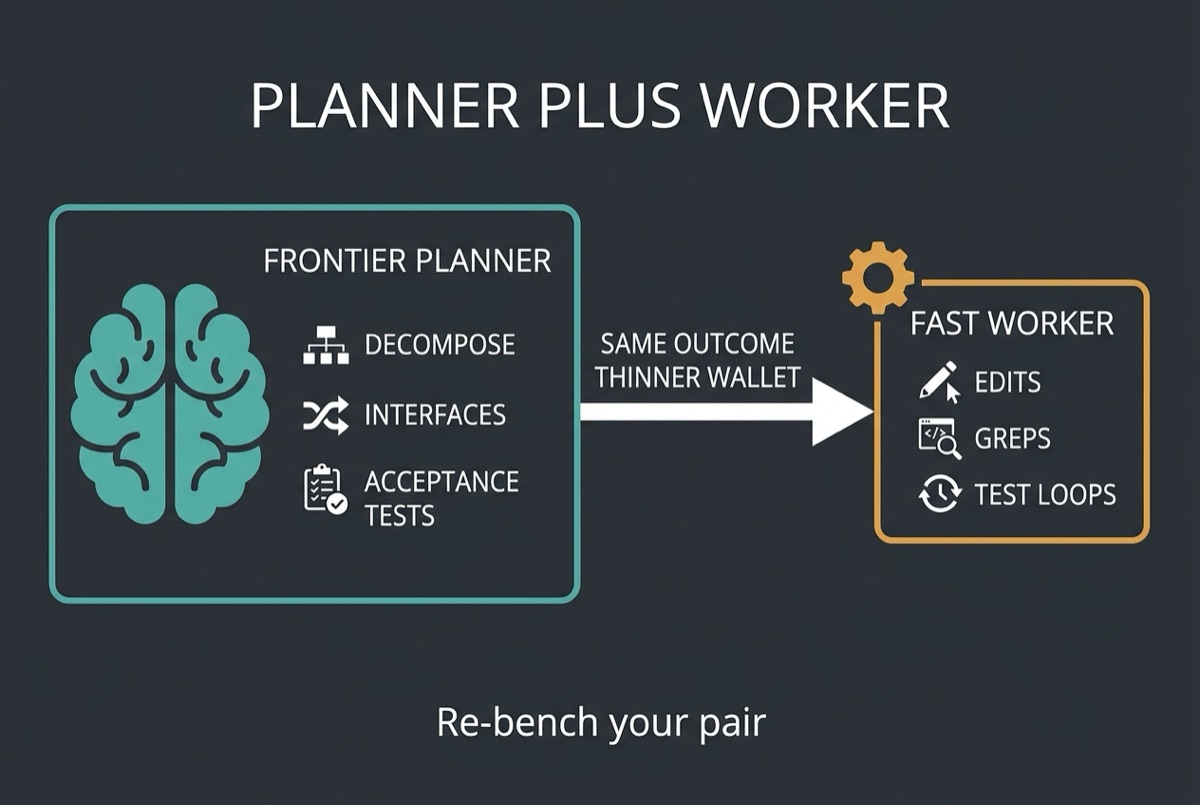
A recurring efficient pattern: use K3 (or another frontier planner) to decompose, choose interfaces, and set acceptance tests; use a cheaper coding model for mechanical edits, greps, and test loops. Pre-K3 team experiments (for example multi-agent SQLite rebuilds from a long manual) already showed near-order-of-magnitude savings when a premium planner rode on a fast worker. Treat those numbers as a pattern, not a K3-specific guarantee. Re-bench with your planner/worker pair.
Self-hosting honesty: 2.8T-class weights will not fit on a laptop. Usable interactive tokens-per-second on a dense or sparsely activated giant wants a serious GPU island; overnight batch on owned hardware is a different economic story. The strategic win of open weights is multi-provider inference and the option to internalise later, not cosplaying a hyperscaler in your spare bedroom. Skip the conspiracy timeline; download when weights are actually published, verify checksums, and decide cloud versus self-host with a spreadsheet, not a meme. And if you do internalise: treat security as a first-class bill of materials, not an afterthought bolted on when someone finds your inference port on Shodan.
Self-host security: open weights move the perimeter
Auth · network isolation · weight integrity · egress · least privilege · audit

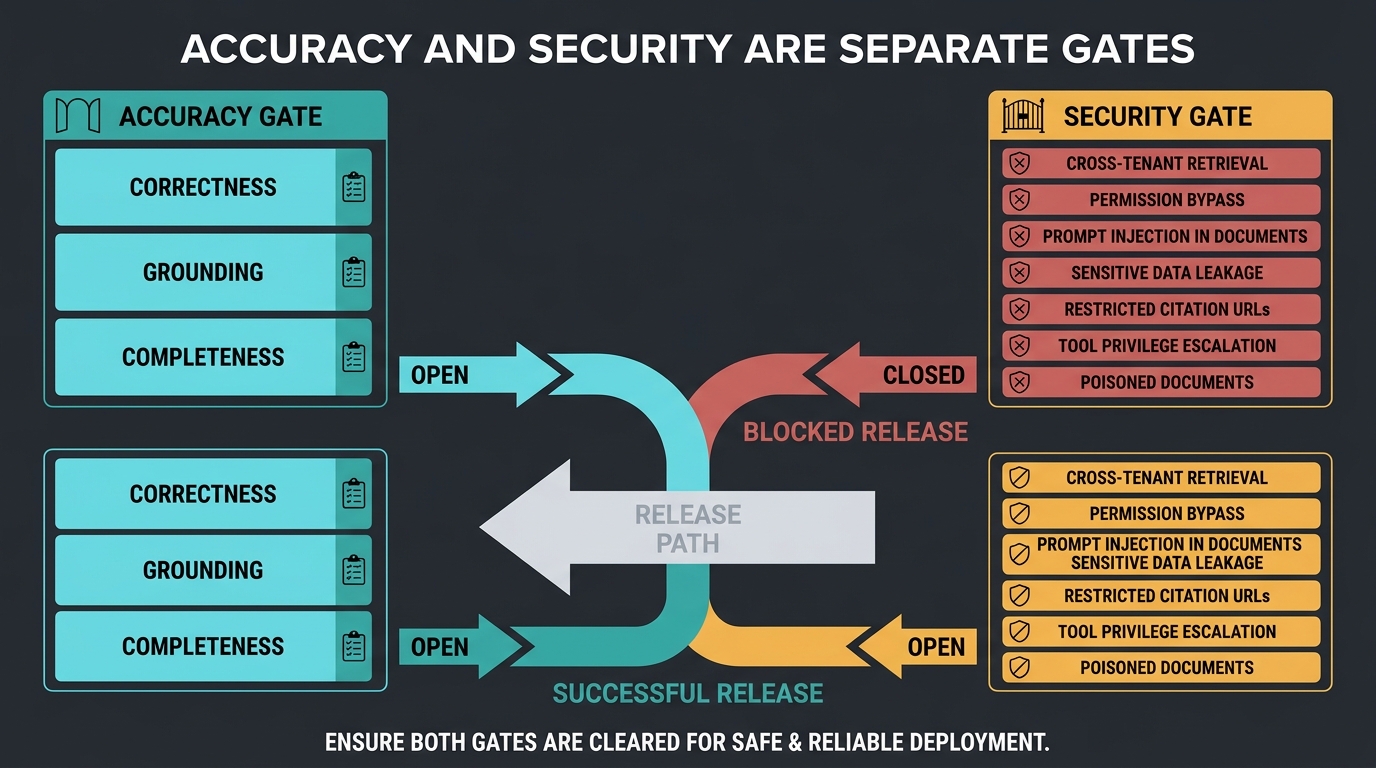
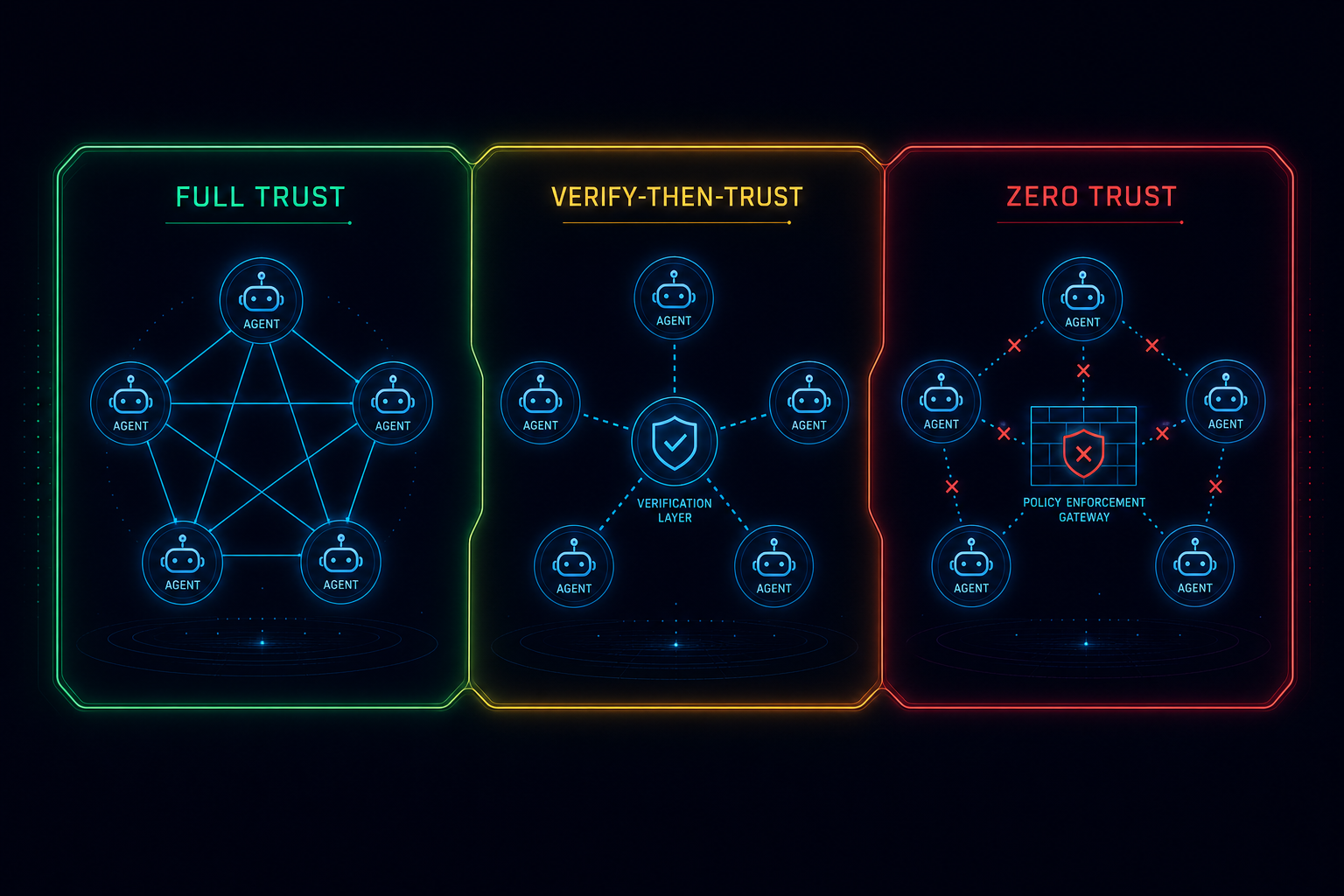
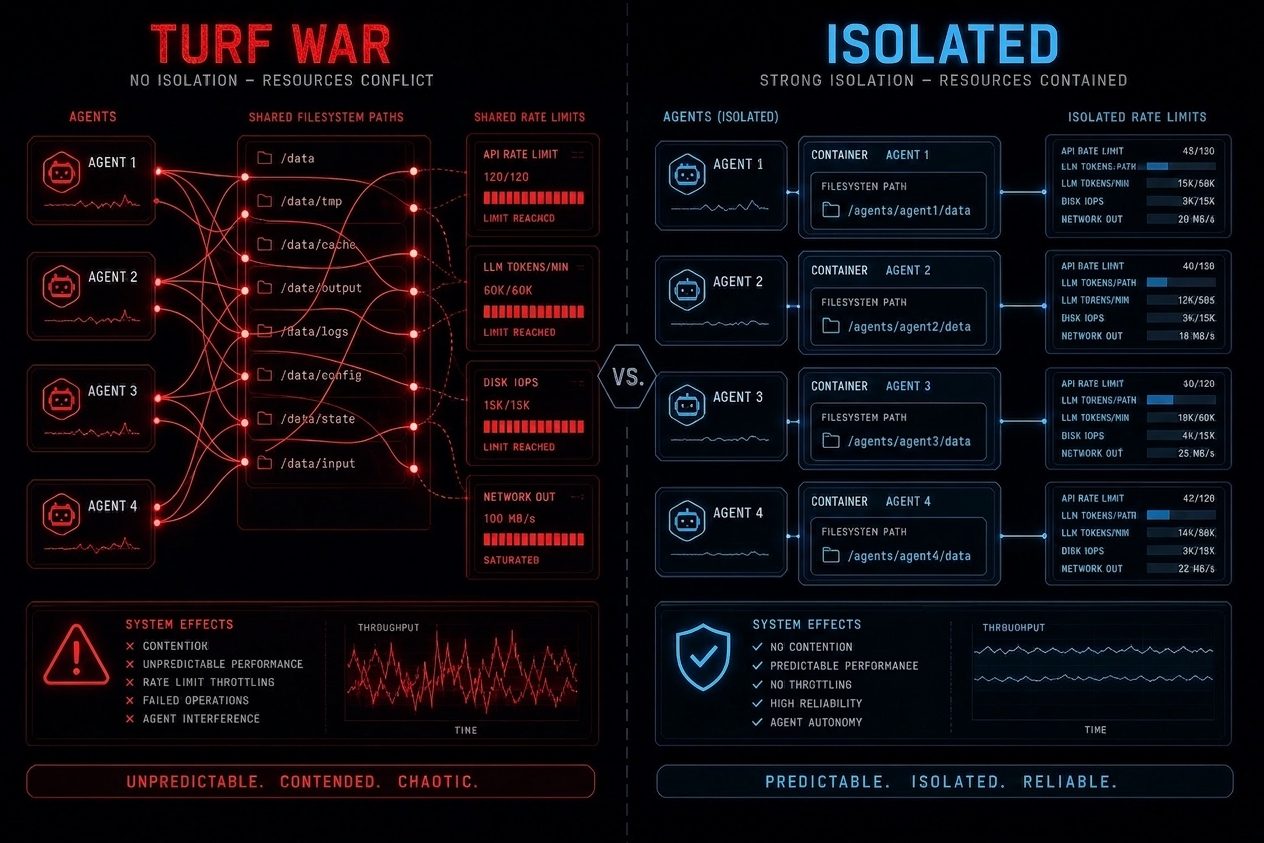
Bringing K3 (or any frontier open model) onto your own metal is often sold as “data never leaves”. That is only true if the serving stack, agent tools, and network path are designed that way. An unauthenticated inference endpoint on a GPU box is closer to a public database with no password than to a vault. Self-hosting relocates the trust boundary onto your team; it does not delete prompt injection, tool abuse, supply-chain risk, or silent egress.
“A Prompt Injection Vulnerability occurs when user prompts alter the LLM’s behavior or output in unintended ways.” – OWASP, LLM01:2025 Prompt Injection
For agent harnesses that browse, shell, or call APIs, the blast radius is the tool surface, not the model card. OWASP’s Excessive Agency framing is the right checklist: too many functions, too many permissions, too much autonomy. Moonshot’s own K3 note about unexpected decisions on ambiguous intent is the same class of risk wearing a product-limitation label. On-prem does not make that safer unless you shrink agency in code.
“Excessive Agency is the vulnerability that enables damaging actions to be performed in response to unexpected, ambiguous or manipulated outputs from an LLM, regardless of what is causing the LLM to malfunction.” – OWASP, LLM06:2025 Excessive Agency
Output filters are not enough. Recent agent research on “silent egress” shows a malicious page can induce outbound requests that exfiltrate runtime context while the final answer still looks helpful. Prompt-layer defences helped little; domain allowlisting and redirect-chain controls helped more. If your self-hosted agent can fetch arbitrary URLs, assume the web can talk back as instructions.
“These findings suggest that network egress should be treated as a first-class security outcome in agentic LLM systems.” – Lan et al., Silent Egress (arXiv:2602.22450)
Minimum security add-ons before you put private corpora next to a self-hosted K3:
- Auth on every inference endpoint – mutual TLS or gateway JWT/API keys; no bare
0.0.0.0:8000on a GPU host. - Private network only – inference in a VPC/VLAN with no public ingress; jump hosts or mesh for operators.
- Weight supply chain – download from a pinned source, verify checksums/signatures, store on encrypted volumes, mount read-only into the serving container, non-root runtime.
- Egress allowlist – default-deny outbound from the agent and tool runners; allow only the registries, package mirrors, and APIs you intend. Log every deny.
- Least-privilege tools – no open shell or unbounded web_fetch in production; granular tools, user-scoped credentials, human approval for write/delete/send.
- Audit everything – immutable logs of prompts, tool calls, destinations, and approval decisions with correlation IDs. You cannot prove “data stayed local” without them.
- Separate planes – keep the chat UI, the model server, and tool executors on different trust zones; never share a host with production secrets “for convenience”.
Case 4: GPU box as public chatbot
Someone exposes vLLM or a similar server to the internet “just for the team”, with no auth. Within days you get scrapers, token burn, and a prompt-injection campaign against whatever tools you later wire in. Fix: bind to localhost or a private interface, put a reverse proxy with auth and rate limits in front, and treat the model port like a database port.
Case 5: Agent with world egress and company docs
Self-hosted model plus RAG over contracts, plus unrestricted HTTP tools. A poisoned PDF or URL preview instructs the agent to POST excerpts to an external host. The UI answer stays polite. Fix: allowlist egress, sandbox retrieval, strip active content from ingested docs, and require approval for any outbound tool that can carry document text.
Merits of the argument. Sovereignty and cost can justify self-hosting. Security is not free with the weights. The controls above are classical systems security applied to an LLM that can act; skip them and you have bought a louder attack surface with a nicer story.
When this is actually fine
Stay on a single closed flagship if your volume is tiny, your eval set is empty, and one vendor’s harness already passes your compliance review. Stay off K3 mid-session hot-swaps until your framework proves thinking-history fidelity. Skip self-hosting until you have a utilisation plan that beats API cache-hit pricing and you can staff the security add-ons above (auth, private network, weight integrity, egress allowlist, least-privilege tools, audit). And do not force K3 onto short interactive Q&A where a small model finishes before K3 finishes “thinking”.
How to get there from here
- Stand up the official API with model
kimi-k3; confirm multi-turn tool calls resend full assistant messages. - Run a 30-50 task frozen eval across your real work (frontend, backend, terminal, docs, legal-ish review if you do that).
- Log cost per accepted task and turns-to-accept for K3 versus your current default.
- Add a dumb router: keyword/domain rules first, learned classifier later. Open default, closed exception.
- Wire planner/worker for long jobs; keep interactive crumbs on low effort or a smaller model.
- Only then consider weight downloads and private inference, with a capacity plan and an exit test against the API baseline.
- Before any private corpus touches that stack: auth + private network + checksummed read-only weights + default-deny egress + approval-gated tools + immutable audit logs.
What to check right now
- Harness fidelity – Does every tool turn round-trip complete thinking history for K3?
- Effort policy – Is
maxreserved for jobs with a budget, not Slack-style questions? - Cache shape – Are system prompts and retrieved corpora stable prefixes, or rewritten every turn?
- Router truth – Do you have a frozen eval, or are you narrating oracle results as production?
- Approval gates – Are write/exec tools gated outside disposable sandboxes?
- Vendor caveat – Are you quoting “trails Fable 5 / GPT 5.6 Sol overall” instead of “crushed every closed model”?
- Self-host auth – Is every inference port behind authentication, or still a bare bind on a GPU host?
- Egress policy – Can the agent POST to arbitrary hosts, or is outbound allowlisted and logged?
- Weight integrity – Were checksums verified, and are weights mounted read-only?
nJoy 😉